
文章圖片
文章圖片
文章圖片
隨著機器人領域的飛速發展 , 我們有一個問題不斷需要思考 , 究竟如何讓機器人像人類一樣理解世界 , 學習周圍環境的表示 。 對于機器人來說 , 究竟是需要精確的坐標 , 還是語義的物體概念 , 還是隱式的空間認識推理模型?
在本文中 , 上海交通大學、波恩大學等院校的研究團隊全面總結了當前機器人技術中常用的場景表示方法 。 這些方法包括傳統的點云、體素柵格、符號距離函數以及場景圖等傳統幾何表示方式 , 同時也涵蓋了最新的神經網絡表示技術 , 如神經輻射場、3D 高斯散布模型以及新興的 3D 基礎模型 。
雖然目前的 SLAM 與定位系統主要依賴點云、體素這類稀疏表示方式 , 但密集型場景表示方法在導航、避障等后續任務中無疑會發揮關鍵作用 。 此外 , 神經輻射場、3D 高斯散布模型以及基礎模型這類神經網絡表示技術 , 非常適合整合高層次的語義信息與基于語言的先驗知識 , 從而實現更全面的 3D 場景理解與智能體行為控制 。 本文的目標是為新手和資深研究人員提供一份有價值的參考資料 , 幫助他們探索 3D 場景表示技術的未來發展方向及其在機器人技術中的應用 。
標題:What Is The Best 3D Scene Representation for Robotics? From Geometric to Foundation Models 作者:Tianchen Deng Yue Pan Shenghai Yuan Dong Li Chen Wang Mingrui Li Long Chen Lihua Xie Danwei Wang Jingchuan Wang Javier Civera Hesheng Wang Weidong Chen 機構:Shanghai Jiao Tong University、University of Bonn、Chinese Academy of Sciences、University of Zaragoza、Nanyang Technological University 原文鏈接:https://arxiv.org/abs/2512.03422 代碼鏈接:https://github.com/dtc111111/awesomerepresentation-for-robotics
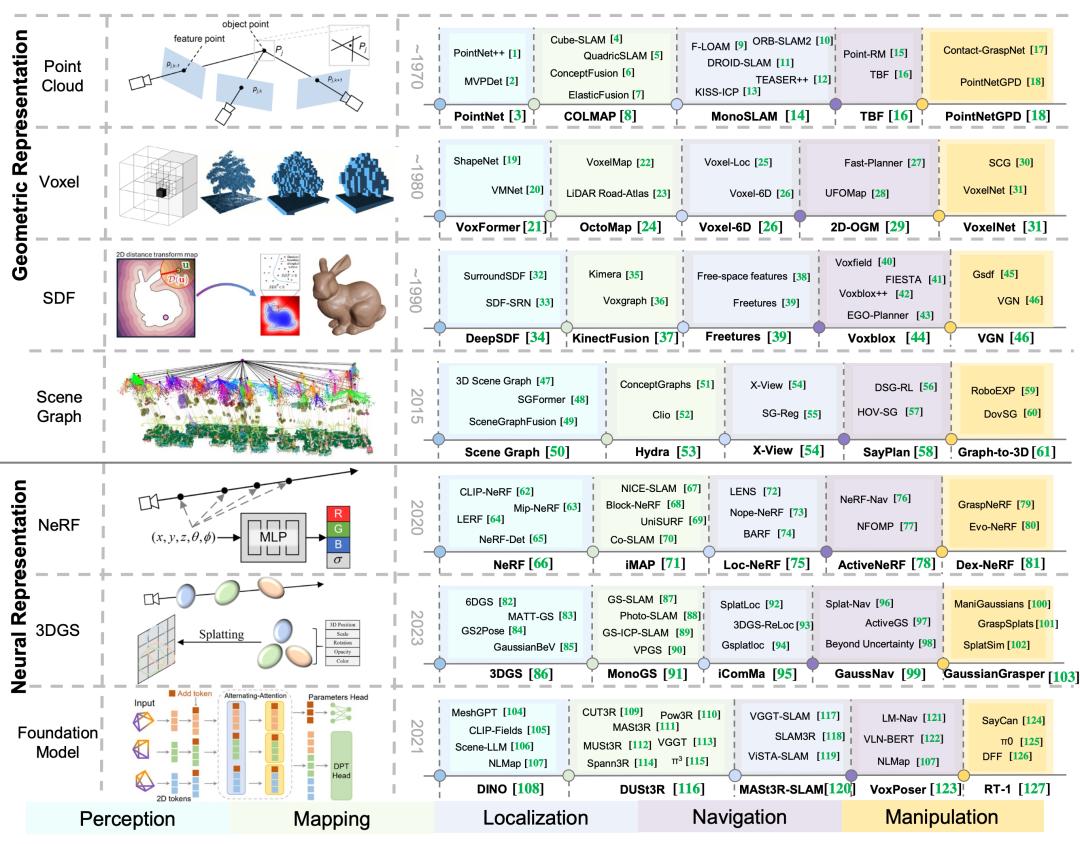
一、機器人 3D 場景發展史
機器人 3D 場景表示發展史和代表性工作
幾何場景表示:
Point Cloud 點云場景表示:通過離散的三維點來表示場景 , 通過雷達或者相機傳感器獲得 。 Voxel 體素場景表示:通過將三維空間離散化 , 轉變成規則的立方體柵格 , 通過在柵格內存儲不同的信息 , 比如密度 , 占用率等實現場景建模 Mesh 網格場景表示:通過三角化面片構建連續的場景幾何場景表示 , 精細度更高 。 SDF 符號距離?。 和ü硎究占淶愕轎鍰灞礱嫻木嗬?, 實現連續的場景幾何表示 。
近年來 , 深度學習、計算機圖形學與機器人技術的融合推動了顯著進展 。 在眾多推動這一進展的技術中 , 神經輻射?。 ∟eRF)、三維高斯濺射和基礎模型(Foundation Model , FM)作為極具前景的創新脫穎而出 , 從而實現真正的通用具身智能 。
機器人 3D 三維表征研究熱度變化
3D 神經場景表示
NeRF 神經輻射?。 和ü某【氨硎救沒魅死斫饈瀾?, 基于神經網絡 MLP 構建 , 可以進行地圖預測 , 但是速度較慢 。 3DGS 高斯潑濺:將場景表示為 3D 高斯橢球 , 從而實現高速的渲染 , 適合實時建圖 。 Foundation Model 基礎模型: 通過現有的 transformer 等編碼器 , 將三維世界壓縮成類似于語言的 token , 將三維世界的理解變成可推理的人類語言 。 從而實現空間感知推理 , 成為「3D 版本的 GPT」 。
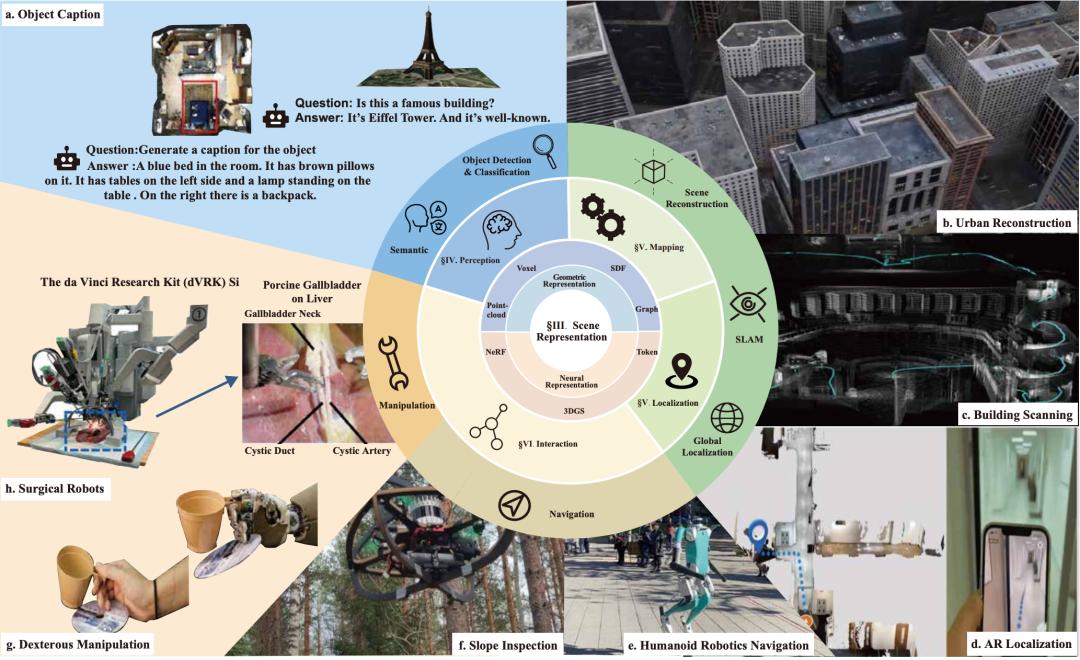
三維場景表征在機器人不同模塊的應用:感知 , 建圖 , 定位 , 操作 , 導航
在建圖和定位模塊(第 V 節)中 , 現有方法在 SLAM 和定位領域取得了令人矚目的成果 。 神經場景表示能夠實現對環境的更精確、更密集的建模 , 這對避障特別有益 。 這一能力對于機器人的導航和操作至關重要 。
該模塊分為三部分:(i)場景重建:場景表示的地圖重建能力包括幾何精度和渲染質量 , 以及在靜態場景、大規模戶外場景和動態場景中的重建能力 。 (iii)SLAM:SLAM 部分主要包括不同場景表示方法在 SLAM 過程中的地圖精度、位姿精度和實時性能 。 (iv)全局定位:全局定位主要涉及使用現有地圖進行定位時的精度和實時性能 。
在操作模塊(第 VI-A 節)中 , 本文主要比較了基于不同場景表示方法的抓取框架 。 傳統方法在抓取方面具有更高的實時性能和計算效率 , 但在泛化能力和處理復雜目標操作任務方面存在局限 。 相比之下 , 基于神經網絡的場景表示在生成新視角和跨多個場景泛化方面具有一定能力 , 使其更能適應復雜任務 。 基于基礎模型的方法能夠實現零樣本抓取任務 , 具備強大的泛化能力 。 此外 , 語言信息的集成使這些模型能夠支持交互式抓取 , 并增強了它們理解和規劃高級認知任務的能力 。
在導航模塊(第 VI 節)中 , 與傳統的場景表示方法相比 , 神經場景表示能夠提供高度準確的環境重建 。 此外 , 它們還有助于更好地融合語義和語言信息 , 從而能夠執行更復雜的導航任務 。 我們將導航模塊分為兩個部分:(i)規劃:從當前位置到目標目的地生成最優或可行路徑 , 同時避開障礙物 。 (ii)探索:主動導航并繪制先前未知區域的地圖 。
不同 3D 場景表示的特點對比 , 包含連續性 , 存儲效率 , 真實性 , 靈活性 , 幾何表示精度 。
二、現有方法的問題與未來發展方向
1、端到端通用網絡還是模塊化?
目前 , 大多數機器人系統都建立在模塊化智能(Modular Intelligence)的基礎上 。 為了完成復雜任務 , 系統會將導航或操作等功能分解為獨立的模塊 , 例如感知、建圖、定位、操作和導航 。 這種設計雖然有助于實現各種機器人功能 , 但其模塊化特性在本質上可能會限制機器人智能的進一步發展 。
盡管模塊化解決方案引入了有用的歸納偏置(Inductive Biases)并支持有效的特定任務性能 , 但它們通常面臨泛化能力有限和遷移性差的問題 。 在實際應用中 , 這些系統往往需要在不同場景下進行重復的傳感器校準、特定環境建模以及參數重新調優 。 此外 , 在高度復雜的環境中 , 構建精確的模型仍然極具挑戰性 。 基礎模型的最新進展提供了一條替代路徑 , 即實現端到端智能 。
2、數據瓶頸
盡管神經場景表示(Neural Scene Representations)在準確性和泛化性方面具有顯著優勢 , 但一個主要的挑戰在于 , 與訓練大語言模型(LLM)和視覺語言模型(VLM)所使用的互聯網規模的文本與圖像語料庫相比 , 機器人特有的數據非常匱乏 。 這種局限性顯著阻礙了機器人領域神經場景表示和基礎模型的發展 。
為了解決這一問題 , 研究重點已轉向增強神經場景表示在有限數據情況下的泛化能力 。 另一個方向則是利用世界模型(World Models)來預測以動作為條件的(Conditioned on actions)狀態轉移 , 從而生成額外的訓練數據集 。
3、實時性瓶頸
與傳統的場景表示相比 , 在機器人領域部署神經場景表示的另一個關鍵瓶頸在于其推理時間(Inference Time) , 這仍是制約可靠實時應用的一個限制因素 。 目前神經網絡的部署策略通常分為兩大類:
第一類是基于云端的部署 。 通常托管在遠程數據中心 , 并通過 API 進行訪問 。 在這種模式下 , 響應延遲和服務時間很大程度上取決于底層的網絡路由、帶寬以及數據中心的計算能力 。 因此 , 在將此類模型集成到自主機器人技術棧之前 , 必須仔細權衡網絡的可靠性和延遲問題 。
第二類是邊緣計算平臺上的車載 / 機載部署(Onboard Deployment) 。 此類方案通常采用模型蒸餾(Model Distillation)和量化(Quantization)等技術來減小模型體積 , 從而實現實時推理 。 然而 , 這往往以犧牲泛化能力為代價 。 一個極具前景的未來方向在于硬件 - 算法協同設計(Hardware–Algorithm Co-design) , 旨在同時提高推理效率并保持模型的泛化性能 , 以滿足機器人實時部署的需求 。
本文探討了機器人不同模塊最適合的三維場景表示方法 , 研究了相關方法、并討論了挑戰和未來方向 。 本文的主要貢獻如下:
全面、最新的綜述與基準測試:本文對機器人領域的不同場景表示方法進行了廣泛且最新的綜述 , 涵蓋了經典方法和前沿方法 。 對于每個模塊 , 團隊都提供了詳細介紹 , 并突出了該模塊中不同場景表示的優勢 。 三維場景表示的未來方向:在機器人領域的每個模塊中 , 團隊指出了當前研究的技術局限性 , 并提出了幾個有前景的未來研究方向 , 旨在激勵這一快速發展領域的進一步進步 。 開源項目:團隊在 GitHub 上發布了一個開源項目 , 整理了機器人領域不同場景表示的相關文章 , 并將繼續向該項目添加新的研究成果和技術 , 網址為 https://github.com/dtc111111/awesome-representation-for-robotics 。 團隊希望更多研究人員能夠利用它獲取最新的研究信息 。
【一文速通「機器人3D場景表示」發展史】對更多實驗結果和文章細節感興趣的讀者 , 可以閱讀一下論文原文~
推薦閱讀














- 飛書聯手安克造了顆AI豆,你的「外腦」僅重 10 克
- 蘋果入局AI Pin,或對標OpenAI,能否打破「電子垃圾」魔咒?
- 中國團隊一夜封神,AI出海「全球第一」!曾靠游戲狂賺10億美金
- 百川啟動「海納百川」計劃,新推出的最低幻覺醫療大模型M3 Plus免費開放
- 一文看懂蘋果新春優惠:最高1000元的羊毛值得薅嗎?
- 富士造出了今年「最好玩」的相機,但我勸你別買
- 1599元才是手機「真諦」?淺談2026年省錢秘密,通俗易懂
- 你的手機為什么充電慢,一文帶你了解手機到底有多少充電協議
- 黃仁勛將存儲定義為「AI運行內存」,基礎設施該如何實現物種進化
- 殺入硅谷腹地,MOVA 想在美國庭院發起一場「革命」