
文章圖片
LLM用得越久 , 速度越快!Emory大學提出SpeedupLLM框架 , 利用動態計算資源分配和記憶機制 , 使LLM在處理相似任務時推理成本降低56% , 準確率提升 , 為AI模型發展提供新思路 。
在人類的認知世界里 , 熟練意味著更快、更高效 。
比如看似復雜的魔方 , 只需訓練幾十次后便能「盲擰」;而面對一道做過幾遍的數學題 , 我們往往能在腦海中迅速復現思路 , 幾秒內作答 。
那 , 大語言模型也能這樣嗎?
Emory大學的研究者Bo Pan和Liang Zhao最近發布了一篇令人振奮的成果:大語言模型的性能 , 也和熟練度有關 , 確實能「越用越快」!
論文地址:https://arxiv.org/abs/2505.20643
論文首次系統性地驗證了LLM在「有經驗」的條件下 , 不僅性能不降 , 反而能大幅減少推理時間和計算資源 , 揭示了「AI也能熟能生巧」的全新范式 。
如何讓LLM變熟練?為系統驗證「熟練加速效應」 , 作者提出一個統一框架 , 構造并量化三類記憶機制下的「使用經驗」 。
該框架由兩部分組成 , 一是推理時動態計算資源分配 , 二是記憶機制 。
對于動態計算資源分配 , 該文章系統性將多種已有test-time scaling方法擴展成動態計算資源分配 , 從而允許LLM在熟練的問題上分配更少的計算資源 。
對于記憶機制 , 該框架引入記憶機制 , 從而實現通過過往經驗加速當前推理 。
在多輪使用中 , 大模型是否能像人類一樣「從經驗中變快」?是否存在一種方法 , 能系統性地提升效率 , 而非單純堆算力?
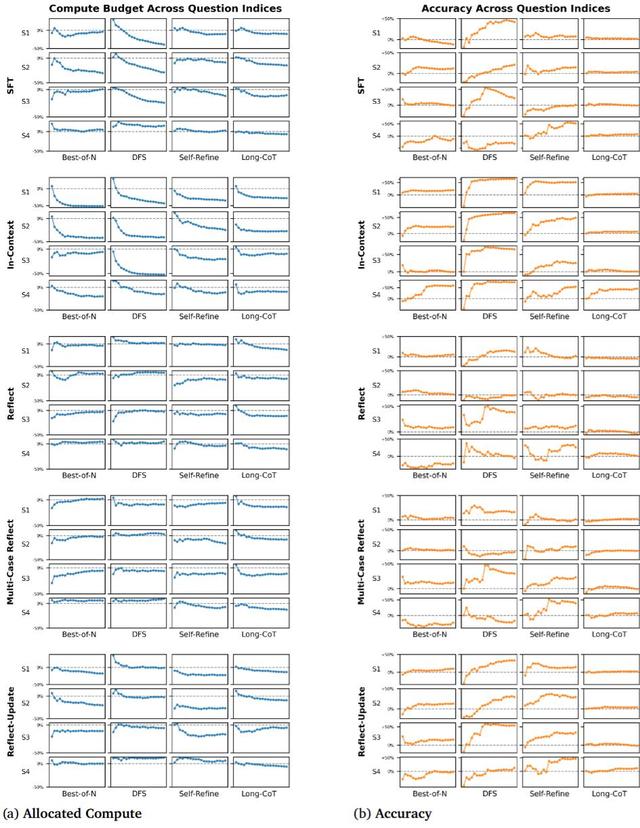
研究亮點1:用經驗節省算力在任務重復或相似的推理過程中 , 研究者發現LLM通過利用以往經驗(包括 memory cache、in-context memory 等) , 可以實現減少高達56%的推理預算 , 保持甚至提升準確率 。
這意味著模型在處理「熟悉」的任務時能少走很多彎路 , 不僅答得準 , 還答得快 。
研究亮點2:系統性大規模實驗為了驗證普適性 , 研究者考察了:
多種test-time scaling方法 , 包括Self-Refine、Best-of-N、Tree-of-Thoughts和當前最新的Long Chain-of-Thought(o1式思考)
多種記憶 , 包括監督學習(Supervised Fine-tuning)、檢索過去經歷、三種自我反思(Reflection)
多種問題相似度 , 包括LLM在1)完全相同、2)意思一樣僅表述不同、3)題目一樣 , 僅換數字、4)不同題目但需要相同知識回答 。
不同機制均表現出顯著的推理加速 , 展示了這一現象的廣泛性 。
實驗結果在「重復問答」、「分步推理」等任務中 , 越是「重復」 , 模型推理越快 , 效果越好 。 而且 , 這種趨勢隨著經驗積累更加明顯 。
實驗結果帶來了以下八大關鍵發現:
發現一:LLM真的可以「越用越快」!
實驗結果表明 , 在配備適當記憶機制和計算預算調控策略的前提下 , LLM在處理重復或相似任務時 , 平均可節省高達56%的推理開銷 , 且這一行為在80組實驗設置中有64組都出現了顯著的加速現象 , 覆蓋率高達80% , 驗證了「經驗式加速」具有普適性 。
發現二:越快≠越差 , 反而更準!
令人驚喜的是 , 推理成本的下降不僅沒有犧牲準確率 , 反而普遍帶來了準確率的提升 。 實驗測得推理成本與準確率提升之間的Pearson相關系數為 -0.41(p=0.0002) , 這表明「更快」也意味著「更穩」「更準」 。
發現三:相似度越高 , 提速越明顯
研究設計了4個相似度等級 , 從完全重復(S1)到結構變化大(S4) 。 結果發現 , S1和S2類問題下的加速最顯著(分別節省16.0%和15.4%計算) , 而S4問題由于結構不同、記憶不具備直接遷移性 , 加速效果最弱 。
發現四:問題相似度低時 , 記憶機制可能反噬
當問題間差異過大時 , 記憶機制可能誤導模型走錯方向 , 導致推理成本反升、準確率反降 。 這種現象在部分S4設置中顯著 , 提示我們記憶并非越多越好 , 而應「選得準、用得巧」 。
發現五:情節記憶反思記憶 , 更能加速推理
在不同記憶機制對比中 , 情節式記憶(如SFT和In-Context)在推理加速上表現更佳 。 例如In-Context平均節省27.4%計算 , 而反思類記憶僅為3.6%~8.8% 。 這與心理學研究一致:人類在形成熟練技能時 , 最初依賴的是具體實例的情節記憶 。
發現六:In-Context比SFT更高效
在低樣本(1~3輪)場景下 , In-Context學習相比SFT更具泛化能力、更少過擬合 , 尤其在本研究的推理速度上 , In-Context 更快、更穩、更準 , 展現了非參數記憶的強大即時適應力 。
發現七:文本記憶易「觸頂」 , 參數記憶可持續提速
反思類與In-Context等文本記憶方法存在上下文窗口的「瓶頸」 , 在加入3個案例后效果逐漸飽和;相比之下 , SFT通過權重更新記憶內容 , 不受窗口限制 , 推理速度隨經驗持續提升 。
發現八:越「泛化」的反思 , 提速越明顯
三種反思機制中 , Reflect-Update表現最佳 。 原因在于它能持續總結抽象規則 , 而不是堆積具體數字或案例 。 這種「泛化性強」的反思更容易跨任務遷移、輔助加速 , 未來設計更好反思機制時值得關注 。
讓LLM擁有「記憶力」和「熟練度」這項研究提出了一種值得重視的新范式:
推理效率不只是堆硬件 , 也能靠「學習歷史」提升 。
在客服、搜索、問診等反復場景中 , 部署「記憶型LLM」將帶來:更低的響應延遲、更少的算力消耗、更強的適應性和個性化 。
這項研究不僅補足了現有推理加速研究的空白 , 更為構建「具備人類熟練性」的AI模型提供了新思路 。
參考資料:
【大模型“越用越快”,SpeedupLLM首次驗證,大降56%推理預算】https://arxiv.org/abs/2505.20643
推薦閱讀












- “訂閱號”改名“公眾號”,可現在誰還看微信公眾號?
- 場景種草:為什么用戶更愿意為“生活方式”買單?
- 活久見,居然有科學家在論文里“賄賂”AI
- 2025年國補后,“口碑絕佳”的4款直屏手機,16+512GB價“真香”
- “六邊形戰士”——iQOOZ9,256GB版跌至1169元!
- 余承東自嘲“不會營銷”?這才是華為最狠的招!
- 16GB+1TB從4999降到2999元,價格“雪崩”的小屏旗艦,可以撿漏了
- 華為打響“價格戰”!2K曲屏+昆侖玻璃+5500mAh,現已跌至4999元
- 2025國補后,“銷量狂飆”的4款手機,怎么選都很香!
- 2025年國補后,三款中檔產品可“閉眼入”,或是2000元預算的首選