
文章圖片

文章圖片
文章圖片
文章圖片

文章圖片
文章圖片

文章圖片
文章圖片
趙天辰 , 清華大學電子工程系高能效計算實驗室研究生 , 研究方向主要是:面向視覺生成的高效算法 , 與軟硬件協同設計 。 以下工作為趙天辰在字節跳動-Seed視覺部門實習期間完成
近年來 , 隨著視覺生成模型的發展 , 視覺生成任務的輸入序列長度逐漸增長(高分辨率生成 , 視頻多幀生成 , 可達到 10K-100K) 。 與輸入序列長度呈平方復雜度的 Attention 操作 , 成為主要的性能瓶頸(可占據全模型的 60-80% 的開銷) , 有明顯的效率優化需求 。 注意力的稀疏化(Sparse Attention)與低比特量化(Attention Quantization)為常用的 Attention 優化技巧 , 在許多現有應用中取得優秀的效果 。 然而 , 這些方法在視覺生成模型中 , 在低稠密度(<50%)與低比特(純 INT8/INT4)時面臨著顯著的性能損失 , 具有優化的需求 。
本文圍繞著視覺任務的 “局部性”(Locality)特點 , 首先提出了系統的分析框架 , 識別出了視覺生成任務 Attention 優化的關鍵挑戰在于 “多樣且分散” 的注意力模式 , 并且進一步探索了該模式的產生原因 , 并揭示了多樣且分散的注意力模式 , 可以被統一為代表 “局部聚合” 的塊狀模式 。 然后 , 提出了一種簡單且硬件友好的離線 “Token重排” 方案以實現注意力模式的統一化 , 并設計了針對性的稀疏與量化方法 , 配合高效的 CUDA 系統設計 , 展現了更優異的算法性能保持與硬件效率提升 。 最后 , 本文討論了該方案更廣泛的應用空間 , 與對視覺生成算法設計的啟發 。
- 論文標題:PAROAttention: Pattern-Aware ReOrdering for Efficient Sparse and Quantized Attention in Visual Generation Models
- 論文鏈接:https://arxiv.org/abs/2506.16054
- 項目主頁:https://a-suozhang.xyz/paroattn.github.io/
1. 分析框架:關鍵問題與如何利用局部性(Locality)
如上文所述 , 一系列現有的注意力稀疏化與低比特量化方案已取得了進展 , 但是還存在著一定的挑戰與改進空間:
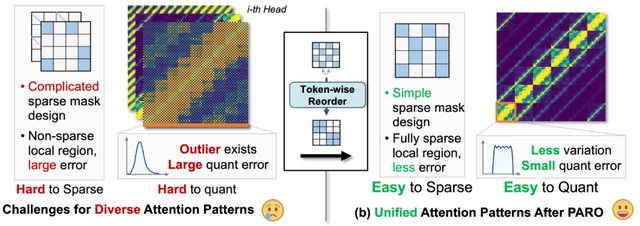
對于稀疏化 , 一系列現有方案(DiTFastAttn , SparseVideoGen , Sparse-vDiT)嘗試依據視覺注意力圖的獨特模式 , 設計針對性的稀疏掩碼(Sparse Mask , 如 “窗口狀的” , “多對角線” , “垂直線的”) , 并將其進行組合 。 然而 , 適配多樣且分散的注意力模式 , 給稀疏掩碼的設計與選擇機制帶來了嚴峻的挑戰 。 本文嘗試采用另一種視角與方法 , 并不涉及復雜的掩碼選擇機制來適配復雜多樣的注意力模式 , 而是設計方案 “重整注意力模式” 。 讓多樣且復雜的注意力模式 , 統一為硬件友好的塊狀注意力模式 , 讓稀疏方案設計更加簡單有效 。
對于低比特量化 , 現有方案(SageAttention 系列)SageAttentionV2 可以將 Attention 中的 QK 計算(Query 與 Key 的乘法)降低至 INT4 , 但是 PV(AttentionMap 與 Value 的矩陣乘)計算仍然需要保持為較高的 FP8 。 最新版本的 SageAttentionV3 采用了 FP4 量化 , 但僅在最新的 B 系列 Nvidia GPU 上有支持 。 本文嘗試分析了更低位寬的定點量化(全流程 INT4)的關鍵問題 , 并給出了解決方案 。
圖:本文(PAROAttn)的優化思路:重整注意力圖以便稀疏與量化處理
為尋找 Attention 稀疏與量化的統一解決方案 , 本文嘗試分析 Attention 效率優化中稀疏與低比特量化的關鍵問題 , 來自于視覺注意力圖多樣且分散的獨特數據分布 (如下圖左側所示):
稀疏注意力方案設計需要從 2 方面考慮:保持算法性能 , 與提升硬件效率 。
- 從算法性能角度 , 需要避免在稀疏過程中錯誤的刪除重要值 。 由于視覺注意力模式存在多樣的結構(對角線 , 縱向 , 塊狀等) , 且這些特征隨著不同的時間步 , 不同的控制信號而動態變化 。 因此 , 注意力模式的多樣性 , 與動態變化 , 導致設計的掩碼難以完全涵蓋重要值 , 對算法性能的保持帶來困難 。
- 從硬件效率角度 , 需要設計 “結構化” 的稀疏掩碼 , 以跳過整塊計算來獲得實際硬件收益(任意不規則稀疏需要引入額外的索引操作 , 且可能導致計算負載零散 , 使得加速收益折損) 。 特別的 , 由于 FlashAttention 涉及逐塊進行注意力計算 , 因此稀疏化的過程中 , 也應考慮如何與其適配 。 由于視覺注意力圖的模式 , 往往不與 FlashAttention 中的分塊所對應(對角線模式中 , 每個塊中僅有少量較大值) 。 因此 , 注意力圖模式的分散性 , 使得結構化稀疏難以取得 , 難以獲得有效的硬件效率提升 。
對于低比特量化算法的設計:關鍵問題為如何盡量減少量化損失 。
- 現有工作(如 ViDiT-Q)已經分析并指出了低比特量化的關鍵誤差來源在于 “量化組內的數據分布差異” , 對于注意力量化 , 為適配 FlashAttention , 需要選擇塊狀的量化分組 。 然而 , “對角線式” 的視覺注意力模式 , 導致塊狀的量化分組中 , 對角線上的元素成為離群值 , 帶來了巨大的組內數據差異 , 而導致了顯著的量化損失 。 因此 , 視覺注意力模式的數據分布 , 導致了顯著的量化損失 。
圖:視覺生成稀疏與量化的關鍵問題來自于多樣分散的注意力模式 , 與本文的解決方案:采用Token重排以改進注意力圖為統一的分塊模式
為解決視覺注意力圖多樣且分散的獨特數據分布給注意力稀疏與量化所帶來的挑戰 。 本文的技術路線為:對注意力圖進行 “重整”(Reorganize) , 以獲得更加統一且易處理的注意力模式 。
受到視覺特征提取具有 “局部性” 的先驗啟發(CNN , SwinTransformer 的設計理念 , 與 Hubel 與 Wiesel 的生物學實驗) , 本文進一步分析了視覺注意力模式多樣性的產生原因 , 并發現了 “多樣的視覺注意力模式本質上都在描述空間上的局部聚合” 。
如下圖所示 , 在 Transformer 的處理過程中 , 原本三維空間(F - 幀數 , H , W - 每幀的圖像寬高)會被轉化為一維的標記序列(Token Sequence) , 按照默認的 [FHW
的順序排列 。 這會導致在除了內存上連續的最后一維(W)之外維度的三維空間相鄰像素 , 在標記序列中呈現為按照一定的間隔排列 。
因此 , 多對角線的注意力模式 , 本質上是在描述 “其他維度上的局部聚合” , 并可以通過Token順序的重排列 , 轉化為代表局部聚合的塊狀模式(將局部聚合的維度轉化為內存上連續的維度 , 如 [FHW
-> [FWH
) 。
本文進一步驗證了 , 每個不同的注意力頭(Head) , 在不同情況下 , 呈現出一致的在某個維度上的局部聚合 , 進而可以通過為每個 head 選取合理的Token重排(Token Reorder)方案 , 將多樣且分散的注意力模式 , 轉化為統一的 , 硬件友好的塊狀模式 , 以便于 Attention 的稀疏與量化 。 該方案利用了算法側視覺特征提取的局部性(更好的數值 Locality) , 并將其與硬件計算的局部性將對應(更好的內存與計算 Locality) , 從而獲得了同時更優的算法性能保持 , 與硬件效率提升 。
圖 視覺特征提取 “局部性” 的示意圖
2. 方案設計
整體框架
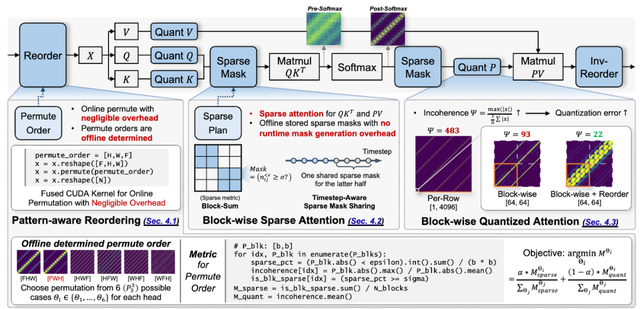
方案流程如下圖所示 , 對 Attention 計算的主要瓶頸 , 兩個大規模矩陣乘(QK 與 PV)都進行了稀疏與量化優化 , 顯著減少其硬件開銷 。 本文基于少量矯正數據離線決定了每個注意力頭(Head)的Token重排方案 , 與對應的稀疏掩碼 , 幾乎不在推理時引入額外的開銷 。 在推理時 , 僅需跳過稀疏掩碼所對應的 attention 分塊 , 并對剩余的部分逐塊進行低比特量化 。
圖 PAROAttention 稀疏與量化方案的流程
Token重排方案(PARO:Pattern-Aware Token Reordering)
本文發現每個不同的注意力頭(Head) , 在不同情況下 , 呈現出一致的在某個維度上的局部聚合 。 因此 , 可以離線地對每個注意力頭 , 選擇恰當的Token重排方式 , 將注意力圖轉化為展示局部聚合的塊狀(Block-wise)模式 。
本文發現了重排列中的一種特殊方式 , 維度置換(Permutation) , 就可以取得不錯的效果 。 對于視頻生成模型的特征 [FHW
, 本文為每個注意力頭 6 種可能的置換方式 , 離線選取最優的置換方式 , 以獲得需要的數據分布方式 。 由于對于注意力稀疏與量化 , 具有不同的數據分布需求 。 因此 , 本文針對稀疏和量化分別設計了重排方式的選取指標 , 并將兩者組合作為最終指標 。
- 稀疏角度:為減小結構化稀疏所帶來的損失 , 要求盡量多的分塊是完全稀疏的(Block Sparse)
- 量化角度:為減少塊內數據分布差異大而導致的量化損失 , 要求塊內數據分布是盡量均勻的(Block Uniform)
如下圖所示 , 稀疏與量化對注意力圖的分布需求不同 , 需要組合兩者需求 , 才能找到同時適合兩者的重排方式 。 經過合適的重排處理之后 , 注意力圖呈現塊狀且較為集中的分布 , 以適配稀疏與量化處理 。
圖:不同重排方式的注意力圖示意
稀疏方案
現有的稀疏注意力方案可分為 2 種方式:(1)動態稀疏方案(如 SpargeAttention)在線依據注意力值生成稀疏掩碼;(2)靜態稀疏方案(如 DiTFastAttn):離線生成稀疏掩碼 。 兩者各有其優劣 。 盡管本方法設計的Token重排(PARO)方案能夠同時幫助動態與靜態方案 , 本文對兩者優劣進行的分析 , 并最終選取了靜態稀疏方案 , 作為 PAROAttention 的主要稀疏方案 , 具體分析如下:
對于動態稀疏(Dynamic Approach):
- 在性能保持方面 , 雖然動態的方案能夠自然適配動態變化的模式 。 但是由于需要在線產生稀疏掩碼 , 只能基于 Softmax 之前(Presoftmax)的注意力值 , 它們的相對均勻 , 不呈現明顯模式 , 難以準確的識別出對應模式 。
- 在硬件效率方面 , 動態稀疏方案引入了在線計算出稀疏掩膜的額外開銷(overhead) , 該開銷與掩膜預測的準確度互為權衡 , 若要獲得準確的掩膜 , 則需要引入相對較大的額外計算 。 該額外預測過程 , 一般需要精細設計的 CUDA Kernel 才能夠獲得較高的效率收益 。
- 總結來看 , 在較低稀疏比下 , 動態稀疏方式的準確性與效率提升存在瓶頸 , 因此本文訴諸靜態稀疏方案 。
對于靜態稀疏(Static Approach):
- 在性能保持方面 , 由于靜態確定的注意力圖 , 難以適配多樣且動態變化的注意力模式 , 因此靜態稀疏方案通常會造成相比動態方案更顯著的性能損失 。 然而 , PAROAttention 的注意力圖重整 , 已將多樣動態變化的注意力模式 , 轉化為了規整且統一的模式 , 解決了這一靜態稀疏的關鍵挑戰 。 因此 , 通過利用模式更明顯的 Softmax 后注意力圖 , 能夠獲得比動態方案更優的算法性能保持 。
- 在硬件效率方面 , 雖然避免了在線計算出稀疏掩膜的額外計算開銷 , 但是離線稀疏掩碼會帶來額外的顯存開銷 。 本文針對該問題進行了對應優化(見下文 “CUDA 系統設計” 部分) 。
經過重排列處理之后 , 注意力圖呈現出統一的集中的分塊模式 。 因此 , 本文僅需離線統計每塊中的 attention 數據之和 , 并設計閾值判斷當前塊是否需要被跳過(該閾值可以用于調節稠密度) , 就可以離線獲取到稀疏掩碼 , 在推理時不引入任何額外開銷(overhead) 。 如下圖所示 , 相比其他現有的靜態注意力稀疏方案 , 由于預先對注意力模式的統一化 , PAROAttention 避免了復雜且受限的掩膜設計 , 而能夠與原圖非常契合的稀疏掩膜 。
量化方案:
對于低比特量化 , 評估量化損失的關鍵指標是分組內的數據差異 , 現有文獻通常采用不均衡度(Incoherence)進行衡量 , 被定義為當前數據組中的最大值 , 除以平均值(x.max () /x.abs ().mean ()) 。 經過合適的Token重排之后 , Attention Map 塊內的顯著數據差異得到明顯緩解 , 從而可以支持更低位寬的量化 。
CUDA 系統設計
最小化額外開銷:PAROAttention 所引入的額外開銷主要有以下兩方面 , 本文在系統層面進行了針對性優化以最小化額外開銷 。
- 在線的Token重排開銷:雖然重排方式離線確定 , 但是Token重排的過程(維度置換)需要在線進行 。 為了避免一次顯示的從 GPU Global Memory 到 Shared Memory 的內存搬移開銷 , 本文進行了算子融合(Layer Fusion)的操作 , 僅修改重排前算子寫入地址的順序 , 所引入的額外開銷可忽略 。
- 靜態稀疏掩碼的顯存開銷:由于注意力圖體量較大 , 離線決定的稀疏掩碼 , 可能會占用 GB 級別的 GPU 顯存 。 為減少該開銷 , 本文采用了預?。 ≒refetch)策略 , 通過新建一個 CUDA Stream , 在每次運算時 , 只讀取當前層的稀疏掩碼 , 可以將額外的顯存開銷降低到若干 MB 級別 。
兼容性:PAROAttention 的稀疏與量化方案都逐塊處理 , 可直接與兼容 FlashAttention 。 由于重排與稀疏掩碼均離線完成 , 無需精細的 CUDA Kernel 優化 , 僅需基于 FlashAttention 進行跳過整塊計算的支持 , 能夠廣泛適配各種場景 。
3. 軟硬件實驗結果
算法性能保持效果
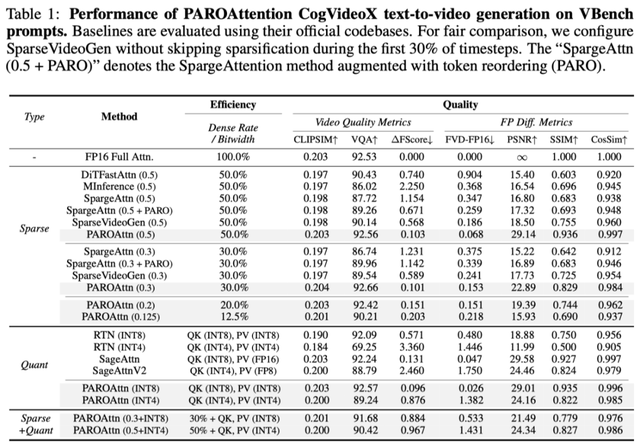
本文在主流視頻(CogVideo)與圖片生成模型(Flux)上測試了多方面指標 , 包括了:
- 視頻質量指標:CLIPSIM 衡量語義一致性;VQA 衡量視頻質量;FlowScore 衡量時間一致性;
- 與浮點生成差異:如 FVD-FP16 衡量特征空間差異 , PSNR/CosSim 衡量像素空間差異 , SSIM 衡量結構相似性 。
典型的實驗結論概括如下:
(1)其他基線的稀疏方案在相對較高稀疏比(50%)時 , 仍會造成可觀的質量損失 , 包括內容變化 , 圖像模糊等;而 PAROAttention 的稀疏化方案 , 可以在 20% 的較高稀疏比情況下 , 依然生成和浮點結果非常相似的結果 , 獲得比基線方案 50% 更好的多方面指標 。
(2)Token重排方案 PARO , 并不局限于靜態稀疏方案 。 其與動態稀疏方案 SpargeAttention 能夠直接適配 , 并提升生成效果 。 將 30% 稠密度的 SpargeAttention 組合 PARO , 可以獲得與 50% 稠密度 SpargeAttention 同等的生成質量 。 將加速比從 1.67x 提升至 2.22x 。
(3)相比于 SageAttentionV2(QK INT4 , PV FP8) , PAROAttention 的量化方案可以在無精度損失的情況下 , 進一步將 PV 量化到 INT4 。
(4)PAROAttention 的稀疏與量化方案可以并行使用 , 最激進的優化方案(50%+INT4)相比浮點能取得近 10 倍的 Attention 部分延遲優化 , 同時獲得與僅能取得 2x 左右延遲優化的基線方法類似的算法性能保持 。
硬件加速效果
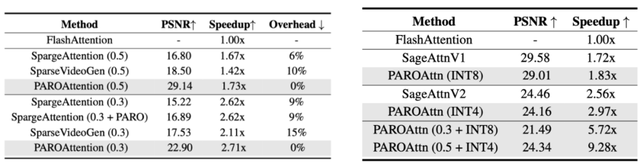
本文進一步對系統層面優化技巧進行了分析 , 關鍵實驗結論如下:
(1)PAROAttention 的稀疏方案 , 同時取得了更優的算法性能保持與效率提升 。 以 50% 稠密度為例 , PAROAttention 取得了 1.73x 的 attention 加速 , 超過同等情況下的 SpargeAttention(1.67x)與 SparseVideoGen(1.42x) , 由于靜態稀疏方案幾乎不會引入額外開銷 , 而基線方案的在線稀疏掩膜生成 / 選擇會造成 6% 到 10% 左右的額外開銷 , 該開銷在更低稠密度下顯得給更為明顯 。
(2)PAROAttention 的加速比與理論上限較為接近(50% 稠密度 , 理論 2 倍 , 實際 1.73 倍) , 凸顯了方案的硬件友好性 。
(3)PAROAttention 的各方面額外開銷 overhead 得到了有效減少 , 控制在整體的 1% 之內 。
總結與未來指引
【清華、字節提出Token Reorder,無損實現5倍稀疏、4比特量化】總結來看 , 本文關注了視覺生成任務的 “局部性” 特性 。 通過一個簡單且有效的Token重排操作 , 可以同時實現算法側視覺特征提取的局部性(更好的數值 Locality) , 并將其與硬件計算的局部性相對應(更好的內存與計算 Locality) , 從而獲得了同時更優的算法性能保持 , 與硬件效率提升 。 PAROAttention 的方案主要圍繞推理效率優化設計 , 但是采用Token重排來更好利用特征提取局部性的思想并不局限于推理優化中 。 不同的注意力頭自主的學習到在不同維度上的局部聚合 , 可以啟發優化訓練方法 , 與圖像的參數化方式 , 三維空間的位置編碼設計 , 并進一步推動具有合理歸納偏置(Inductive Bias)的視覺基座模型的構建 。
推薦閱讀













- 大疆發布 DJI FC100 旗艦運載無人機,80kg最大載重、9分鐘快充
- 銳龍AI Max迷你工作站上市:AI本地開發部署首選、萬元級高性價比
- 一呼百應!騰訊、金山、阿里等巨頭,紛紛支持鴻蒙電腦系統
- 你的耳機在被偷聽!20+音頻設備曝出漏洞:索尼、Bose、JBL等淪陷
- 8000mAh電池、衛星通信、無線充電、側邊指紋,這是不是最猛中端機?
- 賣出千萬美金,前云鯨高管創立的割草機器人再融資、三個月累計金額近億|硬氪首發
- 入門顯卡RTX 5050首次跑分!不敵RTX 4060、頻率有驚喜
- 年出貨16億顆,全球第4、中國大陸第1的手機芯片廠,要上市了
- 小米AI眼鏡深度體驗:續航長、軟件強,但工程機味道濃
- vivo、OPPO持霸榜,小米第三,W25周排名出爐