
文章圖片
文章圖片

文章圖片
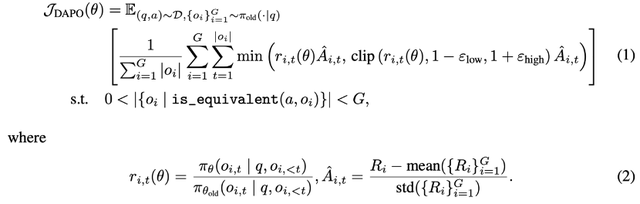
文章圖片
文章圖片

文章圖片
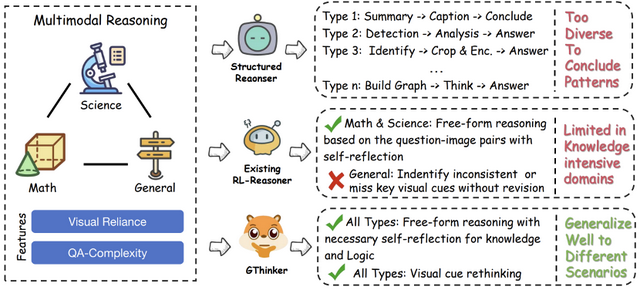
盡管多模態大模型在數學、科學等結構化任務中取得了長足進步 , 但在需要靈活解讀視覺信息的通用場景下 , 其性能提升瓶頸依然顯著 。 現有模型普遍依賴基于知識的思維模式 , 卻缺乏對視覺線索的深度校驗與再思考能力 , 導致在復雜場景下頻繁出錯 。
為解決這一難題 , 來自中科院自動化研究所紫東太初大模型研究中心的研究者提出 GThinker , 一個旨在實現通用多模態推理的新型多模態大模型 。
GThinker 的核心在于其創新的「線索引導式反思(Cue-Guided Rethinking)」模式 , 它賦予了模型在推理過程中主動校驗、修正視覺理解的能力 。
通過精心設計的兩階段訓練流程 , GThinker 在極具挑戰性的 M3CoT 綜合推理基準上取得了超越了最新的 O4-mini 模型 , 并在多個數學及知識推理榜單上展現出 SOTA 性能 , 證明了該方法的有效性和泛化能力 。 目前 , 論文、數據及模型均已開源 。
論文鏈接:https://arxiv.org/abs/2506.01078 項目地址:https://github.com/jefferyZhan/GThinker 開源倉庫:https://huggingface.co/collections/JefferyZhan/gthinker-683e920eff706ead8fde3fc0
慢思考的瓶頸:
當模型在通用場景「視而不見」
當前 , 無論是開源的 Qwen2.5-VL , 還是閉源的 GPT-4o , 多模態大模型的能力邊界正在被不斷拓寬 。 尤其在引入了思維鏈(CoT)等慢思考策略后 , 模型在數學、科學等邏輯密集型任務上的表現得到了顯著增強 。
然而 , 這些進步并未完全轉化為在通用多模態場景下的推理能力 。 與擁有明確答案和嚴格邏輯結構的數理任務不同 , 通用場景(如理解一幅畫的寓意、分析復雜的日常情景)往往涉及:
高度的視覺依賴:答案強依賴于對圖像中多個、甚至有歧義的視覺線索的正確解讀 。 復雜的推理路徑:沒有固定的解題范式 , 需要模型根據具體問題靈活組織推理步驟 。
現有方法 , 無論是基于結構化 CoT 的 , 還是基于結果獎勵強化學習的 , 都存在明顯的局限性 。 它們在推理中一旦對某個視覺線索產生誤判 , 往往會「一條道走到黑」 , 缺乏中途 「回頭看」、修正認知偏差的機制 。
現有主流多模態推理方法的特點與局限性
GThinker:
從 「思維鏈」 到 「再思考鏈」
為了打破這一瓶頸 , 研究團隊提出了 GThinker , 其核心是一種全新的推理模式 ——「線索引導式反思」(Cue-Guided Rethinking) 。 該模式將推理過程升級為一種更接近人類思維的 「思考 - 反思 - 修正」 閉環 , 它不強制規定僵化的推理結構 , 而是要求模型在自由推理后 , 對關鍵視覺線索進行一次系統性的回溯驗證 。
Cue-Rethinking核心流程 , 虛線框代表可能進行
整個過程分為三個階段:
1. 自由初始推理:模型根據問題和圖像內容 , 自由地進行一步步推理 , 同時使用vcues_*標簽標記出其所依賴的關鍵視覺線索 。
2. 反思觸發:在初步推理鏈完成后 , 一個反思提示(如 「Let's verify each visual cue and its reasoning before finalizing the answer.」)被觸發 , 引導模型進入基于再思考階段 。
3. 基于視覺線索的反思:模型逐一回顧所有標記的視覺線索 , 檢查其解釋是否存在不一致、錯誤或遺漏 。 一旦發現問題 , 模型會修正或補充對該線索的理解 , 并基于新的理解重新進行推理 , 最終得出結論 。
GThinker推理模式示例
以上圖為例 , GThinker 在初步推理中可能將圖形誤判為 「螃蟹」 。 但在再思考階段 , 它會發現 「紅色三角形更像蝦頭而非蟹身」、「藍粉組合更像蝦尾而非蟹鉗」 , 從而修正整個推理路徑 , 最終得出正確答案 「蝦」 。 這種機制使得 GThinker 能夠有效處理有歧義或誤導性的視覺信息 , 極大地提升了推理的準確性 。
兩階段訓練法:
如何教會模型進行再思考?
為了讓模型內化這種強大的反思能力 , GThinker 設計了一套環環相扣的兩階段訓練框架 。
GThinker 整體訓練流程示例圖
模式引導冷啟動
不同于數理領域在預訓練后自然涌現的反思能力 , 單純依靠來結果獎勵強化學習 「探索」 出如此復雜的再思考行為 , 不僅成本高昂且效率低下 。 因此 , GThinker 首先通過監督微調的方式 , 為模型 「冷啟動」 構建基于視覺線索的再思考能力 。
為此 , 首先通過「多模態迭代式標注」構建了一個包含 7K 高質量冷啟動樣本數據集:利用 GPT-4o、O1、O3 等多個先進模型的互補優勢 , 對覆蓋通用、數學、科學三大領域的復雜問題進行迭代式地推理和標注 , 生成了包含高質量再思考路徑的訓練數據 。
在訓練時 , GThinker 采用「模式引導選擇性格式化」策略 , 僅對那些基座模型會產生視覺誤判的樣本應用完整的 「反思鏈」 格式 , 其余則保留為標準推理格式 。 這使得模型能夠學會在 「需要時」才進行反思 , 而非機械地執行 。
激勵強化學習
在掌握 「如何思考」 以及基于視覺線索進行 「再思考」 的能力基礎上 , GThinker 進一步引入基于可驗證獎勵的強化學習方法 , 設計混合獎勵機制并構建覆蓋多種推理類型的多場景訓練數據 , 以持續激勵模型在多樣化任務中進行主動探索 , 從而實現思維模式的跨場景泛化遷移 。
多場景數據構建:廣泛收集開源推理數據 , 并通過 embedding 聚類的方式進行均衡和多樣性采樣 , 從中精選包含約 4K 條多場景、多任務的強化學習訓練數據集 , 為泛化能力的提升提供數據保障 。 DAPO 訓練:相較于 GRPO , DAPO 采用動態采樣的方式 , 保證 batch 樣本的有效性 , 并應用無 KL 和 clip higher 等策略 , 更適用于長鏈思考和探索 , 使模型學會在不同場景下選擇最優推理方式 。
混合獎勵計算:針對選擇題、數學題等常見任務類型 , 分別采用精確匹配、Math-Verify 工具校驗的方式計算獎勵 , 對于通用場景下常見的開放式簡答題 , 通過加入格式化響應讓模型回答歸納到短語或單詞的形式 , 以應用精確匹配的計算方式 , 從而確保了獎勵信號的準確性和進一步拓展支持任務的多樣性 。【多模態大模型學會回頭「看」:中科院自動化所提出GThinker模型】結果
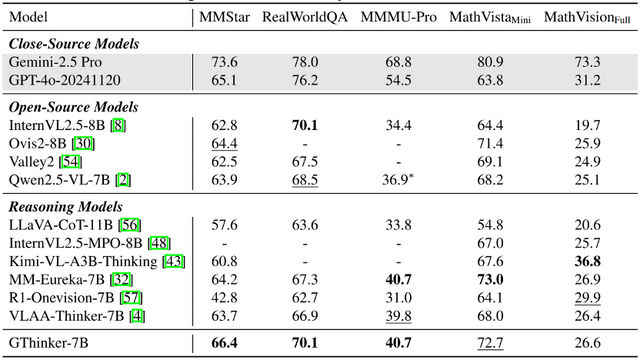
在復雜、多步及多領域的多模態推理基準 M3CoT 上 , GThinker 在多個場景的測試中超過當前先進的開源多模態推理模型及 O4-mini 。
在通用場景(MMStar、RealWorldQA)、多學科場景(MMMU-Pro)及數學基準測試中 , GThinker 實現了優于或不遜于現有先進模型的表現 , 證明了 GThinker 所學的再思考能力并未造成 「偏科」 , 而是實現了整體通用能力提升 。
盡管 GThinker 的數據均為復雜推理任務構建 , 但經過這一方法及數據的訓練后 , 當前最領先的開源模型依然能夠在通用指標上進一步提升 。 研究團隊選取了 OpenCompass 閉源多模態榜單中 10B 規模下最新排名前三的開源模型 , 在學術榜單上進行測試 。 結果顯示 , GThinker 在這三款模型上均帶來約 1 個百分點左右的平均性能提升 , 進一步印證了其方法的有效性與泛化能力 。
Demo
推薦閱讀














- 被大模型逼瘋的甲方,開始反擊!
- 首個多模態工業信號基座模型FISHER,權重已開源,來自清華&上交
- 復旦聯合南洋理工提出基于視覺Grounding的多輪強化學習框架MGPO
- eSIM+低軌衛星,華為Mate80黑科技太多了,遠不止新麒麟
- 7000mAh+80W+多功能NFC,跌至891元,OPPO親民了
- 一圖讀懂騰訊AI全景布局:以混元大模型為基礎,“1+3+N”體系成型
- 小米16 Ultra再次被確認:連續光變+兩億像素,多群潛望方案也來了
- 云天勵飛宣布全面聚焦AI推理芯片!要支撐萬億參數大模型
- 一到人多的地方就網卡?用一加Ace 5至尊版包流暢的
- 不再是Pura80獨享!Mate70等眾多機型,喜提鴻蒙5.1