
文章圖片
文章圖片

文章圖片

文章圖片

文章圖片

文章圖片

文章圖片
文章圖片
文章圖片

文章圖片
編輯:KingHZ
【新智元導讀】AI下半場 , AGI已成過去式 , ASI正引領新智能革命!OpenAI推出的GDPval評估體系 , 通過真實工作任務審視大模型潛力 , 揭示AI如何從實驗室走向3萬億經濟戰場 , 助力人類從日常瑣事中解放 , 擁抱創造性未來 。
AI下半場真來了!
AGI都過時了 , 現在AI業內討論的是超級人工智能ASI:
AGI能把人類從80%的日常工作中解放出來;
而ASI則全面超越人類智能的系統 。
剛剛 , 在a16z訪談中 , OpenAI首席科學家Jakub Pachocki , 透露OpenAI的研究路線圖的下一步是推理 , 下一個5年的重點目標是打造自動化研究人員:
AI自動發現新想法 , 自動化研究人員的工作 , 自動化機器學習研究 。
但理解AI潛力最清晰的方式 , 并不是預測未來 , 而是看看模型現在已經能做什么 。
歷史經驗告訴我們 , 從互聯網到智能手機 , 每一項重大技術從誕生到普及都需要十年以上 。
OpenAI希望以更透明的方式 , 展示大模型如何真正服務于現實世界 。
因此 , 他們推出了一項全新的評估體系GDPval , 在有據可依的基礎上審視AI進步軌跡 , 而不是憑空臆測 。
論文地址:https://cdn.openai.com/pdf/d5eb7428-c4e9-4a33-bd86-86dd4bcf12ce/GDPval.pdf
數據集:https://huggingface.co/datasets/openai/gdpval
在GDPval 上 , 專家評審員將頂尖模型的輸出與人類專家的工作進行了比較 。
哈佛大學教授、名譽校長Lawrence H. Summers——同時任OpenAI的董事會成員 , 認為新研究令人興奮:
在多項實際任務上 , 即使只有有限的指導 , AI的表現與人類相當甚至更好;
人類與人·工智能結合 , 可以更高效;
AI具有令人驚訝的能力 , 可用來評估并隨后改進其性能 。
OpenAI坦承:Claude Opus 4.1表現最佳 , 在接近一半的任務上與專家工作相當或更好 , 明顯優于GPT-5 。
但OpenAI的進步速度引人注目:在一年內 , GPT系列模型勝率幾乎翻了一番 。
GDPVal
衡量AI的3萬億美元影響
過去 , 大模型評估往往集中在學術測試或編程挑戰上 。
這些評估雖然在推動模型推理能力方面起到了重要作用 , 但與現實工作場景仍有一定距離 。
為了填補這道鴻溝 , OpenAI逐步開發出一系列更貼近實際、更具經濟意義的評估方法——
從傳統的MMLU(涵蓋多學科的考試型題目) ,
到更具實戰意味的SWE-Bench(軟件工程Bug修復任務)、MLE-Bench(機器學習工程任務 , 如模型訓練與分析)、Paper-Bench(科研論文的邏輯推理與評議) ,
再到基于市場項目的SWE-Lancer(源于真實交易的自由職業軟件開發任務) 。
GDPval正是在這一演進路徑上的下一個關鍵節點 。
這項評估直接來源于現實工作中的任務 , 覆蓋了9大行業、44種職業、每年共計3萬億美元經濟價值 。
整個任務集共包含1320個高度專業化任務(其中220為金標任務子集 , 已開源) 。
這些任務源于真實工作產出 , 比如法律意見書、工程圖紙、客服對話記錄或護理計劃等 。
每一項任務都需通過多輪嚴格審核流程 , 確保其具備三點 , 即:高度貼近實際工作場景;可由同領域的專業人士獨立完成;具備明確的評估標準 。
每項任務平均經歷5輪專家評審 , 評審團隊包括其他任務撰寫者、獨立職業評審專家 , 并輔以模型可行性與清晰度校驗 。
GDPval的獨特之處在于 , 不僅任務內容貼近現實、形式多樣 , 還具備極高的專業性和代表性 。
與傳統評估相比 , GDPval并非簡單的文本提示任務 。 它要求模型處理完整的參考材料與工作背景 , 輸出形式也不僅限于文字 , 還包括文檔、PPT、圖表、電子表格 , 甚至多媒體內容 。
當然 , GDPval目前還只是一個起點 , 尚未完全覆蓋現實知識工作中任務的復雜性 。
它幫助我們清晰地認識到 , 大模型不僅僅能在實驗室中解題 , 更可能在千千萬萬人的日常工作中 , 扮演可靠的輔助角色 。
請再讀一遍:AI不再只是「通過考試」 , 而是開始接受文明體系本身的考核標準:GDP 。
獨立研究員Shanaka Anslem Perera表示:
這不僅僅是一套評估體系 , 更像是某種經濟生命體的誕生。
GDPval , 是「后人類經濟時代」的第一套會計體系 。
【OpenAI 3萬億美元測試,AI首戰44個行業人類專家!】
今天 , 它是一個「基準」;明天 , 它將成為新物種的記分牌 。
當AI的產出開始計入GDP , 它就不再是工具 , 而是超越「土地、勞動與資本」的第四種生產要素
半數任務
AI已逼近專業水平
早期測試結果顯示 , 當前領先的大模型在某些任務上 , 表現已接近甚至媲美行業專家 。
在220項金標任務中 , 行業專家盲測了多款主流模型:
GPT-4o、o4-mini、OpenAI o3、GPT-5、Claude Opus 4.1、Gemini 2.5 Pro、Grok 4 。
結果顯示:
- Claude Opus 4.1在美學表現方面表現最強(如文檔排版、PPT布局等);
- GPT-5則在準確性方面領先 , 尤其擅長定位專業知識點 。
在接近一半的任務中 , 其產出被評為「與人類一樣好」甚至「優于人類」 。
從GPT-4o(2024年春發布)到GPT-5(2025年夏發布) , 模型在GDPval任務上的平均表現幾乎翻倍 , 呈現出明顯的線性進步趨勢 。
OpenAI還發現 , 頂尖模型完成GDPval任務的速度和成本 , 平均是人類的1%——約快100倍、便宜100倍 。
不過 , 這一數據僅統計了模型推理時間與API調用成本 , 并未包含人類監督、迭代修改與實際集成等現實工作流程所需的資源投入 。
盡管如此 , 在模型表現尤為出色的任務類型上 , 先用AI試一輪 , 再交由人類介入 , 可能成為節省時間與成本的理想策略 。
如何優化模型以提升GDPval表現
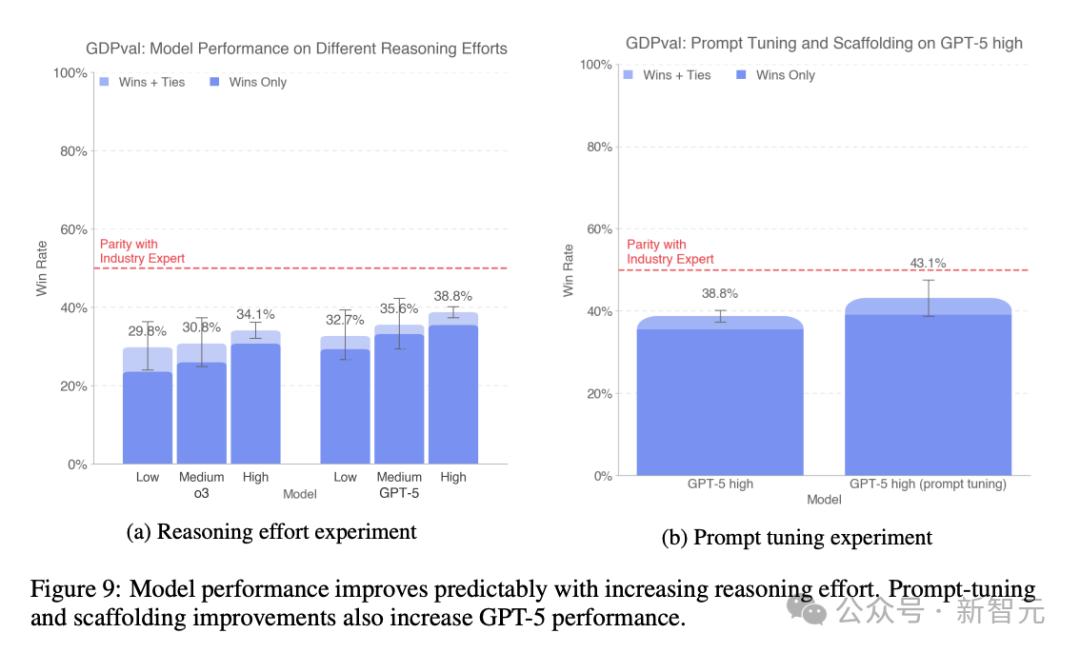
為了驗證是否可以提升GPT-5在GDPval任務中的表現 , OpenAI增量訓練了實驗性的內部特定版GPT-5 。
結果證實 , 經過該訓練流程后 , 模型性能確實得到了實質性提升 , 展現了進一步優化的潛力 。
下圖的多項受控實驗結果 , 進一步印證了這一點:擴大模型規模、引導模型進行更多推理步驟、提供更豐富的任務背景信息 , 都會帶來可衡量的性能增益 。
OpenAI設計了一條通用提示詞 , 要求模型在提交結果前進行嚴謹的自檢 , 可適用于各類多模態經濟類任務 , 并未針對具體問題進行過擬合 。
最豪評分員
頂尖機構的14年行業專家
在GDPval任務中 , 為了評估模型的實際表現 , OpenAI依賴資深從業者作為「評分員」 。
專家入選標準包括:至少4年行業從業經驗 , 且簡歷中需體現專業認可度、晉升軌跡及管理職責 。 參與本項目的專家平均擁有14年從業經驗 。
行業專家團隊曾任職于以下代表性機構:
Meta、微軟、摩根士丹利、谷歌、甲骨文、蘋果、通用電氣、高盛、HBO、IBM、摩根大通、領英、洛克希德·馬丁、美國銀行、巴克萊銀行、波音、美國疾控中心、花旗集團、美國國防部、美國聯邦貿易委員會、美國國家公園管理局、NFL網絡、雷神、Sally Beauty、《科學美國人》、蘇富比、英國電訊報集團、賽默飛世爾、《時代》雜志、美國司法部、美國空軍、美國郵政總局……
這些評分員來自與任務相同的職業背景 , 并在不知曉「人類 vs AI」身份的前提下 , 盲評由模型與人類任務撰寫者完成的任務成果 。
他們不僅會給出評價 , 還會對比排名 , 最終判斷每個AI生成結果是「優于」、「相當于」或「劣于」人類結果 。
為了確保評分過程透明一致 , 每位任務撰寫者還為其職業領域制定了詳細評分標準(rubric) , 涵蓋各類評價維度 。
OpenAI還開發了「自動評分器」——一個用于預測人類專家偏好的AI系統 , 模仿行業專家的對比評估方式 。
自動評估工具比專家評估更快、成本更低 , 且與人類專家評估的一致性達到66% , 僅比人類評估者之間71%的一致性低5% 。
由于其局限性 , OpenAI沒有使用自動評分器取代人類打分員 。
AI與工作的未來圖景
隨著AI能力不斷提升 , 勞動力市場勢必將發生結構性變化 。
GDPval的早期結果已經表明 , 大模型在處理那些重復性強、結構清晰的任務時 , 效率遠超人類專家 , 不僅更快也更便宜 。
但也要看到 , 大多數工作不僅僅是可拆解的任務清單 。
GDPval的意義在于:它揭示了AI可以承接哪些日常性事務型任務 , 從而為人類騰出時間專注更具創造力、判斷力的復雜工作 。
當AI能夠以這種方式補充而非替代人類時 , 將為經濟增長釋放巨大潛力 。
OpenAI希望借助GDPval與相關工具 , 推動AI工具的普及平民化 , 支持勞動者順利適應時代變革 , 并打造能鼓勵廣泛參與與共享成果的激勵機制 。
同時 , OpenAI也開放了GDPval金標任務子集以及一個公共評分平臺 , 希望能為更多研究者提供基礎設施 , 持續推動該方向的發展 。
愿每個人都能搭上AI時代的「上行電梯」 。
推薦閱讀














- 剛剛,Meta挖走OpenAI清華校友宋飏,任超級智能實驗室研究負責人
- 馬斯克與OpenAI再生糾葛 旗下xAI指控對方竊取商業機密
- 再見了,英偉達!500億美元中國市場對美芯關門,比爾蓋茨預言成真
- 突發!Meta剛從OpenAI挖走了清華校友宋飏
- 貝恩:AI企業8000億美元收支缺口,如何創造收入彌補支出是個難題
- AI芯片廠商Groq完成7.5億美元融資,投后估值69億美元
- 英偉達千億美元投資OpenAI,意在維持AI泡沫不破?
- 鴻蒙智行93萬車主迎來最重磅OTA升級:30+項體驗優化
- 賣出550萬枚智能戒指!可穿戴黑馬被曝新融資,沖刺百億美元估值
- 全是套路!英偉達千億投OpenAI,奧特曼拿錢買卡還讓甲骨文賺差價