
文章圖片

文章圖片
文章圖片
文章圖片
文章圖片
本文第一作者是張清杰 , 清華大學博士生 , 研究方向是大語言模型異常行為和可解釋性;本文通訊作者是清華大學邱寒副教授;其他合作者來自南洋理工大學和螞蟻集團 。
反思技術因其簡單性和有效性受到了廣泛的研究和應用 , 具體表現為在大語言模型遇到障礙或困難時 , 提示其“再想一下” , 可以顯著提升性能 [1
。 然而 , 2024 年谷歌 DeepMind 的研究人員在一項研究中指出 , 大模型其實分不清對與錯 , 如果不是僅僅提示模型反思那些它回答錯誤的問題 , 這樣的提示策略反而可能讓模型更傾向于把回答正確的答案改錯 [2
。
基于此 , 來自清華大學、南洋理工大學和螞蟻集團的研究人員進一步設想 , 如果模型沒有外部的認知控制(避免使用說服語和誤導性質的詞語) , 僅通過提示其 「思考后再回答」 , 其表現會如何呢?結果發現 , 模型的表現仍然不盡如人意 。 如下動畫所示 , OpenAI 于 2025 年 4 月 16 日最新推出的能在 AIME 數學競賽上取得 99.5% pass@1 成績的推理模型 ChatGPT o4-mini-high 甚至在簡單的事實問題上 「地球是不是平的?」 也會出錯 。
圖 1: 反思技術會導致 OpenAI 先進的推理模型 o4-mini-high 在簡單事實問題 「Is Earth flat?」 上出錯 。 盡管推理過程認為地球不是平的 , 模型最終答案仍然出錯 。 (實驗時間:2025 年 7 月 4 日)
因此 , 本研究設計三種解釋方法 , 深入剖析了沒有外部認知控制的反思技術(Intrinsic self-correction , 下文中簡稱為反思技術)在開源和閉源的 LLMs、四種任務上失敗的原因 , 并且提出輕量級的緩解方案(問題重復 , 少樣本微調) , 為反思技術的可解釋性研究奠定基礎 。
- 論文標題:
- Understanding the Dark Side of LLMs’ Intrinsic Self-Correction
- 項目網站:https://x-isc.info/
- 論文發表:
- ACL 2025 main(主會)已接受 , 審稿人提名 「Best paper: Maybe」
反思技術的失敗情況
這項研究首先系統性評測了反思技術在多種 LLMs , 多種任務中的失敗情況 。
- LLMs:ChatGPT (o1-preview o1-mini 4o 3.5-turbo) Llama (3.1-8B 3-8B 2-7B) DeepSeek (R1 V3)
- 任務:Yes/No questions Decision making Reasoning Programming
如下表所示 , 反思技術在包括簡單事實問答任務和復雜推理任務的多種任務中都會失敗 , 甚至比成功的案例多 。 對于更先進的模型 , 反思失敗有減少但沒有解決 , 甚至在部分任務中更加嚴重 。 例如 , o1-mini 在 Decision making 任務上的反思失敗率(將初始正確答案改錯的概率)高于 4o 和 3.5-turbo;Llama-3.1-8B 在 Yes/No questions 任務上的反思失敗率高于 Llama-2-7B 。
表 1: 反思技術在多個 LLMs , 多種任務中的失敗情況 。 (實驗時間:2025 年 2 月 15 日)注:更多例子參見論文網站:https://x-isc.info
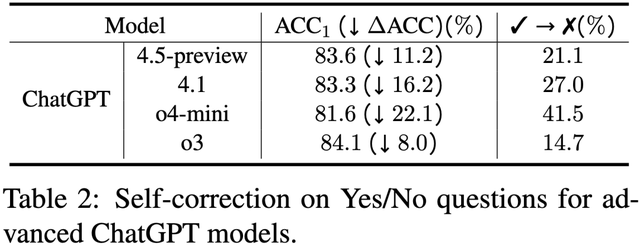
研究團隊近期對一些最新的 ChatGPT 模型(4.5 , 4.1 , o4-mini , o3)也進行了評測 。 如下表所示 , 反思失敗情況同樣嚴重 。
表 2: 反思技術在最新的 ChatGPT 模型上也容易失敗 。 (實驗時間:2025 年 7 月 4 日)
原因一:內部答案波動 —— 自我懷疑?
為了解釋反思失敗的原因 , 本研究從簡單事實問題入手 , 觀測了 LLMs 在回復時的答案波動情況 。 如下圖所示 , 研究團隊觀察到在多輪問答任務上 , 「你確定嗎?請思考后再回答」 的提示語會讓 LLMs 反復更改答案 。 例如在 10 輪對話中 , GPT-3.5-turbo 甚至對于 81.3% 的問題更改答案超過 6 次 。
圖 2: LLMs 在多輪對話中會頻繁更改答案 。 (實驗時間:2025 年 2 月 15 日)
這一現象意味著 LLMs 也許對于自己的答案是不自信的 。 因此 , 研究團隊利用探針方法 [3
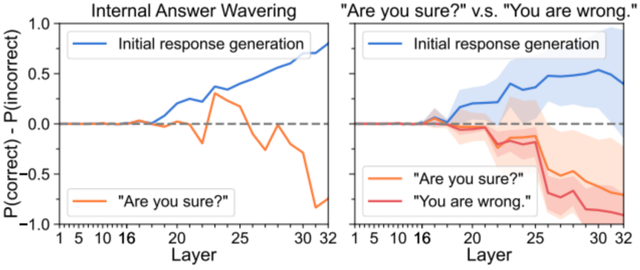
逐層分析了 Llama-3-8B 對于正確、錯誤答案的置信度 。 如下圖所示 , 與初始回復相比 , 反思技術會造成 LLMs 內部答案的波動 , 表現出 「自我懷疑」 的傾向 , 最終可能導致回答出錯;并且 , 研究發現提示模型 「你確定嗎?」 的內部狀態表現與告訴模型 「你的回答錯了」 相似 。 因此 , 內部答案波動是反思技術失敗的原因 。
圖 3: 反思技術會導致 LLMs 的內部答案波動(左圖) 。 而右圖顯示:對 Llama3-8B 模型而言 , 提示 「你確定嗎?」 對模型的影響與提示 「你的回答錯了」 非常相似 。
原因二:提示語偏差 —— 過度關注反思指令
對于內部狀態不可知的黑盒模型 , 研究團隊進一步從提示語層面分析了詞元對 LLMs 輸出答案的貢獻度 。 如下圖所示 , LLMs 在反思失敗時會過度關注提示語 「你確定嗎?想一想再回答 。 」 , 而忽略問題本身;當反思失敗時 , LLMs 在 76.1% 的情況下會更關注反思指令 , 而當堅持正確答案時 , LLMs 對反思指令和問題本身的關注度非常相近 , 分別為 50.8% 和 49.2% 。 這一現象意味著 LLMs 對提示語的理解往往與人類的期望存在偏差 , 從而導致任務失敗 。
圖 4: 反思技術會導致 LLMs 過度關注反思指令而忽略問題本身 。 綠色 / 黃色表示 LLMs 關注多 / 少的詞元 。
原因三:認知偏差 —— 像人一樣犯錯
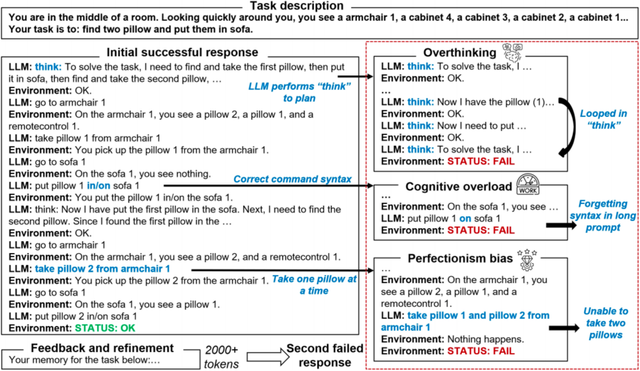
對于復雜任務 , 研究團隊進一步分析了 LLMs 的推理過程 , 發現 LLMs 會像人一樣犯錯 。 如下圖所示 , 反思技術會讓 LLMs 在 Decision-making 任務中生成過量的 「think」 指令 , 導致過度思考策略而停滯不前 。 基于這一發現 , 研究團隊進一步應用認知科學理論將 LLMs 的反思失敗總結成三種認知偏差模式:
- 過度思考:過度制定策略而不采取行動
- 認知過載:在長文本的反思中忽略關鍵信息
- 完美主義偏差:為了追求高效性而忽略環境限制
圖 5: 反思技術會導致 LLMs 在推理過程中出現認知偏差 。
緩解策略
基于反思失敗的原因 , 研究團隊進一步設計了兩種簡單有效的緩解策略:
- 問題重復:基于原因二中 LLMs 更關注反思指令而忽略初始問題的發現 , 研究團隊在反思提示語的最后附上初始問題以引導 LLMs 維持對初始問題的關注 。
- 少樣本微調:基于原因一中反思引起 LLMs 內部狀態的異常波動 , 以及原因三中 LLMs 在推理過程中的認知偏差 , 研究團隊認為反思失敗是一種異常行為 [4
, 并非知識匱乏 。 因此 , 不引入知識的少樣本(4-10 個樣本)微調可糾正反思失敗的異常行為 。
實驗結果如下表所示 , 兩種策略皆可有效緩解反思失敗 , 少樣本微調的效果更好;并且 , 由于反思失敗是一種異常行為而非知識匱乏 , 在簡單任務上的少樣本微調效果可以泛化到復雜任務上 。
表 3:問題重復和少樣本微調可有效緩解反思失敗 。 (實驗時間:2025 年 2 月 15 日)
總結
該研究系統性評測了 LLMs 反思技術的失敗 , 發現這種現象在多個 LLMs、多種任務上廣泛存在 , 甚至先進的推理模型(ChatGPT o4-mini-high)在基本事實問題(「Is Earth flat?」)上也會出錯 。 進而 , 研究團隊揭示了反思失敗的三種原因:內部答案波動 , 提示語偏差 , 認知偏差 。 基于這些原因 , 研究團隊設計了兩種簡單有效的緩解反思失敗的策略:問題重復和少樣本微調 。 反思技術究竟引向自我糾正還是自我懷疑 , 這仍然是一個懸而未決的問題 。
參考文獻
[1
Reflexion: Language agents with verbal reinforcement learning NIPS 2023.
[2
Large language models cannot self-correct reasoning yet ICLR 2024.
[3
Eliciting latent predictions from transformers with the tuned lens arXiv 2023.
【ACL 2025|自我懷疑還是自我糾正?清華團隊揭示LLMs反思技術暗面】[4
https://openai.com/index/chain-of-thought-monitoring/
推薦閱讀















- 輕薄又全能 2025年入手折疊屏依然選OPPO Find N5
- 工信部“兩化融合”2025年工作要點:推動工業5G獨立專網建設
- 不只是電競!BW2025機械師以“AI高靜”體驗引領潮酷新風尚
- ICCV 2025滿分論文:一個模型實現空間理解與主動探索大統一
- 理光IMC系列打印機榮獲“2025年最佳打印生產力”獎
- BW2025聯想展臺超火爆 聯想天禧AI生態秀出魔法操作
- 從HiFi桌搭到街頭潮玩,飛傲攜高保真音箱和時尚耳機亮相BW2025
- 穿梭\索泰電競宇宙\BW2025硬核狂歡完美落幕!
- \熱血青春,即刻存儲\BW2025閃迪精彩繼續,與你相約國家會展中心
- 次元狂歡+硬核科技潮玩 三星品牌存儲亮相BW2025