
文章圖片

文章圖片

文章圖片
文章圖片
文章圖片
文章圖片
文章圖片
文章圖片
【讓機器人「不只是走路」,Nav-R1引領帶推理的導航新時代】
在機器人與智能體領域 , 一個長期的挑戰是:當你給機器人一個「去客廳把沙發上的書拿來」或者「沿著樓道走到門口 , 再右轉」這一類指令時 , 機器人能不能不僅「看見環境」 , 還能「理解指令」、「規劃路徑」、然后「準確執行動作」?
之前的許多方法表面上看起來也能完成導航任務 , 但它們往往有這樣的問題:推理(reasoning)的過程不夠連貫、不夠穩定;真實環境中路徑規劃與即時控制之間難以兼顧;在新的環境里泛化能力弱等 。
Nav-R1 出?。 菏裁詞?Nav-R1?
論文標題:Nav-R1: Reasoning and Navigation in Embodied Scenes 論文地址:https://arxiv.org/pdf/2509.10884
這篇題為《Nav-R1: Reasoning and Navigation in Embodied Scenes》的新論文 , 提出了一個新的「身體體現式(embodied)基礎模型」(foundation model) , 旨在讓機器人或智能體在 3D 環境中能夠更好地結合「感知 + 推理 + 行動」 。 簡單說 , 它不僅「看到 + 聽到+開動馬達」 , 還加入清晰的中間「思考」環節 。
核心創新
1.Nav-CoT-110K:推理軌跡的冷啟動(cold-start)基礎
作者構造了一個大規模的數據集 Nav-CoT-110K , 包含約 11 萬(110K)條 Chain-of-Thought(推理鏈 / 思考鏈、CoT)軌跡 。 每條軌跡里不僅有任務描述(導航指令) , 還有機器人從環境中看到的 egocentric 視覺輸入 (「我從這里看到了墻、看到了桌子、右邊是沙發…」 等) , 以及每一步可能的行動選項 , 再加上明確格式化的思考與動作輸出 。
這些軌跡用于冷啟動訓練(即監督訓練階段) , 使模型「先學會怎么思考 + 怎么根據環境和指令決定動作」 , 在進入強化學習 (RL) 優化之前就已有了一個較為穩定的推理與行動基礎 。
2.三種獎勵(rewards):格式、理解、路徑
在強化學習階段 , Nav-R1 不只是簡單地獎勵「到達目的地」 , 它引入了三種互補的獎勵機制 , 使得行為更精準、更有邏輯、更符合人類期待:
Format Reward(格式獎勵):確保模型輸出遵守結構化格式 , 比如有think…/think和action…/action或answer等標簽的分明區分 , 這樣既便于機器解析 , 也讓內在推理清晰 。 Understanding Reward(理解獎勵):鼓勵模型不僅「走到目標」 , 還要能語義上理解環境 , 例如回答場景問題、視覺與語言間對齊、語義正確 。 包括對正確答案的精確匹配 , 也包括與視覺輸入(如 RGB-D 圖像)的語義對齊 。 Navigation Reward(導航獎勵):關注路徑的 fidelity , 也就是路徑與參考路徑的匹配度 (trajectory fidelity)、終點精度 (endpoint accuracy) 等 。 通過這一獎懲機制 , 保證機器人走出來的不僅只是到達目的地 , 而是走出一條合理、不繞彎、不浪費時間的路徑 。3.Fast-in-Slow 推理范式:腦子快 + 身體穩
一個非常有意思的設計靈感是借鑒人類認知中的 “雙系統理論”(Thinking Fast and Slow 等) , 即一個系統擅長深思熟慮、長遠規劃;另一個系統擅長快速反應、實時控制 。
Slow 系統(System-2):以較低頻率工作 , 處理更宏觀、更長時段的語義信息和歷史觀察(視覺歷史、語言指令等) , 負責制定長期目標和語義一致性 。 Fast 系統(System-1):以高頻率執行 , 負責即時響應 , 控制短期動作 , 比如避障、調整姿態、走直線或轉彎等 。 它借助 Slow 系統的 latent 指導 , 但自己要輕量、低延遲 。 兩者異步協調:Slow 提供大致方向和語義指導 , Fast 則負責執行 , 保證在復雜環境中既不丟失目標語義一致性 , 也能快速響應環境變化 。
實驗與效果:真的有用嗎?
Nav-R1 給出的實驗證據很有說服力 , 既有模擬環境中的各種基準(benchmarks)也有真實機器人部署 。
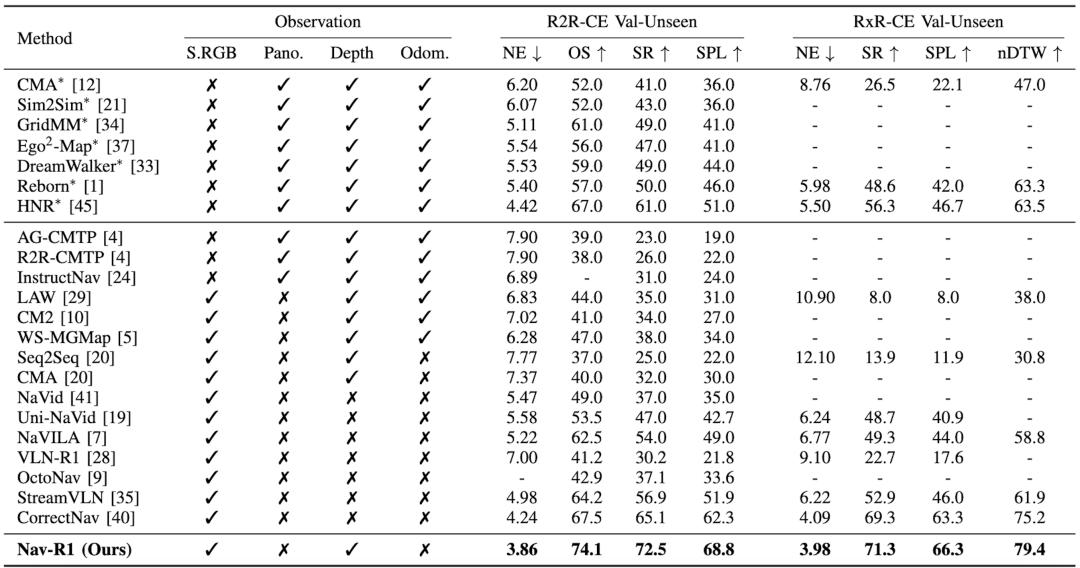
在多個導航任務(如視覺 - 語言導航 Vision-Language Navigation 的 R2R-CE、RxR-CE , 以及物體目標導航 ObjectGoal Navigation 等)中 , Nav-R1 的成功率(success rate)、路徑效率 (SPL 路徑長度加權指標) 等指標相比于其他先進方法提升了約 8% 或更多 。
VLN 任務結果
ObjectNav 任務結果
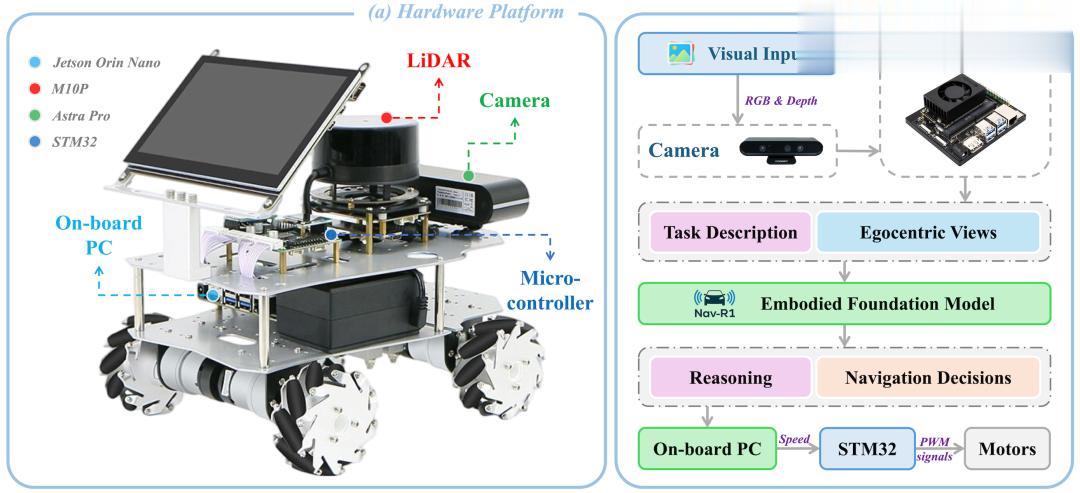
在真實硬件上的部署也通過了測試:機器人平臺(WHEELTEC R550 , Jetson Orin Nano + LiDAR + RGB-D 攝像頭等硬件)在會議室、休息室、走廊這些不同的室內場景中執行導航任務 , 表現穩健 。
Robot Setup
在三個不同的室內環境中進行真實世界實驗結果
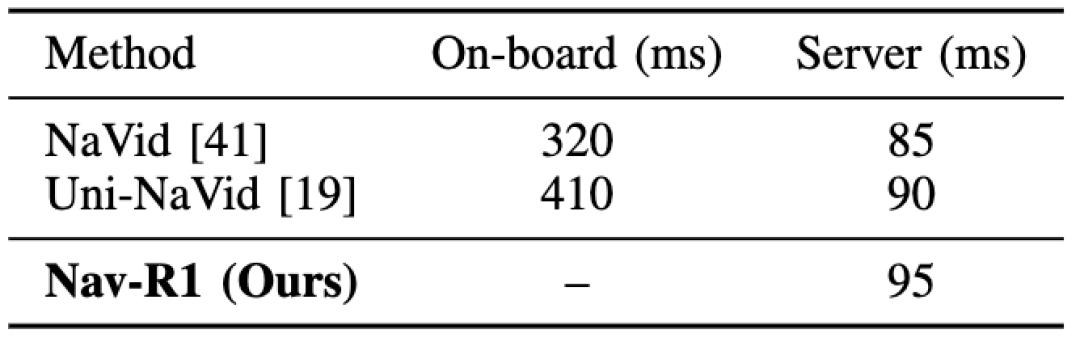
延遲 / 實時性方面也做了設計優化:Nav-R1 雖然推理能力強 , 但通過云端推理 + 本地執行命令 + Fast-in-Slow 架構 , 使得在資源受限的邊緣設備上仍可近實時運行(服務器端推理延遲在約 95 ms 左右)對比只在本地推理的大延遲優勢明顯 。
平均推理延遲比較
Demo 展示:從仿真到現實的雙重驗證
為了讓大家更直觀地理解 Nav-R1 的能力 , 研究團隊還準備了視頻 Demo , 涵蓋仿真環境和真實機器人環境兩類典型場景 。
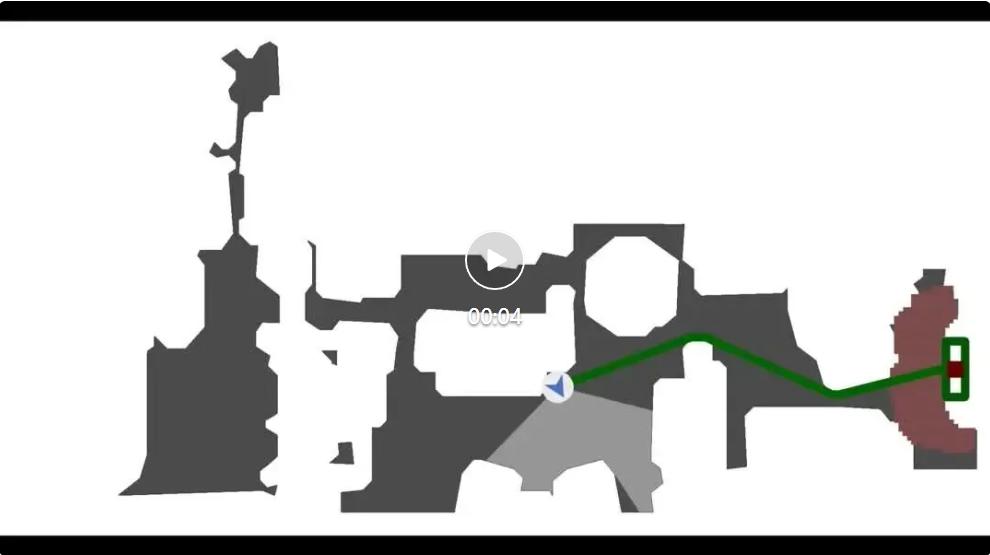
仿真環境:VLN 與 ObjectNav
在 Habitat 仿真平臺中 , Nav-R1 接收自然語言導航指令 , 例如「從走廊穿過客廳 , 到達右邊的沙發」 。
在 VLN (Vision-Language Navigation) 任務中 , Nav-R1 能夠理解復雜的語言描述 。指令:Walk past brown leather recliner. Walk through open french doors. Make hard left opposite zebra painting. Wait at mirror.
https://mp.weixin.qq.com/s/2huKYeV82Vv7Q8HfiXS5FQ
https://mp.weixin.qq.com/s/2huKYeV82Vv7Q8HfiXS5FQ
在 ObjectNav (Object Goal Navigation) 任務中 , 給定目標類別(如「找到電視顯示器」) , Nav-R1 會主動探索、識別物體 , 并規劃合理路徑 , 避開障礙物 , 快速到達目標 。
指令:Search for a tv monitor.
https://mp.weixin.qq.com/s/2huKYeV82Vv7Q8HfiXS5FQ
https://mp.weixin.qq.com/s/2huKYeV82Vv7Q8HfiXS5FQ
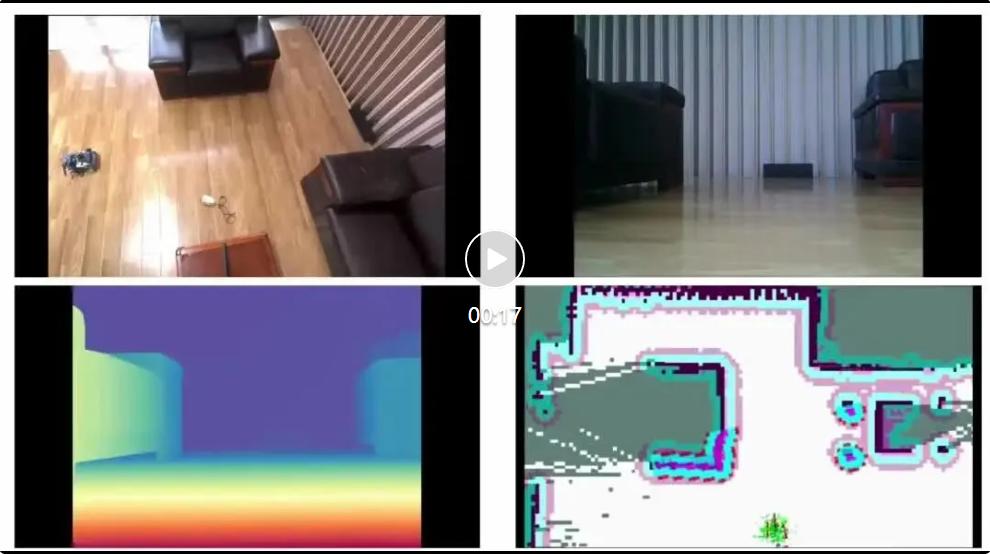
真實世界:VLN ObjectNav 機器人部署
研究團隊還把 Nav-R1 部署在 WHEELTEC R550 移動機器人平臺(配備 Jetson Orin Nano、RGB-D 攝像頭和 LiDAR) 。 在會議室、走廊、休息區等真實場景中 , Nav-R1 執行類似的 VLN 指令和 ObjectNav 任務 。
在 VLN (Vision-Language Navigation) 任務中 , Nav-R1 能夠理解復雜的語言描述 , 并在真實環境中執行指令 。
指令:Go to the black chair on your left and pause then move forward to the front-right and stop at the blue umbrella.
https://mp.weixin.qq.com/s/2huKYeV82Vv7Q8HfiXS5FQ
在 ObjectNav (Object Goal Navigation) 任務中 , 給定目標類別(如「找到電視顯示器」) , Nav-R1 會主動探索真實環境、識別物體 , 并規劃合理路徑 , 避開障礙物 , 快速到達目標 。
指令:Move straight ahead and look for the keyboard along the wall in front.
https://mp.weixin.qq.com/s/2huKYeV82Vv7Q8HfiXS5FQ
意義與應用場景
Nav-R1 它帶來了一些比較實際且有影響力的可能性 。
1. 服務機器人 / 家庭機器人
在家里 , 機器人要在雜亂的環境中穿行、按指令找東西、與人交互時 , 不僅要走得快、走得穩 , 還要走得「懂」 。 Nav-R1 的結構化推理 + 路徑精準性 + 實時控制恰好能提升用戶信心與使用體驗 。
2. 助老 / 醫療 / 輔助設備
在醫院、養老院、輔助設施中 , 環境復雜 , 人多物雜 , 需要機器人能安全、可靠地導航 , 且對錯誤能夠有語義上的理解與糾正能力 。
3. 增強現實 / 虛擬現實
AR 或 VR 中 , 如果虛擬智能體或助手要在用戶的物理環境中導航(或通過視覺輸入理解環境為用戶指路) , 這樣的推理 + 控制結合非常關鍵 。
4. 工業 / 危險環境
在工廠、礦井甚至災害現場 , 機器人需要在未知或危險環境中執行任務 。 Nav-R1 的泛化能力與穩健性使得它可以作為基礎模塊進一步應用 。
作者介紹
劉慶祥是上海工程技術大學電子電氣工程學院在讀碩士 , 研究方向聚焦于視覺語言導航、具身智能 。 曾參與多項科研項目 , 致力于構建具備具身世界模型 。
黃庭是上海工程技術大學電子電氣工程學院在讀碩士 , Zhenyu Zhang 和 Hao Tang 老師的準博士生 , 研究方向聚焦于三維視覺語言模型、空間場景理解與多模態推理 。 曾參與多項科研項目 , 致力于構建具備認知與推理能力的通用 3D-AI 系統 。
張澤宇是 Richard Hartley 教授和 Ian Reid 教授指導的本科研究員 。 他的研究興趣扎根于計算機視覺領域 , 專注于探索幾何生成建模與前沿基礎模型之間的潛在聯系 。 張澤宇在多個研究領域擁有豐富的經驗 , 積極探索人工智能基礎和應用領域的前沿進展 。
唐浩現任北京大學計算機學院助理教授 / 研究員、博士生導師、博雅和未名青年學者 , 入選國家級海外高水平人才計劃 。 曾獲國家優秀自費留學生獎學金 , 連續兩年入選斯坦福大學全球前 2% 頂尖科學家榜單 。 他曾在美國卡耐基梅隆大學、蘇黎世聯邦理工學院、英國牛津大學和意大利特倫托大學工作和學習 。 長期致力于人工智能領域的研究 , 在國際頂級期刊與會議發表論文 100 余篇 , 相關成果被引用超過 10000 次 。 曾獲 ACM Multimedia 最佳論文提名獎 , 現任 ACL 2025、EMNLP 2025、ACM MM 2025 領域主席及多個人工智能會議和期刊審稿人 。 更多信息參見個人主頁: https://ha0tang.github.io/
推薦閱讀















- 從造車到造“人”:奇瑞招商在即,車企搶占機器人賽道
- 小米17 Pro Max突然官宣,屏幕續航性能全超車!讓米粉傻眼了
- 人形機器人公司Figure AI融資10億美元,加速AI數據收集與生產
- 特斯聯與優必選達成戰略合作,將構建下一代智能體機器人|最前線
- 具身智能還需要一個「五年耐心」
- 華為首款旅行車 1 小時訂單破 5000,余承東再次「封神」?
- 安卓機集體「 蘋果 」化?
- 云鯨二季度全球市場表現強勁,躋身2025年Q2全球掃地機器人市占TOP5
- 谷歌DeepMind「糞坑淘金」全新方法,暗網毒數據也能訓出善良模型
- 穿過AI迷霧,企業如何從「+AI」奔向「AI+」?