
文章圖片
文章圖片

文章圖片
允中 發自 凹非寺
量子位 | 公眾號 QbitAI
國產自研開源模型 , 讓模型不用在快思考和慢思考間二選一了!
華為最新發布openPangu-Embedded-7B-v1.1 , 參數只有7B , 卻身懷雙重“思維引擎” 。
要知道 , 長期以來 , 大模型快思考與慢思考模式不可兼得 , 這成為業界的一大痛點 。 在當前大模型混戰中 , 各家巨頭都在尋求破局之道 , 但此前開源領域一直缺乏一款可自由切換快慢思維模式的模型 。
要快 , 還是要慢?AI在面對不同難度的問題時也有“選擇困難癥” 。
而現在 , openPangu-Embedded-7B-v1.1 , 通過漸進式微調策略和獨特的快慢思考自適應模式 , 既支持手動切換“快思考”或“慢思考”模式 , 也能根據問題難度自動在兩種思維模式間無縫轉換 。
簡單問題它秒答如飛 , 復雜任務它深思熟慮 , 一舉填補了開源大模型在這一能力上的空白 , 讓效率與準確率實現雙贏 。
在通用、數學、代碼等多個權威評測中 , 該模型精度相較于此前模型大幅提升 , 且引入模式自動切換并沒有犧牲精度 。 在CMMLU等基準中 , openPangu-Embedded-7B-v1.1保持精度的同時 , 平均思維鏈長度縮短近50% 。
模型現已在GitCode開源 。
所以 , openPangu-Embedded-7B-v1.1究竟是如何做到的?華為盤古團隊在模型訓練策略上又有哪些創新?
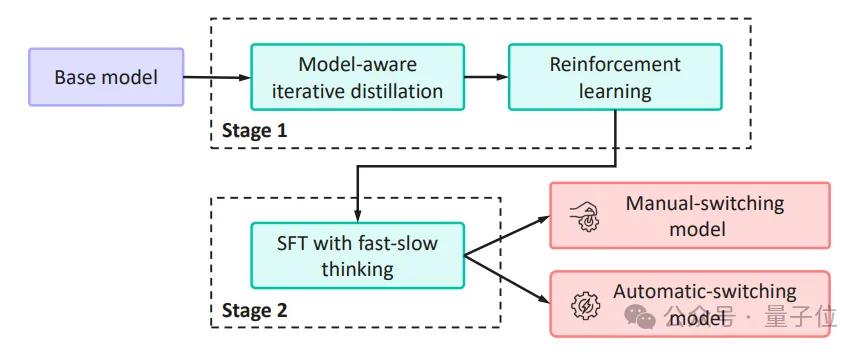
漸進式微調策略:像人一樣“進階”學習眾所周知 , 大模型往往需要海量訓練才能具備強大的推理能力 。 然而 , openPangu團隊并未采取一味“填鴨式”的訓練方式 , 而是采用了一種漸進式微調(SFT , Iterative Distillation)策略 , 模擬人類逐步進階的學習過程 。
通過精心設計的迭代訓練 , 讓模型在每一步都處于“適度挑戰”的學習區間 , 能力穩步提升 。
具體來說 , 團隊將漸進式微調劃分為三個循序漸進的階段 , 每一步都讓模型獲得針對性的提升:
第一步:合理選題 , 保持適度挑戰
在每一輪訓練迭代中 , 模型會根據自身當前能力對候選訓練樣本進行難度評分 , 優先挑選難度適中、不偏易也不偏難的題目來訓練 。 這樣確保模型始終在與能力相匹配的挑戰中學習 , 既不會因過于簡單停滯不前 , 也不會因過難而無法收獲 , 步步為營拓展能力邊界 。
第二步:歸納總結 , 穩固已有知識
完成一輪訓練后 , 產生的多個模型版本(不同檢查點)不會簡單取舍 , 而是通過參數增量融合(inter-iteration merging)合并成統一的模型 。 這一步相當于將新學到的知識與原有能力進行“匯總融合” , 讓模型的認知更加穩固 , 避免遺忘過去學到的本領 。
第三步:持續提升 , 擴展能力邊界
隨著上述循環不斷進行 , 模型積累的知識與技能越來越豐富 , 自身能力水漲船高 , 能夠勝任更復雜的數據訓練 。 這時 , 它進入了更高水平的“拉伸區” , 可以挑戰此前無法解答的難題 。 模型能力的提升又反過來推動下一輪更高難度的數據選擇 , 形成一個不斷進化的良性循環 。
通過這樣的漸進式訓練方式 , openPangu-Embedded-7B-v1.1不再是被動接受知識的“填鴨式”學習者 , 而是化身為一個能夠持續進化的學習者 。 實驗結果表明 , 這一策略讓模型的推理過程更加穩定 , 泛化表現更加強勁 。
快慢自適應機制:兩階段課程 , 從“手動擋”進階“自動擋”相比之前開源的openPangu-Embedded-7B-v1 , 此次開源的openPangu-Embedded-7B-v1.1模型最大的亮點 , 就是引入了獨特的快慢思考自適應模式 , 使得模型可以自動根據任務難度選擇使用快思考還是慢思考進行解答 。
相比4月先行披露的技術報告 , 團隊的快慢思考切換訓練方案進行了大幅升級 , 不但從方案上演進為了數據質量驅動的學習策略 , 快慢思考切換的范圍也從數學任務擴展到了一般任務 。
第一階段:教會模型區分快慢 。
在這個“低難度課程”階段 , 研究團隊首先通過數據構造 , 讓模型明確什么是“快思考”、什么是“慢思考” 。
他們精心構建了一個混合訓練數據集:在用戶提問(Prompt)中附加特殊的標識符 , 直接告訴模型該用快思考還是慢思考來回答 。 通過在這個帶有明確指示信號的數據上訓練 , 模型學會將特定輸入模式與對應的思維方式、回答風格建立關聯 。
可以說 , 這一步猶如給模型裝上“手動變速箱” , 明確劃定了兩種思考模式的界限 , 是一堂扎實的“熱身課” , 確保模型具備基本的快慢思維切換意識 。
第二階段:自主學會切換 。
當模型已經掌握了顯式控制的本領后 , 就進入更具挑戰性的“進階課程” 。 這一階段不再提供外部快/慢提示 , 而是要求模型根據問題本身自行判斷何時該快、何時該慢 。
從簡單樣本過渡到復雜樣本 , 團隊設計了一套數據質量驅動的自優化訓練策略:先用第一階段訓練好的模型作為“教練” , 為同一問題生成多樣化的解答鏈路 , 然后從中挑選質量最高的解答 , 再以這些優質解答來有選擇地微調模型 。
通過這種“從優錄取”的訓練方式 , 模型逐漸學會了從復雜問題中自主推斷最優思考路徑 , 無需明確指令就能自動在快/慢模式間切換 。 可以說 , 這一步為模型裝上了智能“自動變速箱”——它告別了對外部指令的依賴 , 實現了內在驅動的決策 。 這一階段的訓練難度顯著高于第一階段 , 因為模型需要領悟更深層的隱含邏輯 , 而不再是簡單遵循提示符號 。
經過兩個階段環環相扣的“課程學習” , openPangu-Embedded-7B-v1.1完成了從外部信號驅動的顯式切換到內部能力驅動的隱式切換的蛻變 , 大幅提升了模型在復雜推理任務中的靈活性與自主性 。
最終 , 經過這一套訓練流程 , 新模型成功解鎖了快慢思考模式的雙模式切換——既支持用戶手動指定思考模式 , 也能在無需人為干預下自動選擇最合適的推理方式 。
快慢自適應減少簡單任務Token量三到五成如此復雜的訓練設計 , 最終效果如何?openPangu-Embedded-7B-v1.1在多個權威評測上交出了令人欣喜的答卷 。
首先是精度的大幅提升 。 相較前代模型v1版本 , 新模型在通用、數學、代碼等各類數據集上全面超越了自己過去的成績 。 其中在最棘手的數學難題數據集(如AIME挑戰)上 , v1.1版本取得了遠超v1的領先表現 。
更難得的是 , 在采用自適應快慢思考模式下 , 新模型在復雜任務上的準確率依然保持與純“慢思考”情況下幾乎相同的水準 , 即引入自動切換并沒有犧牲精度 。
其次在響應效率上 , 成果同樣令人眼前一亮 。 對于簡單問題 , openPangu-Embedded-7B-v1.1能夠自動切換為快思考模式 , 大幅縮短不必要的冗長推理過程 。
在某些基準測試中(例如中文綜合知識測試集CMMLU) , 新模型在保持精度基本不變的前提下 , 將平均輸出的思維鏈長度減少了近50%!也就是說 , 同一道簡單題 , 它給出的解釋步驟幾乎縮短了一半 , 直接帶來響應效率的翻倍提升 。
與此同時 , 對于諸如AIME、LiveCodeBench這類復雜度極高的難題 , 模型依然會老老實實“慢思考”、給出詳盡的逐步推理 , 從而確保精度與只用慢思考模型相當 。 簡單題不啰嗦、難題不放棄 , 這種智能切換讓模型在速度和精度之間取得了很好的平衡 。
邊緣AI部署利器:1B小模型性能拉滿值得驚喜的是 , openPangu系列近期不僅升級了7B模型 , 還推出了一款專為邊緣AI部署優化的輕量級模型——openPangu-Embedded-1B 。
顧名思義 , 它只有十億參數 , 但卻通過多項技術加持 , 實現了“小體量也有大能量” 。
在軟硬件協同設計方面 , openPangu-Embedded-1B針對華為昇騰端側AI硬件進行了架構優化 , 充分利用芯片特性 , 大幅降低推理延遲、提升資源利用率 。
與此同時 , 華為團隊采用多階段訓練策略(包括從零開始的預訓練、多樣化數據的課程式微調、離線同策略知識蒸餾以及多源獎勵的強化學習等) , 全面挖掘模型潛力 , 顯著增強了模型在各類任務上的表現 。
得益于以上創新 , 這款僅10億參數的小模型取得了性能與效率的高度協同 , 在多個權威評測中成績亮眼 。
據公開數據顯示 , openPangu-Embedded-1B創下了國內1B級模型的新標桿 , 其整體平均成績不僅全面領先其他同規模模型 , 甚至追平了更大參數模型Qwen3-1.7B的水平 。
這充分體現了出色的參數級性能比:用更小的模型實現了媲美大模型的效果 , 為國產自研大模型在資源受限場景下的探索提供了新的方向 。
綜上 , 華為 openPangu-Embedded-7B-v1.1 的發布為當前熱度較高的大模型領域帶來了不一樣的思路 。 作為參數規模為 7B 的輕量級模型 , 它通過漸進式微調和雙階段訓練方法 , 實現了快慢思考模式的自由切換 , 在效率與精度之間找到了較好的平衡點 。
無論是面向邊緣部署需求的小模型 , 還是追求復雜推理能力的通用模型 , 盤古系列的持續演進都展現出國產大模型的創新活力 。
未來 , 這一具備“快慢思考”特性的模型 , 有望在更多實際應用場景中發揮價值 。
項目已在GitCode開源:https://gitcode.com/ascend-tribe/openpangu-embedded-7b-v1.1
— 完 —
量子位 QbitAI · 頭條號簽約
【快慢思考不用二選一!華為開源7B模型自由切,精度不變思維鏈減半】關注我們 , 第一時間獲知前沿科技動態
推薦閱讀










- 25歲創造百億美金神話,爆款AI工具1年ARR破億,他講出背后失敗與思考
- 9月8日全新首發!華為WiFi 7+重構信號世界,用戶再也不用蹭網角落蹲!
- 會「思考」!字節跳動發布OmniHuman-1.5,讓虛擬人擁有邏輯靈魂
- 裝機選購不用愁!技嘉B850M電競雕輕松駕馭9000系處理器
- 小米首款三區洗衣機官宣:自帶三筒 襪子、內衣不用手洗了
- DeepSeek、GPT-5都在嘗試的快慢思考切換,有了更智能版本
- 目前值得撿漏的蘋果手機,從5999元跌至3999元,不用等新機了
- 手機不用買太貴,這款“全能手機”出現大跳水,低價有旗艦體驗
- 周末逃離計劃:“小藝看世界”邊看邊聊邊思考,帶我深度游古鎮
- 相機控制鍵淘汰?iPhone 17不用搶了