
文章圖片

文章圖片
文章圖片
文章圖片
文章圖片

近日 ,螞蟻集團知識引擎團隊協同浙江大學、同濟大學正式發布了其在結構化推理領域的最新成果 —— KAG-Thinker 模型 , 該模型是 KAG 框架的重要迭代升級 , 聚焦于為通用或專業領域復雜推理任務構建穩定、可解釋的思考范式 。
2025 年以來 , OpenAI 推出的 Deep Research 展示了大模型在復雜推理任務中多輪檢索、規劃推理的強大能力 。 隨后 , 產學界涌現了較多以模型為中心 (Model-Centric) 的方法 , 比如 Search-R1、ReSearch 等 。 它們的核心思路是 , 通過強化學習讓模型自己 “學會” 如何檢索和利用外部知識 , 從而讓小模型也能像專家一樣 “思考” 。 然而 , 這些基于自然語言的推理方法就像讓模型 “自由發揮” , 推理不嚴謹、過程不穩定等問題依然突出 。 而人類專家解決復雜問題時 , 往往采用結構化的思考方法 , 把原始問題拆解成多個可獨立驗證的小問題 , 并依次求解 。受此啟發 , 研究團隊提出了 KAG-Thinker , 為模型的思考過程建立一套清晰、分層的 “腳手架” , 從而提升復雜任務中推理過程的邏輯性與穩定性 。
- 技術報告:https://arxiv.org/abs/2506.17728
- Github:https://github.com/OpenSPG/KAG-Thinker
- Huggingface: https://huggingface.co/OpenSPG/KAG-Thinker-en-7b-instruct
【KAG-Thinker:結構化思考新范式,支持邏輯嚴謹的大模型復雜推理】該模型延續了 KAG 框架 Logical Form 自然語言與邏輯函數雙語義表示機制 , 以更好地利用結構化知識;并通過廣度拆分與深度求解相結合的方式 , 提升問題求解的嚴謹性;同時引入以知識點對齊為中心的知識邊界判定機制 , 以充分利用大模型參數化知識與外部形式化知識 , 并借助內容抗噪模塊降低檢索信息噪聲 , 增強檢索內容的可信度 。
視頻 1 KAG-Thinker 與 KAG 框架集成 , 「結構化思考」引導的 「深度推理」 問答產品示例
最終 , 研究團隊將上述策略集成于一個支持多輪迭代與深度推理的統一架構中 , 通過監督微調方法訓練出 KAG-Thinker 7B 通用模型 。
實驗結果顯示 , 在 7 個單跳和多跳推理數據集上 , 其性能相較使用強化學習 Search-R1、ZeroSearch、ReSearch 等 SOTA 深度搜索方法平均提升了 4.1% 。 與 KAG 框架集成后在多跳推理任務上超越 HippoRAG V2、PIKE-RAG 等 In-Context Learning(以 Qwen2.5-72B 為基模)方法 。 此外 , 模型也在醫療問答任務中驗證了其在專業領域中的有效性 。 其他專業領域的精細化定制 , 可以參考其在醫療問答上的應用及表現 。
圖 1 KAG-Thinker 語料合成和模型訓練過程概覽
模型方法
模型的架構如下圖所示 。 模型的核心內容包括:
圖 2 復雜問題求解概覽圖
廣度拆分 + 深度求解:應對復雜決策任務
復雜多跳問題通常需拆分為多個簡單子問題 , 以更高效地利用外部知識庫進行求解 , KAG-Thinker 提出了一種 「廣度拆分 + 深度求解」 的方法(詳見圖 2):
廣度拆分 :將原始問題分解為若干原子問題 , 各子問題間保持邏輯依賴關系 , 確保拆分的準確性 。 每個原子問題由一個 Logical Form 算子表示 。 每個 Logical Form 具備雙重表示形式 —— 自然語言描述(Step)與邏輯表達式(Action) , 二者語義一致 。
深度求解 :針對需要檢索 (Retrieval) 的子問題 , 進行深入求解 , 以獲取充足的外部知識保障答案準確 。 在檢索前 , 模型會先執行知識邊界判定:若判斷當前大模型自身知識已足夠回答該子問題 , 則跳過檢索;否則繼續深度求解 。
知識邊界判定:充分利用 LLM 參數化知識
為充分利用大模型的參數化知識、減少不必要的檢索任務 , KAG-Thinker 以知識點(如實體、事件)為中心定義 Retrieval 子任務 , 并通過 SPO 三元組限定檢索粒度 , 以此為基礎判斷大模型與外部知識庫的邊界 。
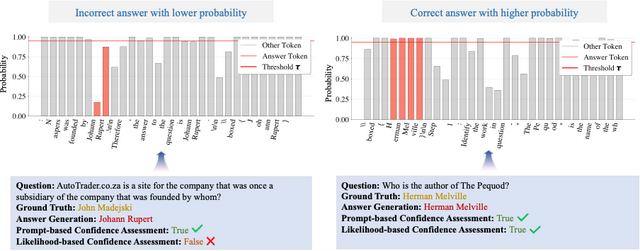
知識邊界判定任務是一個無監督過程:首先讓大模型直接作答子問題 , 再由其判斷該答案是否為真實答案 。 此過程生成兩個標簽:
- 自然語言輸出的判斷結果(True/False);
- 答案首次出現時對應 token 的概率 , 若低于設定閾值則標記為 False , 否則為 True 。
僅當兩個標簽均為 True 時 , 才認為大模型自身知識足以回答該子問題 , 無需額外檢索 , 可直接采用其生成的答案 。
圖 3 知識邊界判定
檢索內容抗噪:提升檢索內容的可信度
對于必須檢索的子問題 , Thinker 需要判斷當前檢索結果是否能求解出對應子問題 。 然而 , 不同檢索器檢索的內容參差不齊 , 尤其是網頁檢索得到的內容 。
為了更好的分析檢索結果 , 檢索抗噪模塊會分析每篇檢索回來的文章與當前子問題的關系 , 去掉一些無關內容 , 再從剩余內容從中提取一些核心信息 , 作為直接給出子問題的答案還是繼續進行深度檢索的依據 。
Logical Form 求解器
在廣度拆分和深度求解時 , Thinker 沿用 KAG 框架中定義的 4 種 Logical Form 求解器 。 每種 Logical Form 算子的定義如圖 4 所示 。 Retrieval 主要解決檢索類的問題 , Deduce 和 Math 主要解決推理分析類問題 , Output 主要用于答案匯總 。
圖 4 4 種 Logical Form 算子的定義
實驗結果
單跳和多跳問答
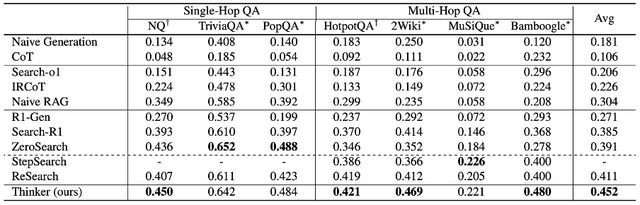
為了評估模型的效果 , 研究團隊選了 7 個通用的單跳和多跳推理數據集 , 并使用相同的檢索器 (E5-base-v2) , Baseline 選擇了最新的 ReSearch、Search-R1、ZeroSearch 和 StepSearch 等 。 并沿用這些 Baseline 方法的評價指標 (EM) 。 為了使用相同的檢索器 , 只使用 Logical Form 表示中的 Step 中的純自然語言的內容 。 整體實驗效果如表 1 所示 。
與無檢索基線相比 , Thinker 模型的平均性能比 Naive Generation 和 CoT 分別高出 27.1% 和 34.6% 。
與檢索增強方法相比 , Thinker 模型的平均性能比 Search-o1、IRCoT 和 Naive RAG 分別高出 24.6%、22.6% 和 14.8% 。
與基于強化學習的方法相比 , Thinker 模型比 SOTA 模型 ReSearch 高出 4.1% 。
具體而言 , 在單跳數據集中平均提升了 4.5% , 在多跳數據集中平均提升了 3.9% 。 主要原因是 , 知識點粒度的檢索任務拆解降低了檢索的復雜性 。
表 1 不同模型 (基座模型 Qwen2.5-7B-Instruct) 在不同數據集上的 EM 性能
KAG 框架升級
KAG V0.8 升級了知識庫的能力 。 擴展了私域知識庫(含結構化、非結構化數據)、公網知識庫 兩種模式 , 支持通過 MCP 協議引入 LBS、WebSearch 等公網數據源 。 此外 , 升級了私域知識庫索引管理的能力 , 內置 Outline、Summary、KnowledgeUnit、AtomicQuery、Chunk、Table 等多種基礎索引類型 , 支持開發者自定義索引 & 產品端聯動 的能力 (如視頻 2 所示) 。
用戶可根據場景特點選擇合適的索引類型 , 在構建成本 & 業務效果之間取得平衡 。 在本次 0.8 的發版中 , KAG 全面擁抱 MCP , 提供接入公網 MCP 服務及在 agent 流程中集成 KAG 推理問答(基于 MCP 協議)的能力 。
視頻 2 可配置化的知識索引構建能力
KAG 框架的應用
KAG 框架 V0.8 版本為 Thinker 模型應用提供支持 , 融入 KAG 框架后的 Thinker 模型 ,Math、Deduce 都使用框架中的求解器進行求解 , 再用 Thinker 模型進行答案匯總 , 可以看到 KAG-Thinker 7B 的平均 EM 和 F1 性能相比于 Thinker 模型平均提升 3.0% , 3.8% 。 這也說明 KAG 框架能更好的幫助 Thinker 模型進行求解 。
表 2 不同模型在自建檢索庫上的性能
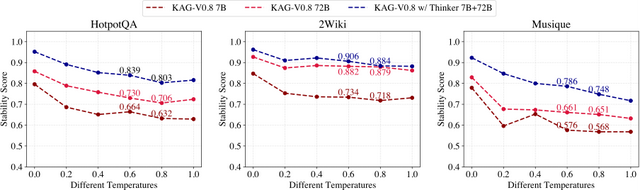
同時 , 針對 KAG 框架問題拆解不穩定的現象 , 也做了問題廣度拆解的穩定性測試 , 將同一個問題 , 拆解兩次 , 如果兩次結果相同 , 則分數為 1 , 否則為 0 。
實驗結果如圖 5 所示 , KAG-Thinker 7B 在 HotpotQA、2Wiki 和 Musique 這三個數據集上的穩定性表現優于 KAG-V0.8 7B 和 KAG-V0.8 72B 。 在常用的溫度參數 0.6 和 0.8 下 , KAG with Thinker 7B+72B 分別相對于 KAG-V0.8 7B 和 KAG-V0.8 72B 平均提升了 17.9% 和 7.6% 。
圖 5 不同溫度參數下不同模型穩定性測試
KAG-V0.8 with Thinker 在三個數據集上的平均性能要優于 HippoRAGV2 和 PIKE-RAG , 詳細的實驗設置參考 KAG-V0.8 release notes 。
雖然 KAG-V0.8 with Thinker 大幅度提升了框架的穩定性 , 但是平均性能要低于 KAG-V0.8 72B , 略高于 KAG-V0.8 32B 。 這說明 7B 的 Thinker 模型的問題拆解能力還有所欠缺 , 分析 BadCase 發現 , 對于一些復雜的問題 , Thinker 模型的拆分能力還不夠 , 例如 「Who is the paternal grandmother of John Iii Duke Of Cleves?」 , 需要分解出 John Iii Duke Of Cleves 的媽媽是誰和 John Iii Duke Of Cleves 的媽媽的媽媽是誰 。
這種問題 Thinker 模型拆分不穩定 , 主要的原因有兩種 , 第一 , LLM 對復雜的純自然語言問題拆分存在不一致 , 第二 , 7B 模型的泛化能力有限 。 為了解決這些問題 , 研究團隊表示將來會從結構化數據中合成問題拆分樣本 , 保證模型拆分的一致性 。
表 3 不同框架在多跳推理上的性能表現
醫療領域的應用
為了驗證該框架在專業領域的能力 , 研究團隊在醫療領域做了一系列的改造 , 訓練出了 KAG-Med-Thinker 。 實驗結果如表 4 所示 , 在 DeepSeek-R1-Distill-Qwen-14B 上 , 與已有的多輪規劃和檢索增強模型 IRCoT 和 ReAct 相比 , KAG-Med-Thinker 分別取得了 3.95% 和 4.41% 的顯著性能提升 。 同時 , 它還比 Naive RAG 自適應檢索模型高出 3.8% 。
表 4、不同模型在 MedQA 上的準確性
推薦閱讀














- AI 與產品工作的思考:重構、挑戰與共生之路
- AI 技術熱潮沖擊,谷歌搜索地位動搖引發的行業變革與思考
- AI需要「像人類」那樣思考?AlphaOne揭示大模型的「思考之道」
- 安卓皮,蘋果骨?OPPO新機全新設計引發深層思考
- 中國團隊讓AI擁有「視覺想象力」,像人類一樣腦補畫面來思考
- 火山引擎密集上新:豆包全新視頻生成模型、視覺深度思考模型,Trae多個重點功能升級
- 從“一碼難求”到被多方質疑 Manus過山車式走紅的冷思考
- 重新思考 6G
- 浙江大學教授陳德人:企業家要盡早思考成為“超級個體”
- 大定3萬!R7持續增漲,華為不給油車思考時間,奇瑞忙到笑出聲!