
文章圖片
文章圖片
在人工智能領域 , 大語言模型(LLM)的快速發展為自然語言處理帶來了革命性的突破 。 然而 , 這些模型在處理實時信息、專業領域知識以及確保回答準確性和可靠性方面仍面臨挑戰 。 本文將深入探討一種名為RAG(Retrieval-Augmented Generation , 檢索增強生成)的技術框架 , 它通過結合信息檢索與大語言模型的生成能力 , 為AI模型提供了強大的外掛支持 。
一、為什么要做RAG?時效性:模型的訓練是基于截止某一時間點之前的數據集完成的 , 這意味著在這之后發生的事情大模型就難以回答 。 如果需要構建能夠推理私有數據或者模型截止日期后引入的數據 , 則需要使用RAG;
解決模型幻覺問題:傳統大模型依賴訓練數據 , 易生成錯誤信息 , 比如用戶問了一個大模型不知道的東西 , 它會通過瞎編來回答 , 其實毫無依據 。 RAG 通過外部知識檢索提供實時、可靠的上下文支撐 , 因此減少“一本正經的胡說八道”現象;
(美國的一位律師 , 他用大模型去搜集案例 , Chat GPT確實給出了幾個案例 。 律師反復去確認這些案例是真實的嗎?大模型回復都是真實的 , 開庭時 , 經過核實這些案例其實都是AI虛構出來的 。 )
彌補專業領域知識內容不足:金融領域、醫療領域等有自己專業知識的沉淀 , 大模型其實是不具備某領域非常專業知識的能力的 , 那我們就可以把專業知識通過Rag技術讓大模型進行知識庫檢索 。 例如金融(業務上的專業知識、產品知識、產品手冊、優質的用戶問答等);
【為什么 RAG 能讓 AI 更 “聰明”?工作原理深度拆解】可靠的知識來源與可驗證性:來自哪篇文章、哪個文檔、哪個網頁都有跡可循 , 可以看到回答的依據來源 , 使得驗證答案準確性變得容易起來;
保障數據安全:可以讓大模型調用私有知識庫來服務用戶 , 避免數據上傳云端或者外部 , 導致重要信息、敏感數據外泄的情況 。
二、RAG到底是什么?RAG(Retrieval-Augmented Generation , 檢索增強生成)是一種結合信息檢索與大語言模型生成能力的技術框架 , 它由兩部分組成:“檢索器”和“生成器”
- 檢索器從外部知識中快速找到與問題相關的信息
- 生成器則利用檢索到的信息來生成精確和連貫的答案 。
三、RAG的工作原理
步驟一:構建可檢索的知識庫如何構建可檢索的知識庫?
01.知識整理:以文件格式存儲 , 比如 word、pdf、ppt、excel、在線的、網頁等等;
02.數據清洗及格式化:將不同格式的數據內容提取為純文本
03.內容切分:將文本內容按段落、主體或者邏輯單元切分成較小的知識片段(Chunk); 那誰來切呢?Embedding
04.向量化:將每個知識片段轉化為向量表示(比如Open AI的 Embedding 接口)
知識補充:什么是向量
向量(Vector)是一種將復雜信息轉化為計算機可處理的數值形式的核心工具 , 本質上是 “高維空間中的有序數值數組” 。 它通過將文本、圖像、聲音等數據映射為特定維度的數字序列 , 讓 AI 模型能夠高效地理解、計算和學習數據背后的規律
通俗來說 , 向量是 AI 的「數字身份證」:把萬物變成數字串
在 AI 眼里 , 圖像、文字、聲音甚至用戶行為 , 都必須先變成一串數字組成的向量才能處理 。
舉個栗子:
文本(NLP 領域): 句子 “我喜歡 AI” 會被轉化為向量 , 比如用 Word2Vec 技術生成 [0.8 -0.3 1.2 …
這樣的數字串 , 向量中的每個數字代表一個隱藏的語義特征(比如 “喜歡” 的情感強度、“AI” 的領域相關性) 。
神奇的是:“AI” 和 “人工智能” 的向量在空間中會非常接近 , 因為它們語義相似 。
借助Embedding模型 , 將切分好的片段轉化成向量(數字組成的) , 這個向量是可以比較相似度
05.關聯元數據:給每個向量關聯相關元數據(如:文檔名稱、創建時間、作者、來源等)
06.載入向量數據庫并建立索引:向量數據庫如FAISS、Pinecone、Weaviate;
07.部署集成:將向量數據庫集成到AI產品流程中 , 生成模型搭配使用 。
步驟二:模型調用知識庫完成用戶任務
- 將用戶的Prompt轉化成向量 , 去向量數據庫里比較相似度;
- 選取相似度較高的1條或者多條知識片段(3條 , 5條 , 10條這樣的召回) , 并提取知識片段原文;
- 將檢索出的知識片段與原Prompt 合并在一起組成新的Prompt
- 模型生成最終回復
四、如何提升回答的準確率?以智能客服舉例 , 比如客服系統無法充分理解用戶的真實意圖 , 回答偏離主題時對用戶 Prompt 進行改寫 , 相同語義的不同問法
可以將用戶的問題 , 通過大模型改寫成多個相似語義的問題(具體可能是2個、3個、4個、5 個等 , 根據準確率評估來定)
比如用戶問:如何交易美股?
我們將用戶問題改寫成4個相同語義的問題
- Q1 我怎么交易美股? 對應50個相似片段–通過排序–挑選Top3
- Q2 我怎么買國外的股票?對應50個相似片段–通過排序–挑選Top3
- Q3 我怎么買美股? 對應50個相似片段–通過排序–挑選Top3
- Q4 可以買美股嗎? 對應50個相似片段–通過排序–挑選Top3
檢索到信息 , 想要的答案排序靠后加入排序模型(Rerank模型)
在基礎RAG中 , 準確率大概在66%左右 , 在加入Rerank之后 , 準確率提升了12%(重新排序可以增加一定的準確度)
在向量知識庫中檢索到相應的片段之后 , 加入排序模型 , 對這些相關片段進行排序 。
比如:檢測出60個相關片段 , 經過Rerank排序之后 , 挑選出前三個相似度最高的片段+用戶提問+系統提示詞 , 一起給到大模型 , 大模型給出回答 。
回答不全面Chunk 切分處優化
- 知識片段有明確主題、交疊切分、多顆粒度混合切分;
- 知識片段的上下相鄰片段可以一并取出 , 提高信息完整度
檢索不全面向量+關鍵詞混合檢索
方法:關鍵詞匹配和向量匹配相結合的形式
- 關鍵詞檢索 , 召回簡單直接 , 能快速找到包含特定關鍵詞的文檔 , 速度快;
- 向量匹配 , 能更好處理語義層面的匹配 , 提高召回的全面性 。
這幾個小技巧是提升準確率的比較好用的小方法 , 分享給大家 , 大家也可結合自己的項目繼續探索 , 多多交流~
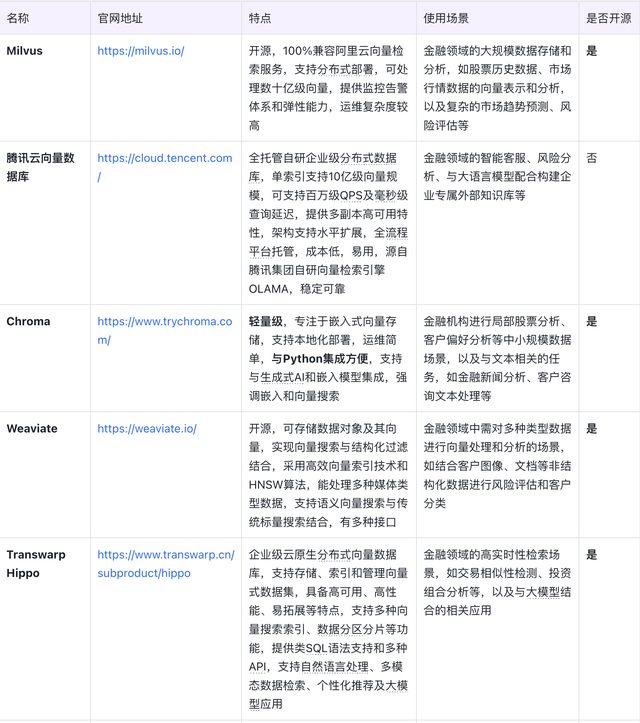
五、市面上向量數據庫對比本文由 @梧桐AI 原創發布于人人都是產品經理 。 未經作者許可 , 禁止轉載
題圖來自Unsplash , 基于CC0協議
該文觀點僅代表作者本人 , 人人都是產品經理平臺僅提供信息存儲空間服務
推薦閱讀














- AI寫的文章為什么總是“不能細看”
- 為什么你的手機充電時會發熱發燙?這些充電習慣要趕緊改
- 為什么越來越多的人,喜歡在拼多多買東西?其中原因,看完明白了
- AI+RAG 驅動的企業數字化服務數據分析平臺
- 為什么說迷你主機是小眾剛需,注定火不起來?
- 提示詞工程:為什么產品經理需要懂提示詞工程
- AI失憶術,只需3個注意力頭,就能讓大模型忘記「狗會叫」
- 自第一款折疊屏手機問世已過去六年,為什么銷量只占1.5%呢?
- 為什么說iPhone17會是一款真香機?這兩大升級很關鍵
- 為什么寧愿買iPhone16Pro?也不買小屏安卓?四個原因很現實