
文章圖片
文章圖片
文章圖片
文章圖片

文章圖片
朱昆侖是伊利諾伊大學香檳分校(UIUC)計算機科學系的研究生 , 現隸屬于Ulab與Blender Lab , 曾在斯坦福大學、卡內基梅隆大學(CMU)與蒙特利爾學習算法研究所(Mila)進行學術訪問 。 他的研究方向包括大語言模型(LLM)智能體、多智能體系統、AI科學家與工具學習等 , 在ICML、ICLR、ACL、TMLR等頂級會議與期刊發表論文10余篇 , 總引用超過1500次 。他積極參與多個廣泛影響的開源項目 , 包括 OpenManus(RL)、ChatDev(MACNET)、ToolBench 等 , 累計在 GitHub 上獲得超過 5萬+ stars 。 此外 , 他曾受邀在 AMD 開發者大會、阿里巴巴云棲大會等重要學術與工業會議中作報告 , 分享其在AI智能體方面的開源成果 。
我們正在見證一個全新的時代:AI 的浪潮從強大的「個體」奔涌向復雜的「團隊」 , 它們像人類團隊一樣協作開發軟件、進行科學研究 , 甚至在虛擬世界中展開激烈的策略對抗 。
然而 , 一個問題也隨之浮出水面:我們如何判斷這些 AI 團隊是「三個臭皮匠 , 賽過諸葛亮」 , 還是「三個和尚沒水喝」?
現有的評測基準 , 如 AgentBench、GAIA 等 , 大多聚焦于單個智能體的推理和工具使用能力 , 卻無法衡量多智能體系統內部至關重要的協作效率、溝通質量和競爭策略 。 這在 AI 能力評估領域 , 形成了一個巨大的「盲區」 。
為了填補這一空白 , 來自伊利諾伊大學厄巴納-香檳分校的研究者們 , 近日推出了 MultiAgentBench 。 該成果近日被自然語言處理頂級會議 ACL 2025 主會正式接收 。
- 論文標題:MultiAgentBench:Evaluating the Collaboration and Competition of LLM agents
- 論文鏈接:https://arxiv.org/pdf/2503.01935
- 代碼鏈接:https://github.com/Ulab-UIUC/MARBLE
這不僅是一個評測集 , 更是首個能夠全面、系統化地評估 LLM 多智能體系統協作與競爭能力的綜合性基準 。 它不僅僅是一套「考題」 , 而更像一個「模擬真實社會動態的實驗室」 , 旨在揭示多智能體協作的奧秘 , 并回答一系列關鍵問題:
- 智能體的能力與協作 , 哪個更重要?
- AI 團隊采用哪種組織架構和協作策略效率最高?
- 當 AI 被賦予共同或者沖突的目標時 , 它們會演化出怎樣的社會行為?
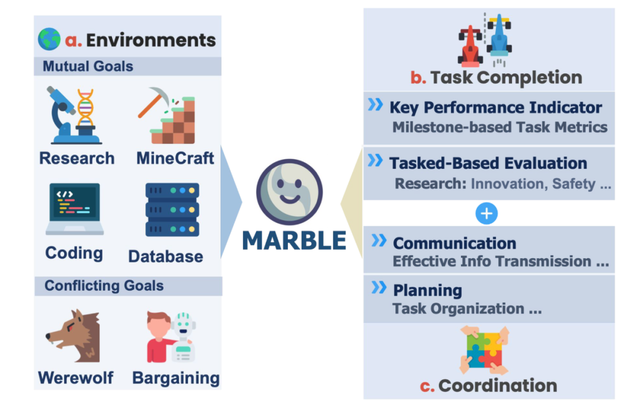
圖 1:MultiAgentBench 評估流程概覽
MARBLE 的主要貢獻包括:
- 提出了 MultiAgentBench 這一綜合性基準 , 在六種多樣化交互場景中評估基于 LLM 的多智能體系統的協作與競爭 。
- 提出了創新的評估指標:不僅評估任務的完成質量 , 還衡量智能體的協作、規劃與溝通的質量 。
- 揭示了多智能體協作中的一些「頓悟時刻」——智能體開始展現出涌現的社會行為 , 為實現類 AGI 級別的協作帶來了有希望的啟示 。
研究結果揭示了幾個關鍵結論:在眾多模型中 , gpt-4o-mini 展現出最強的綜合任務能力;在協作模式上 , 「圖結構」的去中心化協作模式效率最高;而在規劃策略上 , 相比于「小組討論」等規劃方法 , 「認知自演化規劃」方法能有效提升任務達成率 。 更重要的是 , 實驗觀察到了智能體在復雜博弈中自發產生的「社會智慧」 。
圖 2:MARBLE 核心框架設計展示
框架設計
MultiAgentBench 的核心在于其背后的協作引擎 MARBLE (Multi-agent coordination Backbone with LLM Engine) 。 它將評測重點從單個智能體能力拓展到智能體之間的關系動態與組織結構 , 使研究者能夠系統性分析多智能體協作和對抗過程中的效率與行為模式 。 在多智能體系統中 , 如何高效組織和協作 , 可能與個體能力同樣重要 。
圖 2 展示了 MARBLE 的整體架構 , 其中包含三個核心模塊:
協作引擎
協作引擎作為整個系統的大腦中樞 , 負責整合并調度所有模塊 , 明確區分「規劃者」(Planners) 和「執行者」(Actors) 的角色 。 這種分工幫助實現從整體規劃到具體執行的順暢銜接 , 使評測能夠更好地觀測協作效率與執行效果 。
智能體圖
智能體圖模塊不僅記錄智能體是誰 , 還通過 (agent1 關系 agent2) 的三元組形式 , 建立起智能體之間的關系網絡 , 包括「協作」、「監督」等 。 這種結構化關系使得智能體之間的互動具有可控性和方向性 , 更接近真實團隊中的組織架構 。
認知模塊
認知模塊為每個智能體提供個性化信息、獨立的記憶 , 以及多樣化的推理方式 , 使其能夠根據上下文和交互過程靈活調整策略 , 而非簡單執行固定指令 。 這一設計使智能體在多智能體環境中展現出更具適應性和靈活度的行為 , 為研究智能體間協作與互動提供了支持 。
交互策略與環境
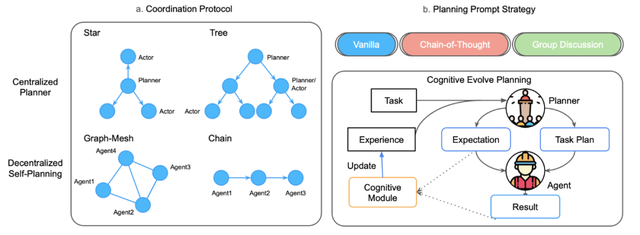
圖 3:(a) 協作協議(如星型、樹型、圖結構與鏈式);(b) 規劃策略 。
交互策略
MARBLE 框架內置了四種協作協議 , 如圖 3 所示 , 包括中心化協議(星型、樹型)與去中心化協議(圖型、鏈型) , 來模擬現實世界中典型的團隊協作模式 。
評測場景
MultiAgentBench 設計了六個覆蓋不同領域的評測場景 , 全面模擬了從團隊合作到利益沖突的各種應用環境:
- 共同目標:
- 科研 (Research):AI 科學家團隊 , 合作撰寫研究報告 。
- 我的世界 (Minecraft):AI 游戲團隊 , 合作完成游戲目標 。
- 數據庫 (Database):AI 數據庫工程師團隊 , 合作完成數據庫開發項目 。
- 編程 (Coding):AI 軟件工程師團隊 , 合作完成軟件工程開發項目 。
- 沖突目標:
- 狼人殺 (Werewolf):模擬狼人殺游戲 。 AI 智能體需要進行欺騙和偽裝來獲得游戲勝利 。
- 談判 (Bargaining):模擬真實的商業談判場景 。 AI 智能體需要在資源有限的情況下 , 通過策略性的讓步、聯盟或施壓 , 為自己爭取最大的利益 。
評價指標
圖 4:基準創建過程及動態里程碑檢測機制 。
任務完成度
- 基于里程碑的 KPI (Milestone-based KPI):這是 MultiAgentBench 評測體系的一大亮點 。 它不再將任務視為一個整體 , 而是將其分解為一系列關鍵的「里程碑」(例如 , 在科研任務中 , 「完成 5 個關鍵問題的定義」或「對上一版提案進行實質性改進」) 。 系統通過一個 LLM 裁判 , 動態地檢測團隊是否達成了這些里程碑 , 并自動記錄做出核心貢獻的智能體 。
- 任務得分 (Task Score , 以下簡稱 TS):這是對多智能體系統最終產出質量的綜合評分 , 會根據任務類型(如科研、編程、游戲勝負)采用不同的評價標準 。
協作質量
這是對團隊「軟實力」的量化評估 , 由兩個核心分數構成:
- 溝通分數 (Communication score):評估團隊內部溝通的效率、清晰度以及信息的有效傳遞 。
- 規劃分數 (Planning score):評估任務分配的合理性、角色維護的一致性以及戰略的連貫性 。
- 協作總分 (Coordination Score 以下簡稱 CS):上述兩者的平均值 , 直觀地反映了團隊的整體協作水平 。
實驗結論
高效的協作 ≠ 優異的成果 , 個體能力是基石
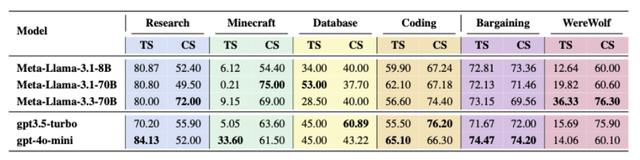
表 1:Minecraft、Database、Coding、Bargaining 與 Werewolf 五個場景中的平均 TS 與協作 CS 。 在三個任務場景中 , 均為同一模型同時取得最高 TS 與 CS , 表明 CS 是衡量 TS 的良好指標 。
溝通順暢、配合默契的 AI 團隊是否就能更加高質量地完成任務?直覺告訴我們「是的」 , 但實驗數據(如表 1 所示)卻指出——在多智能體系統中 , 協作與個體能力并非總能齊頭并進 。
例如 , 在 Minecraft 任務中 , Meta-Llama-3.1-70B 模型展現出了高達 75.00 的 CS , 但其最終的 TS 僅為 0.21 。 協作分高 , 意味著智能體之間在頻繁、清晰地溝通 , 并嚴格遵循著既定規劃 。 但如果單個智能體的某項執行能力存在根本性缺陷 , 那么再完美的溝通和規劃 , 也是空中樓閣 。
這表明 , 在當前階段 , 多智能體系統的性能瓶頸首先在于單個智能體的核心能力 。 協作是能力的「放大器」 , 而非能力的「替代品」 。
AI 團隊的「組織內耗」:警惕冗余層級與無效討論
圖 5:不同協作協議在多種評估指標下的表現 。
圖 6:不同規劃提示策略下研究任務的平均指標 。 認知自演化規劃在 CS 上表現最佳 。
如圖 5 所示 , 在四種協作協議中 , 圖結構這種允許所有智能體自由溝通、并行協作的模式 , 在任務得分、規劃質量和效率上全面占優 , 緊隨其后的是星型 , 而表現最差的是樹型結構 , 其層級過多的設計 , 導致溝通成本和信息損耗急劇增加 , 任務得分和協作分均為最低 。 這表明 , 對于需要復雜協作的任務 , 扁平、去中心化的組織架構比層級結構更有效 。
如圖 6 所示 , 一個反直覺的結論出現了:讓多個 AI 規劃師進行「小組討論」 , 效果竟是所有策略中最差的 。 這或許說明 , 當前階段的 AI 的小組討論不僅沒能集思廣益 , 反而可能陷入「集體降智」 。 與之形成對比的是 , 進行「認知自演化規劃」的智能體表現出最佳的協作能力 。 這種策略的核心在于「復盤」——從過去的成敗中學習 , 動態調整策略 , 實現持續進化 。 對于 AI 團隊而言 , 一個懂得自我迭代和反思的「大腦」 , 比一場七嘴八舌的「頭腦風暴」更加寶貴 。
AI 團隊的「林格曼效應」
【頂尖AI如何發揮最大戰力?UIUC用一個新多智能體協作基準尋找答案】
圖 7:不同智能體數量對 KPI、CS 與 TS 的影響 。
在探究團隊規模的影響時 , 實驗發現 , 將智能體數量從 1 個增加到 3 個時 , 協作分數和任務分數得到了提升 。 然而 , 當繼續增加智能體數量時 , 整體的 KPI 反而開始下降 。
這一現象與組織行為學中的「林格曼效應」(團隊規模越大 , 個體貢獻越傾向于減少)高度吻合 。 團隊規模的擴大并非簡單的「人多力量大」 , 這意味著 , 未來構建大規模 AI 智能體系統的關鍵 , 將是如何設計出高效、低開銷的協作機制 , 以克服規模擴張帶來的內在復雜性 。
「Aha-Moments」:當 AI 開始展現社會智慧
MultiAgentBench 最重要的發現 , 或許是在「狼人殺」和「談判」這類競爭性場景中 , 觀察到的一系列驚人的「涌現行為」 。 這些復雜的社會策略并非由人類編碼設計 , 而是 AI 為了贏得勝利這一最終目標 , 自發「學習」和「演化」出來的 。
- 戰略性沉默:在「狼人殺」游戲中 , 「預言家」智能體學會了不再第一時間公布自己的驗人結果 。 它會評估風險 , 選擇性地、在最關鍵的時刻才披露信息 , 以求最大化收益并保護自己 。 這是一種基于風險評估的「戰略性沉默」 , 是高級博弈能力的體現 。
- 信任與猜忌:實驗中 , 村民陣營會因為內部猜忌而產生「內斗」 , 互相攻擊;而狼人陣營則能通過高度一致的欺騙和內部協作 , 制造「虛假共識」來迷惑對手 。 這表明 , 智能體正在根據角色和信任關系 , 自發地形成動態的聯盟和敵對關系 。
- 動態適應環境:游戲中的「女巫」角色 , 其行為策略會隨著戰局的演進而動態變化 。 在游戲早期 , 它傾向于「囤積」寶貴的藥水;而到了游戲后期 , 為了求勝 , 它會變得更具「冒險精神」 。 這展示了智能體策略的高度動態性和對環境的適應性 。
這些「Aha-Moments」標志著 LLM 智能體正在經歷一次從純粹的「邏輯推理機器」 , 向具備初級社會行為能力的角色的轉變 。 它們正在學習和運用人類社會互動中最核心的元素:欺騙、信任、策略和權衡 。 當一個智能體開始思考「其他智能體正在思考什么」時 , 這正是「心智理論」的雛形 。
總結
MultiAgentBench 的推出 , 為我們打開了一扇觀察和理解 AI 群體智能的窗戶 。 它不僅僅是一個評測工具 , 更是一個強大的「社會模擬器」 , 系統性地揭示了構建高效 AI 團隊的幾條重要準則:
- 個體能力是基石:協作是能力的放大器 , 而非替代品 。 沒有強大的個體 , 再好的團隊協作也只是空中樓閣 。
- 組織結構定成敗:扁平、去中心化的網絡結構勝于層級的樹型模式 , 后者會帶來巨大的「組織內耗」 。
- 規模并非多多益善:AI 團隊同樣受「林格曼效應」的約束 , 盲目擴大規模反而會降低效率 , 如何設計低成本的協作機制是關鍵 。
- 社會智能的涌現:在合適的博弈環境下 , AI 能夠自發學習并展現出「戰略性沉默」、「信任分化」等高級社會行為 , 這是通往更高級別人工智能的希望所在 。
總而言之 , 這項工作標志著我們對 AI 的研究 , 正在從關注「個體智商」邁向理解「群體情商」的新階段 。 未來 , 通過構建更復雜的交互環境 , 我們將能更好地理解、引導并最終利用這種強大的新興智能 , 為解決現實世界中的復雜問題 , 邁出堅實的一步 。
推薦閱讀













- 國補下半場激戰來襲,智能投影如何從 “浪潮” 里撈走更多真金?
- 18A工藝該發揮實力了:英特爾新款至強可擁有192核心
- V·STAR頂尖人才計劃|頂薪+期權,與VAST一起定義下一代3D范式
- 三次賣到斷貨,榮耀新旗艦如何成為“真香機”?
- EUV,是如何工作的?
- 如何用DeepSeek做數據分析?這套方法超神!
- 十年AI醫療實戰復盤:無光環、無資本,我們如何靠「真痛點」撕開市場?
- 潘春節解密“雙軌并驅”:機械革命如何在PC紅海殺出重圍
- 當石頭科技碰上頂尖藝術院校:冰冷的電器硬件變了
- 96Gbps超高帶寬加持!HDMI 2.2規范如何賦能顯示終端新一輪創新革命