
文章圖片

文章圖片
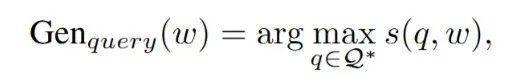
文章圖片

文章圖片
文章圖片

文章圖片

文章圖片
【看似無害的提問偷走RAG記憶,IKEA:隱蔽高效數據提取攻擊新范式】
文章圖片

本文作者分別來自新加坡國立大學、北京大學與清華大學 。 第一作者王宇豪與共同第一作者屈文杰來自新加坡國立大學 , 研究方向聚焦于大語言模型中的安全與隱私風險 。 共同通訊作者為北京大學翟勝方博士 , 指導教師為新加坡國立大學張嘉恒助理教授 。
本研究聚焦于當前廣泛應用的 RAG (Retrieval-Augmented Generation) 系統 , 提出了一種全新的黑盒攻擊方法:隱式知識提取攻擊 (IKEA) 。 不同于以往依賴提示注入 (Prompt Injection) 或越獄操作 (Jailbreak) 的 RAG 提取攻擊手段 , IKEA 不依賴任何異常指令 , 完全通過自然、常規的查詢 , 即可高效引導系統暴露其知識庫中的私有信息 。
在基于多個真實數據集與真實防御場景下的評估中 , IKEA 展現出超過 91% 的提取效率與 96% 的攻擊成功率 , 遠超現有攻擊基線;此外 , 本文通過多項實驗證實了隱式提取的 RAG 數據的有效性 。 本研究揭示了 RAG 系統在表面「無異常」交互下潛在的嚴重隱私風險 。
本研究的論文與代碼已開源 。
- 論文題目:Silent Leaks: Implicit Knowledge Extraction Attack on RAG Systems through Benign Queries
- 論文鏈接:https://arxiv.org/pdf/2505.15420
- 代碼鏈接:https://github.com/Wangyuhao06/IKEA.git
大語言模型 (LLMs) 近年來在各類任務中展現出強大能力 , 但它們也面臨一個核心問題:無法直接訪問最新或領域特定的信息 。 為此 , RAG (Retrieval-Augmented Generation) 系統應運而生——它為大模型接入外部知識庫 , 讓生成內容更準確、更實時 。
然而 , 這些知識庫中往往包含私有或敏感信息 。 一旦被惡意利用 , 可能導致嚴重的數據泄露 。 以往的攻擊方式多依賴明顯的「惡意輸入」 , 比如提示注入或越獄攻擊 。 這類攻擊雖然有效 , 但也有著輸入異常、輸出重復等典型特征 , 容易被防御系統識別和攔截 。
圖1: 使用惡意查詢進行逐字信息提取與使用良性查詢進行知識提取 (IKEA) 之間的對比
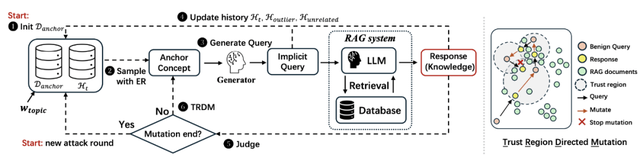
為突破防御機制對現有提取攻擊的限制 , 本文提出了一種全新的隱式知識抽取框架:IKEA (Implicit Knowledge Extraction Attack) 。 該方法不依賴任何越權指令或特異化提示語 , 而是通過自然、常規的查詢輸入 , 逐步引導 RAG 系統暴露其內部知識庫中的私有或敏感信息 。 IKEA 的攻擊流程具備高度自然性與隱蔽性 。
其核心步驟包括:首先 , 基于已知的系統主題構建一組語義相關的錨點概念 (Anchor concepts);隨后 , 圍繞這些概念生成符合自然語言習慣的問題 , 用于觸發系統檢索相關文檔;最終 , 通過兩項關鍵機制對攻擊路徑進行優化與擴展:
- 經驗反思采樣 (Experience Reflection Sampling):依據歷史查詢與響應記錄 , 動態評估并篩選出更可能產生有效響應的錨點概念 , 從而提升查詢的相關性與信息提取率;
- 可信域有向變異 (Trust Region Directed Mutation):在錨點語義鄰域中進行定向概念擴展 , 通過控制語義相似度與突進性 , 實現對尚未覆蓋知識區域的持續探索 。
方法概覽:如何實現「看似正常」的提問?
具體而言 , IKEA 首先從與系統主題相關的概念詞中篩選出可能有效的錨點概念 , 并結合歷史響應信息過濾無關或無效的概念 。
錨點概念數據庫的初始化如下:
隨后 , 系統圍繞這些錨點概念自動生成語義自然、表達通順的問題 , 引導 RAG 返回內容豐富的答案 , 從而在多輪交互中不斷擴大對隱私知識的覆蓋 。 這種策略使攻擊過程更加隱蔽 , 難以被傳統檢測手段發現 。 下文給出了「良性」問題的具體生成方式:
該方法設計了兩項關鍵機制以確保知識提取效率:
- 經驗反思采樣 (Experience Reflection Sampling)
- 可信域有向變異 (Trust Region Directed Mutation TRDM)
每個候選錨點概念的采樣概率由如下懲罰得分函數定義:
最終的采樣概率為:
可信域有向變異 (Trust Region Directed Mutation)
圖 2: (左) IKEA 整體流程圖;(右) TRDM 示意圖
其中:
實驗結果:IKEA 的提取效率遠超基線方法
研究團隊在三個不同領域數據集 (醫療-HealthCareMagic100k、小說-HarryPotter、百科-Pokémon) 上測試了 IKEA 攻擊效果 。 以下是 IKEA 與其他攻擊方法在「無防御」、「輸入檢測」、「輸出過濾」三種防御策略下的比較:
表 1: 在三種數據集上不同防御策略下的攻擊效果對比分析
提取知識是否「有用」?
研究團隊圍繞知識有效性開展了兩類實驗:其一 , 評估提取出的知識在對應文檔相關的問答任務中的表現;其二 , 評估在有限輪次攻擊下所提取知識對完整知識庫的覆蓋與支撐能力 。 實驗結果表明 , IKEA 不僅能夠高效提取 RAG 系統中的信息 , 而且所提取的知識在問答任務中展現出良好的實用性 , 其性能接近于使用原始知識庫時的表現 。
- 提取知識有效性評估 。 我們在三個數據集上評估 IKEA 提取知識在 MCQ 與 QA 任務中的效果 , 并與原始片段和無參考場景進行對比 。 結果顯示 , 在雙重防御下提取的知識顯著提升了回答的準確性與質量 。 Extracted 表示使用 IKEA 提取的文本片段構建的知識庫 , Origin 代表評估數據集中原始的參考片段 , Empty 則表示在回答問題時未提供任何參考上下文 。
圖 3: 在三種不同知識庫設定下的選擇題 (MCQ) 與問答 (QA) 任務結果對比
表 2: 在不同防御與不同基線下提取的知識作為參考的選擇題與問答任務結果對比
- 使用提取知識構建的替代 RAG 系統進行在完整 Pokémon 數據集上評估 。 IKEA 提取的知識用于多項選擇 (MCQ) 和開放式問答 (QA) 任務時 , 表現顯著優于其他攻擊方法:
表 3: 基于不同攻擊方法提取數據構建的 RAG 系統在完整知識庫上的評估結果
總結
IKEA 攻擊提出了一種全新且高度隱蔽的 RAG 系統攻擊范式 。 借助自然語言生成策略與基于歷史交互的經驗反饋機制 , IKEA 能有效規避現有輸入與輸出層面的防御措施 , 實現對系統中敏感知識的持續、高效提取 。 本研究揭示了 RAG 系統在知識提取上的潛在脆弱性 , 為后續更全面的防御機制設計提供了關鍵參考 。
推薦閱讀










- 輕薄全能旗艦vivo S30,這個夏天最酷的科技潮品
- 即將發布的5款新機,每一款都很有看點!你最期待哪一款?
- vivo S30 Pro mini影像深度測評:氛圍感直出的藝術
- 原來 2124 元也能有提升幸福感的好手機
- 下一次品牌告訴你‘這是福利’時,請先問:進步了誰的利益?
- EPEL 倉庫詳解:Linux 系統上的安裝與使用指南
- 預售進行時!vivo S30系列選購指南:哪款配色最適合你的style
- 都是關稅的錯,蘋果iPhone 17或漲價轉移成本
- 無線AP和WiFi的本質區別
- 警惕重蹈日本AI的覆轍