文章圖片

文章圖片
文章圖片

文章圖片
【估值840億AI實驗室再放大招,他們要給大模型戴上「緊箍咒」】
文章圖片
剛剛 , OpenAI前CTO Mira Murati創辦的Thinking Machines Lab再次發布成果!
這是他們繼《克服LLM推理中的不確定性》(Defeating Nondeterminism in LLM Inference)之后 , 第二篇研究文章——《模塊流形》(Modular Manifolds) 。
博客地址:https://thinkingmachines.ai/blog/modular-manifolds/
訓練大型神經網絡如同「走鋼絲」 , 必須小心翼翼地維持其內部「健康」 , 防止權重、激活值或梯度這些關鍵張量變得過大或過小 , 以免引發數值溢出等一系列問題 。
其中一個重要的思路 , 是為大模型提供一套統一的量級管理 。
首先是穩住基本盤 。
使用Layer Norm技術把每層的輸出拉回合適范圍 , 對激活向量進行歸一化(normalization) , 這也是目前一種普遍的做法 。
對梯度更新進行歸一化也很常見 , 例如Muon優化器對更新進行譜歸一化處理 , 使每一步更新的幅度可控 。
再進一步 , 是直接「管住」權重本體 。
歸一化權重矩陣是一個值得嘗試的方向 。
文中提出了一種重新思考優化算法提供了新視角:將權重張量約束在某個子流形(submanifold)上 , 以便與這些流形約束協同設計優化算法 。
這好比把「救火」變「預防」:
一開始就把參數放在健康區間 , 讓訓練更穩、更具解釋性 , 從而使大模型可以更穩定、高效地訓練起來 。
流形優化器的形態我們知道 , 流形只是一個局部看起來很平坦的曲面 。
如果放大到足夠多 , 它看起來就像是一個普通平面 。
流形上某一點附近的局部平坦空間稱為「切空間」(tangent space) 。
如圖1所示 , 三維球面或更高維度的超球面是一個流形 , 圖中以紅色部分表示其在某點的切平面 。
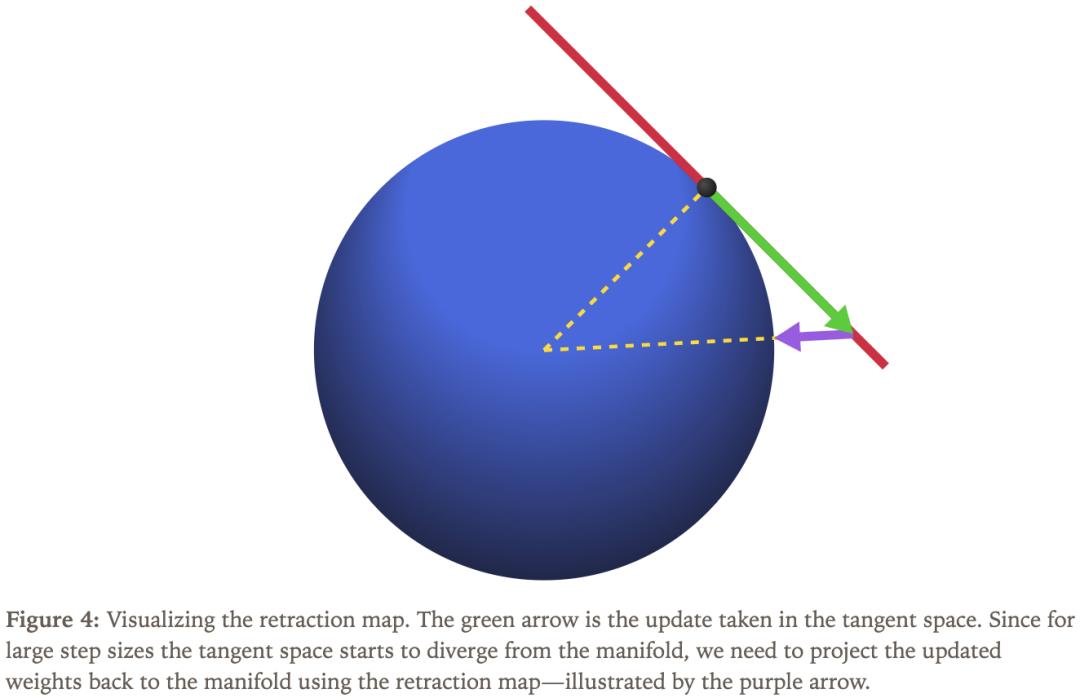
為了讓權重能夠「待在」指定的流形里 , 一個簡單的方法是使用普通優化器 , 在每步更新后將權重投影回流形 。
但問題是如果優化步驟偏離流形太多 , 再被強制投影回來 , 這會導致名義學習率不再對應參數在流形上的實際位移 , 從而削弱我們對「步長—效果」關系的直覺 。
想在流形上認真設計訓練算法 , 必須先想清楚:在切空間里怎么度量「距離」?
一個解決思路是直接在切空間中進行優化 。 這樣 , 每一步都是沿著流形「表面」走 , 學習率能更好地對應「實際位移」 。
常見的選擇是歐幾里得距離 , 但也可以選擇以其他方式測量距離 , 如圖2所示 。
值得注意的是 , 距離度量方式的選擇會直接影響最優優化步驟的方向 。
圖3中 , 粉色箭頭表示原始梯度——即損失函數對權重的偏導數(partial derivative) 。
也就是說 , 我們不一定非要嚴格按照梯度方向移動 。
為了用數學表達這個過程 , 我們可以把「在流形約束和特定距離度量下的最優更新方向」看作一個帶約束的優化問題 , 可以用一個搭配歐幾里得范數的超球面來舉例 。
用g表示梯度 ,w表示超球面上的當前點 ,a表示更新方向 ,η表示學習率 , 我們需要解決的問題是:
再回到圖 1、2 和3所展示的可視化語言 , 這個公式的意思是:綠色箭頭(也就是a的最優解)必須同時滿足兩個條件:
一是它要落在紅色的切平面上 , 二是它必須在半徑為η的黃色圓圈上 。
我們可以應用拉格朗日乘數法來求解 。
其中λ和μ是拉格朗日乘子 。
對這個拉格朗日函數對a求導并令其為零 , 然后結合兩個約束條件求解λ和μ , 就可以得到最優更新方向 。
簡單來說最優更新的做法是:先從梯度中減去與w同方向的徑向分量 , 即把梯度投影到切空間上 , 然后將結果歸一化 , 再乘以學習率 。
這樣得到的更新方向就在切空間里了 。
圖4中顯示這個微小的修正過程被稱為「回縮映射」(retraction map) 。
完整的流形優化算法如下:
總結來說 , 一階流形優化器包含三個步驟:
找到一個單位長度的切向量 , 在梯度方向上盡可能遠;
用學習率乘以這個方向 , 然后從當前權重中減去;
把更新后的權重通過回縮映射拉回流形上 。
在執行這一流程時 , 我們需要決定選擇什么樣的流形來作為約束 , 此外是如何定義「長度」的度量方式 。
根據這兩個選擇的不同 , 我們就能得到不同的優化算法 , 具體見下表 。
流形MuonTransformer中的典型權重矩陣W是一個「向量變換器」 , 即它將輸入向量x轉換為輸出向量y=Wx 。
我們希望設計一種流形約束和距離函數 , 使得該矩陣對輸入向量的作用合理:既不應導致輸出值過大或過小 , 也不應在更新權重時引起輸出向量劇烈變化或幾乎無變化 。
一個思考矩陣如何作用于向量的好方法是使用奇異值分解(SVD) , 如圖 5 所示 。
SVD以分解矩陣的方式顯示矩陣如何沿著不同的軸拉伸輸入向量 。
我們希望矩陣的「拉伸效應」接近于1 , 因此選擇了一個所有奇異值均為1的矩陣流形 。
這種矩陣流形在數學上被稱為Stiefel流形 , 在高矩陣( m≥n)的假設下 , 它可以等價地定義為以下集合:
要為Stiefel流形設計優化器 , 還需選擇一個合適的距離函數 。
為限制權重更新對輸入向量的最大拉伸作用 , 譜范數(spectral norm) , 即矩陣最大奇異值的度量是一個合適的選項 。
雖然它只約束了最大效應 , 但由于優化器會飽和這一上限 , 因此也能間接防止最小效應過小 。
正是這一想法 , 促成了Muon優化器的提出 。
這一想法與Stiefel流形約束結合后 , 就形成了「manifold Muon」問題 。
文中的一個關鍵發現是一個凸優化問題 , 可以通過標準方法——對偶上升法(dual ascent)來求解 。
經過推導 , 對偶函數的梯度為:
通過一個小實驗 , 可以驗證算法的可行性 , 實驗設置與結果見圖6 。
模塊流形這里還有一個重要的問題:當我們將多個層組合起來構建完整的神經網絡時 , 會發生什么?
是否需要關注層與層之間的交互 , 并據此修改優化策略?
這需要一種可以將前文介紹的推導邏輯推廣到整個神經網絡的方法——模塊流形(modular manifolds)理論 。
該理論的核心思想是:構建一種抽象機制 , 用來指導如何在各層之間合理分配學習率 。
在本質上 , 在不同層之間分配學習率 , 或者對單個層進行縮放 , 都依賴于我們對網絡輸出對權重的Lipschitz敏感性的理解 。
我們在搭建網絡的過程中會追蹤這種敏感性 , 而流形約束有助于我們更加精準地把握它 。
參考資料:
https://thinkingmachines.ai/blog/modular-manifolds/
本文來自微信公眾號“新智元” , 作者:新智元 , 編輯:元宇 , 36氪經授權發布 。
推薦閱讀













- 剛剛,Meta挖走OpenAI清華校友宋飏,任超級智能實驗室研究負責人
- 機器狗腿被鋸了也能繼續走!最新機器人大腦來自320億估值獨角獸
- AI芯片廠商Groq完成7.5億美元融資,投后估值69億美元
- 賣出550萬枚智能戒指!可穿戴黑馬被曝新融資,沖刺百億美元估值
- 突破后訓練瓶頸?Meta超級智能實驗室力作:CaT解決RL監督難題
- 亞馬遜開建AGI實驗室,一號位也是華人
- AI芯片獨角獸一年估值翻番,放話“三年超英偉達”,最新融資53億超預期
- 390億美元,全球具身智能第一估值來了,英偉達持續加注中
- 來自MIT最強AI實驗室:OpenAI天才華人研究員博士畢業了
- Nothing完成2億美元C輪融資,估值達13億美元|最前線