
文章圖片

文章圖片
文章圖片
文章圖片

【導讀】Bind-Your-Avatar是一個基于擴散Transformer(MM-DiT)的框架 , 通過細粒度嵌入路由將語音與角色綁定 , 實現精準的音畫同步 , 并支持動態背景生成 。 該框架還引入了首個針對多角色對話視頻生成的數據集MTCC和基準測試 , 實驗表明其在身份保真和音畫同步上優于現有方法 。
近年來隨著視頻生成基礎模型的涌現 , 音頻驅動的說話人視頻生成領域也取得了顯著進展 。
但現有方法主要聚焦于單角色場景 , 現有可生成兩個角色對話視頻的方法僅能單獨地生成兩個分離的說話人視頻 。
針對這一挑戰 , 研究人員提出了首個專注同場景多角色說話視頻生成的框架Bind-Your-Avatar
該模型基于擴散Transformer(MM-DiT) , 通過細粒度的嵌入路由機制將「誰在說」與「說什么」綁定在一起 , 從而實現對音頻–角色對應關系的精確控制 。
論文地址:https://arxiv.org/abs/2506.19833 項目地址:https://yubo-shankui.github.io/bind-your-avatar作者同時構建了首個針對多角色對話視頻生成的完整數據集(MTCC)和評測基準 , 提供了端到端的數據處理流程 。
大量實驗表明 , Bind-Your-Avatar在多角色場景下生成效果優異 , 在人臉身份保真和音畫同步等指標上均顯著優于現有基線方法 。
Bind-Your-Avatar 方法概覽Bind-Your-Avatar基于一個多模態文本到視頻擴散Transformer(MM-DiT)搭建 , 模型輸入包括:文本提示、多路語音音頻流、多個角色的人臉參考圖像 , 以及(可?。 ┮恢∮糜諢嬤票塵暗膇npainting幀 。
文本、音頻和人臉身份特征通過特征編碼器提取 , 并由Embedding路由引導的交叉注意力(Cross-Attention)將人臉和音頻信息選擇性地注入到視覺Token中 , 從而實現音畫同步性的關聯 。
模型的訓練分為三個階段:第一階段只生成帶補全幀的靜音角色運動視頻(不使用音頻) , 第二階段加入單角色語音輸入學習音頻驅動的精細角色運動(通過LoRA輕量化微調) , 第三階段引入多角色語音輸入并聯合訓練Embedding路由(使用教師強制方法防止掩碼退化) 。
細粒度Embedding路由引導的音頻–角色驅動 【免剪輯直出,AI生成多角色同框對話視頻,動態路由精準綁定音頻】Embedding路由的作用輸出是一個時空掩碼矩陣M , 用于指示每個視覺Token對應哪個角色(或背景) , 從而將說話人與具體語音綁定 。
在訓練時 , 研究人員設計了交叉熵損失
監督路由輸出 , 并結合幾何先驗引入時空一致性損失和層一致性損失 , 增強掩碼的準確性和平滑性 。
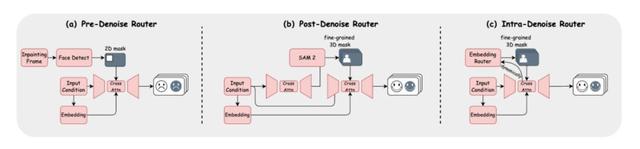
論文中探討了三種路由實現方式:預去噪(Pre-Denoise , 用靜態2D掩碼)、后去噪(Post-Denoise , 兩階段生成后預測3D掩碼)以及內置去噪(Intra-Denoise)路由 。
Intra-Denoise路由在擴散去噪過程中動態生成細粒度3D時空掩碼 , 實現對各角色幀級獨立控制 。 這種設計不僅提升了音頻與對應角色口型的精度 , 還保持了角色身份的連貫性 。
為了得到高質量的3D-mask , 研究人員在路由的設計中提出了兩個有效的方法 。 其中 , 掩碼優化策略通過引入幾何先驗對掩碼進行正則化 , 提高了角色與背景區域分割的準確度和時序一致性;此外 , 研究人員還提出了一種掩碼細化流程 , 將初步預測的稀疏掩碼進行平滑和時間一致性校正 , 進一步增強掩碼質量 。
MTCC數據集為了支持多角色視頻生成 , 研究人員構建了MTCC數據集(Multi-Talking-Characters-Conversations) , 該數據集包含200+小時的多角色對話視頻 。
數據處理流程包括:
視頻清洗(篩選分辨率、時長、幀率;確保視頻中恰有兩個清晰角色;姿態差異度過濾等)、音頻分離與同步篩?。 ㄊ褂肁V-MossFormer和Sync-C指標確保音畫一致)、語音與文本標注(應用Wav2Vec提取音頻特征 , QWen2-VL生成描述)以及SAM2生成角色區域掩碼作為監督信號 。
MTCC附帶完整的開源處理代碼 , 為社區提供了從原始視頻到訓練數據的端到端流水線 。
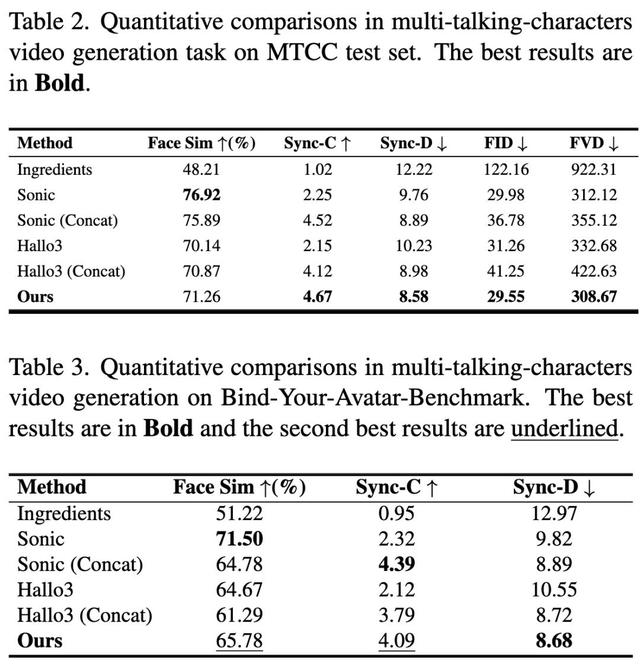
實驗與分析 定量分析研究人員在MTCC測試集和全新基準集(Bind-Your-Avatar-Benchmark , 含40組雙角色人臉和雙流音頻)上與多種基線方法進行了對比 , 包括最近的Sonic、Hallo3和Ingredients等 。 這些方法原本設計用于單角色或無背景場景 , 對本任務進行了適配 。
定量指標涵蓋角色身份保持(Face Similarity)、音畫同步(Sync-C、Sync-D)以及視覺質量(FID、FVD)等 。
結果表明 , Bind-Your-Avatar在人臉相似度和音畫同步度指標上均顯著優于各基線(同步指標尤其優異) , 而在FID/FVD等視覺質量指標上也保持競爭力 。
消融實驗進一步驗證:細粒度3D掩碼比邊界框或靜態2D掩碼能更好地應對角色運動和近距離互動 , 提升了動態場景下的生成質量 。
定性分析Bind-Your-Avatar能自然處理多角色的交叉說話場景 , 同時生成統一、動態的背景 , 無需后期拼接 。
例如 , Bind-Your-Avatar能生成兩個角色同時講述不同內容的對話視頻 , 并保持每個角色的口型與對應語音高度同步 , 同時人物面部和表情逼真 。
結語Bind-Your-Avatar 首次提出了同場景多角色語音驅動視頻生成任務 , 并提供了從算法到數據集的完整解決方案 。
其主要貢獻包括:細粒度Embedding路由機制(實現「誰在說什么」的精確綁定)、動態3D-mask路由設計(逐幀控制各角色) , 以及MTCC數據集和對應的多角色生成基準 。
未來工作將聚焦于增強角色動作的真實感(如身體和手勢動作)并優化模型實時性能 , 以適應更大規模和在線化的多角色視頻生成需求 。
研究人員后續將開源數據集和代碼 , 方便社區進一步研究 。
參考資料:
https://arxiv.org/abs/2506.19833
推薦閱讀












- “京東取消外賣超時20分鐘免單”沖上熱搜
- 向QQ音樂看齊,騰訊視頻開測廣告免費模式
- 蘋果2025高校優惠開啟:Mac系列和iPad系列為主 最長享三個月免息分期
- 四款免費開源音樂播放軟件推薦:暢享自由音樂之旅
- 狂背90%哈利波特,這玩意真成免費電子書庫了?
- NASA與網飛達成合作,將免費直播火箭發射及國際空間站實景
- 昨夜,阿里版GPT-4o登場,一句話精準P圖,免費可用
- 谷歌殺瘋,百萬token神器免費開源,Claude和Codex都頂不住了?
- 蘋果擬調整App Store規則向歐盟示好 避免因反壟斷再遭處罰
- 免費、開源!谷歌Gemini CLI徹底火了,平替Claude Code