首款推理具身模型,谷歌DeepMind造!自主理解/規劃/執行復雜任務
文章圖片

文章圖片

文章圖片

文章圖片
文章圖片

文章圖片
衡宇 發自 凹非寺
量子位 | 公眾號 QbitAI
全球首個具備模擬推理能力的具身模型來了!
谷歌DeepMind正式發布新一代通用機器人基座模型——Gemini Robotics 1.5系列 。
它不止于對語言、圖像進行理解 , 還結合了視覺、語言與動作(VLA) , 并通過具身推理(Embodied Reasoning)來實現“先思考 , 再行動” 。
這一系列由兩大模型組成:
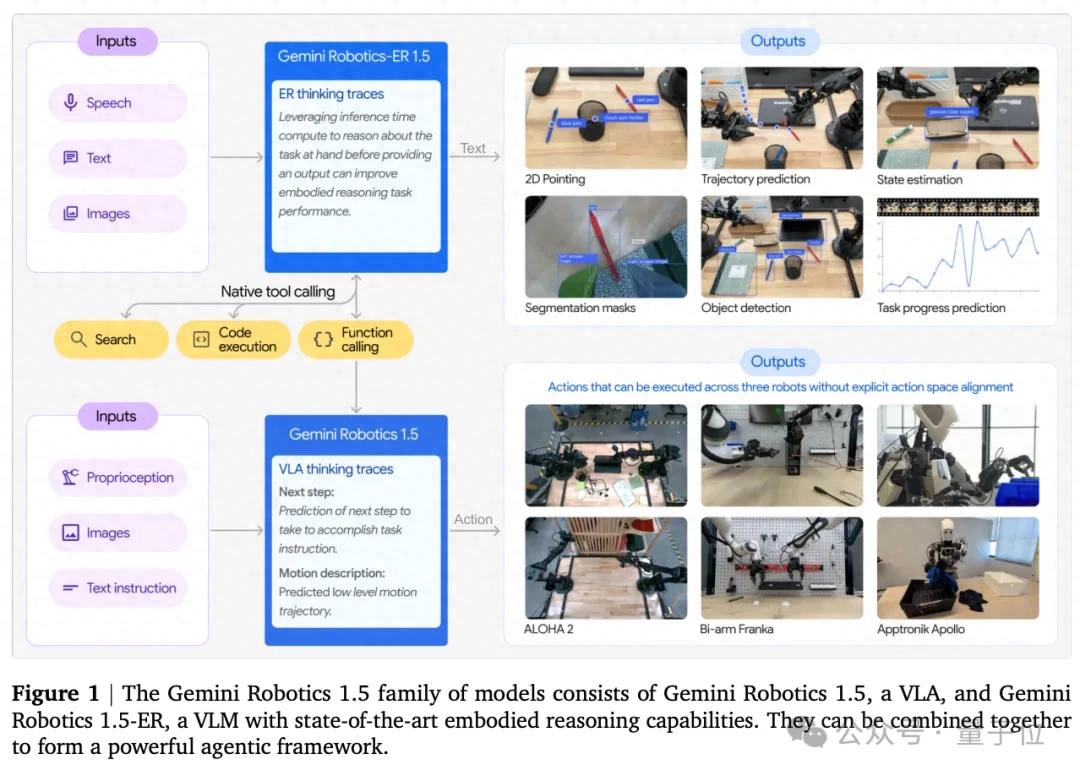
Gemini Robotics 1.5(GR 1.5):負責動作執行的多模態大模型; Gemini Robotics-ER 1.5(GR-ER 1.5):強化推理能力 , 提供規劃與理解支持 。其中 , ER代表“具身推理” 。
這意味著GR-ER 1.5是全球首個具備模擬推理能力的具身模型 。
不過 , GR-ER 1.5并不執行任何實際操作 , GR 1.5正是為執行層而生 。
兩者結合 , 能讓機器人不僅完成“折紙、解袋子”這樣的單一動作 , 還能解決“分揀深淺色衣物”甚至“根據某地天氣自動打包行李”這種需要理解外部信息、分解復雜流程的多步任務 。
甚至 , 它能根據特定地點的特定要求(比如北京和上海的不同垃圾分類標準) , 自己上網搜索 , 以幫助人們完成垃圾分類 。
而且用上GR 1.5系列的模型 , 還能夠在多種不同的機器人之間進行能力的零樣本跨平臺遷移 。
Unbelivable~
毫不夸張地說 , 這是谷歌繼Gemini 2.5之后 , 又一個將通用AI推向現實世界的重要里程碑 。
哈斯比斯也激動表示:
GR 1.5以多模態Gemini為基礎 , 展示了其能夠理解并推理物理世界的強大功能 。 未來機器人將變得至關重要——我們對這項開創性工作感到非常興奮!
GR 1.5系列五大能力展示先來看一段視頻——
我們來把GR 1.5系列在發布中展示的能力 , 總結為五個關鍵詞:
執行復雜長程任務 , 中間還能自我檢測并修正不僅限于一次抓取、一次搬運 , GR 1.5能執行包含多步子任務的長流程 。
比如:
把不同顏色的衣服分類; 從衣柜取出雨衣 , 再打包進行李箱; 在廚房完成配料準備 , 甚至嘗試烹飪流程 。在GR 1.5這里 , 任務被分解成多個階段 , 機器人逐一完成 。
更重要的是 , 在執行任務的過程中 , GR 1.5能檢測成功與否 , 并自動修正 。
適配多種機器人硬件同一個模型 , 既可以驅動低成本雙臂機器人ALOHA , 還可以驅動工業級Franka , 還可以驅動人形機器人Apollo 。
一整個絲滑無縫遷移使用 。
這意味著 , 不需要針對每個平臺單獨訓練 , 一個通用模型就能上手不同團隊、不同形態的多種硬件 。
跨機器人遷移谷歌DeepMind機器人部門負責人Carolina Parada表示:
如今的機器人高度定制化 , 部署困難 , 往往需要數月時間來安裝一個只能執行單一任務的單元 。
轉觀GR 1.5系列 , 這個模型在ALOHA上學會的技能 , 可以直接遷移到Franka;在Franka上訓練的操作 , 能零樣本轉移到Apollo 。
這背后的關鍵在于Motion Transfer技術(詳細介紹見后文) , 使機器人不再局限于“誰教誰用” , 而是真正形成跨平臺的通用動作理解 。
推理型具身模型如前文介紹 , GR-ER 1.5是一個具身推理模型 。
這使得GR 1.5系列加持下的機器人在行動前 , 會在內心生成一段內心獨白 。
它會先用自然語言把復雜任務拆解為小步驟 , 再逐一執行 。
這種顯性思考不僅讓機器人更穩健 , 也讓人類可以清晰看到它的思考過程 , 提升了可解釋性 。
GR 1.5系列的兩款模型協同工作 , 共同推理思考如何完成任務 。
如下圖展示:
安全可解釋在演示中 , 研究人員展示了GR 1.5系列加持下的機器人 , 在操作中如何自我修正:
比如抓起水瓶失敗后 , 立刻轉換方案 , 用另一只手完成任務 。
同時 , 模型還能識別潛在風險 , 避免危險動作 , 確保在人類環境中運行時的安全性 。
提出全新“Motion Transfer”機制Gemini Robotics 1.5最大的突破 , 在于實現了“規劃+執行”的完整閉環 。
前面我們已經提到過 , 這一系列由兩大模型組成:
GR 1.5:VLA模型 , 專注將語言/視覺輸入轉化為動作輸出 。 GR-ER 1.5:強化推理的Vision-Language模型 , 負責高層規劃、工具使用與進度監控 。兩款模型都基于Gemini基礎模型構建而來 , 但已使用適應物理空間操作的數據進行微調 。
其中 , 前者是執行者 , 能夠直接把自然語言和視覺輸入轉化為低層級的機器人動作 。
后者是大腦指揮官 , 負責理解復雜任務、做出高層規劃 , 并在必要時調用外部工具、監控任務進度 。
二者組合成一個Agentic Framework , 讓機器人不僅能聽懂指令 , 還能思考如何完成并執行到底 , 以此實現“規劃+執行”的閉環 。
支撐這一體系的 , 是GR 1.5系列龐大而多樣化的數據來源 。
一方面 , 團隊采集了大量真實機器人在ALOHA、Franka、Apollo等平臺上完成的成千上萬種操作數據 。
另一方面 , 數據集中還引入了互聯網中的文本、圖像與視頻信息 , 確保模型既擁有來自現實的動作經驗 , 具備廣泛的語義與世界知識 。
要真正讓不同形態的機器人共享技能 , 單靠數據還不夠 。
為此 , 研究團隊提出了全新的Motion Transfer機制 。
Motion Transfer的核心思路 , 是把不同機器人平臺的運動軌跡和操作經驗 , 映射到一個統一的動作語義空間中 。
這樣一來 , 看似完全不同的硬件——比如機械臂與人形機器人——在模型眼中就有了共通語言 , 于是能把不同機器人平臺的動作映射到一個統一的表示空間 , 使得GR 1.5系列具備操作經驗跨機器人遷移的能力 。
更重要的是 , Motion Transfer不只是做簡單的對齊 , 它還結合了跨平臺的大規模數據 。
它“提煉”出了物理世界的通用規律:
物體怎么被抓住、怎樣保持平衡、不同環境下動作要如何調整……以此增強任務泛化和跨機器人遷移測試的能力和水平 。
同時 , 在訓練過程中 , 大約九成以上的迭代都在MuJoCo仿真環境中完成 , 模型先在虛擬世界里快速試錯、迭代 , 再遷移到真實機器人進行驗證 。
這樣一來 , 不僅顯著提升了研發效率 , 也保證了在現實硬件上執行時的穩定性與安全性 。
三大核心創新 , 還不犧牲安全性研究團隊提出 , GR 1.5系列的核心價值 , 在于同時實現了三個方面的創新與突破 。
最引人注目的 , 是它讓機器人具備了思考推理的能力 。
在傳統的模型中 , 動作往往是對指令的直接映射 , 而 GR 1.5 在行動前會先生成一段思考軌跡 , 把復雜任務拆解成小步驟 , 再逐一執行 。
這種顯性推理不僅讓機器人在多步任務中更穩健 , 還讓研究人員和用戶能夠直接看到它的思考過程 , 增強了可解釋性和信任感 。
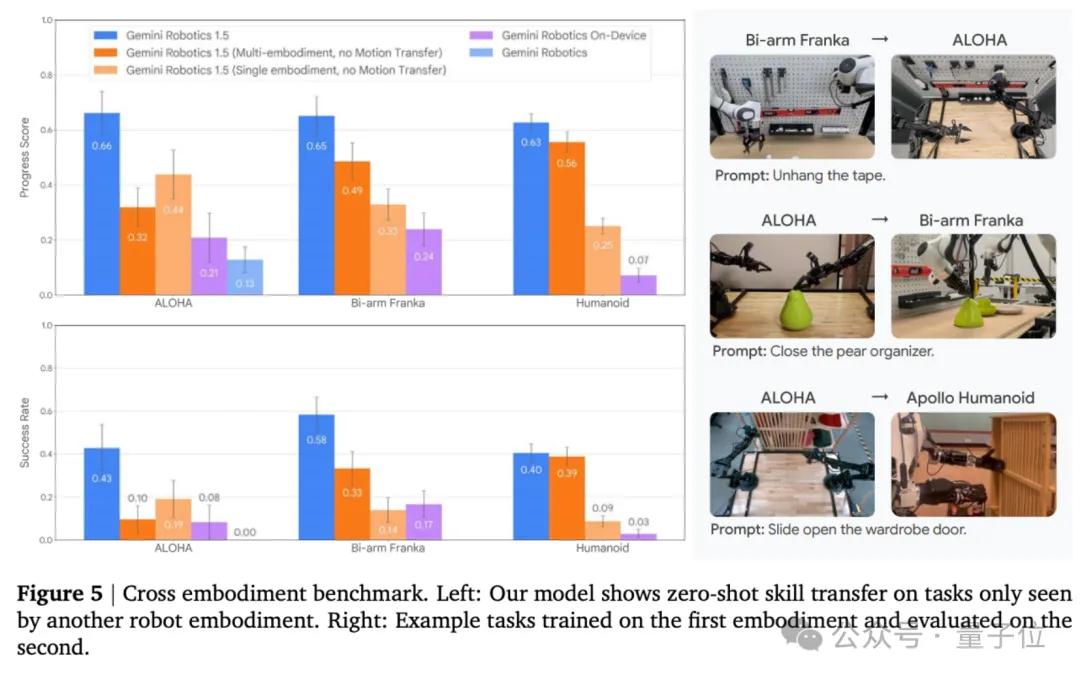
另一項突破是跨平臺的技能遷移 。
過去 , 機器人學習往往被局限在某一特定平臺上 , 數據難以復用 。
但GR 1.5系列在引入Motion Transfer機制后 , 把不同機器人之間的動作經驗抽象到統一空間 , 使得在機器人甲身上學到的技能 , 可以直接遷移到機器人乙身上——甚至在未見過的新環境中也能順利執行 。
這意味著機器人不再被硬件形態束縛 , 而是能夠共享整個生態的知識與經驗 。
與此同時 , 具身推理模型GR-ER 1.5把“理解物理世界”的能力推向了新高度 。
它不僅能進行空間理解和任務規劃 , 還能實時評估任務進度 , 識別潛在風險 , 甚至在復雜場景中做出類似人類的推斷與修正 。
在學術基準測試中 , GR-ER 1.5在空間推理、復雜指點、進度檢測等任務上全面超越了GPT-5和Gemini 2.5 Flash , 刷新了業界的表現上限 。
研究團隊還對GR 1.5系列做了更多評測:
在230項任務的基準測試中 , GR 1.5在指令泛化、動作泛化、視覺泛化和任務泛化四個維度上都表現出色 , 明顯優于前代模型 。
在長時序任務上 , 結合GR-ER 1.5的系統 , 任務完成進度分數最高接近80% , 幾乎是單一VLA模型的兩倍 。
尤其值得注意的是 , 在跨機器人遷移測試中 , 模型展現出了前所未有的零樣本遷移能力 。
更關鍵的是 , 這種強大性能并沒有以犧牲安全為代價 。
如下圖數據顯示 , GR 1.5 在ASIMOV-2.0安全基準中表現出更高的風險識別與干預能力 , 能夠理解動作背后的物理風險 , 并在必要時觸發保護機制 。
配合自動紅隊測試的持續打磨 , 模型在抵御對抗攻擊、避免幻覺響應等方面也展現出更強魯棒性 。
One More Thing讓我們簡單回溯一下——
今年3月 , 谷歌首次推出了讓機器人擁有多模態理解能力的Gemini Robotics系列;6月 , 又推出了Gemini Robotics On-Device , 這是一個針對快速適配和機器人硬件上穩健靈巧性進行優化的本地版本 。
Parada表示 , 隨著這次更新 , GR系列正從執行單一指令轉向對物理任務進行真正的理解和解決問題 。
But!
噔噔噔 , 最后敲個黑板:
目前 , 開發者已經可以通過Google AI Studio中的Gemini API使用GR-ER 1.5 , 而GR 1.5只供少數谷歌DeepMind的合作伙伴使用 。
等等黨們 , 看來還要再等等等等等一會了……
參考鏈接:[1
https://x.com/demishassabis/status/1971292365592854602?s=46t=fzKJptGJMpr-yj3MUXd6HA[2
https://arstechnica.com/google/2025/09/google-deepmind-unveils-its-first-thinking-robotics-ai/[3
https://www.theverge.com/news/785193/google-deepmind-gemini-ai-robotics-web-search[4
https://the-decoder.com/google-deepmind-brings-agentic-ai-capabilities-into-robots-with-two-new-gemini-models/
— 完 —
量子位 QbitAI · 頭條號
【首款推理具身模型,谷歌DeepMind造!自主理解/規劃/執行復雜任務】關注我們 , 第一時間獲知前沿科技動態
推薦閱讀
















- 多模態推理最高加速3.2倍!華為諾亞新算法入選NeurIPS 2025
- 戴爾科技首款入耳式耳機發布!音質出眾 滿足高效辦公協作需求
- 華為WATCH Ultimate 2國內官宣:全球首款北斗語音消息
- 全球首款液冷SSD誕生!雙面高效散熱、最大7.68TB
- LeCun團隊開源首款代碼世界模型!能像程序員一樣思考的LLM來了
- 阿里云與英偉達再牽手,在具身智能應用落地達成合作
- 首個代碼世界模型引爆AI圈,能讓智能體學會「真推理」,Meta開源
- 全球首款!2nm芯片進場,三星這次完全是意料之外,情理之中
- 首款鴻蒙耳機來了,華為第三代自研芯內置NPU,算力暴漲10倍
- 慧靈科技亮相工博會:打造“具身智能產業基座”,推動智能體落地