
文章圖片
文章圖片
文章圖片

文章圖片
機器之心報道
編輯:陳陳
實時強化學習來了!AI 再也不怕「卡頓」 。
設想這樣一個未來場景:多個廚師機器人正在協作制作煎蛋卷 。 雖然我們希望這些機器人能使用最強大可靠的智能模型 , 但更重要的是它們必須跟上瞬息萬變的節奏 —— 食材需要在精準時機添加 , 煎蛋過程需要實時監控以確保受熱均勻 。 只要機器人動作稍有延遲 , 蛋卷必定焦糊 。 它們還必須應對協作伙伴動作的不確定性 , 并做出即時適應性調整 。
實時強化學習
然而 , 現有的強化學習算法多基于一種理想化的交互模式:環境與智能體輪流「暫停」以等待對方完成計算或響應 。 具體表現為:
環境暫停假設:當智能體進行計算決策和經驗學習時 , 環境狀態保持靜止;
智能體暫停假設:當環境狀態發生轉移時 , 智能體暫停其決策過程 。
這種類似「回合制游戲」的假設 , 嚴重脫離現實 , 難以應對持續變化、延遲敏感的真實環境 。
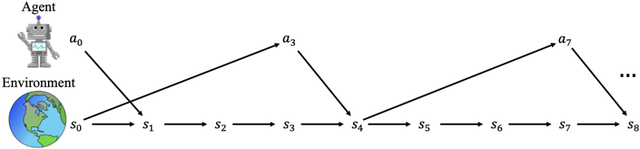
下圖突出顯示了智能體在實時環境中出現的兩個關鍵困難 , 而這些在標準的回合制 RL 研究中是不會遇到的 。
首先 , 由于動作推理時間較長 , 智能體可能不會在環境的每一步都采取動作 。 這可能導致智能體采用一種新的次優性策略 , 稱之為無動作遺憾(inaction regret) 。
第二個困難是 , 動作是基于過去的狀態計算的 , 因而動作會在環境中產生延遲影響 。 這導致另一個新的次優性來源 , 這在隨機環境中尤為突出 , 稱之為延遲遺憾(delay regret) 。
在這樣的背景下 , Mila 實驗室兩篇 ICLR 2025 論文提出了一種全新的實時強化學習框架 , 旨在解決當前強化學習系統在部署過程中面臨的推理延遲和動作缺失問題 , 使得大模型也能在高頻、連續的任務中實現即時響應 。
第一篇論文提出了一種最小化無動作遺憾的解決方案 , 第二篇提出了一種最小化延遲遺憾的解決方案 。
最小化無動作:交錯推理
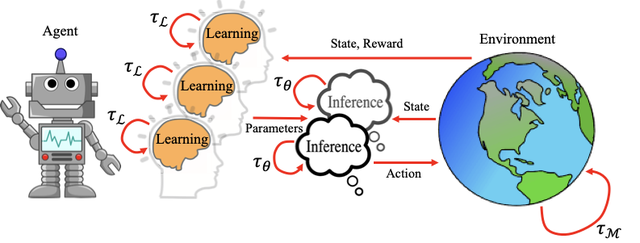
第一篇論文基于這樣一個事實:在標準的回合制強化學習交互范式中 , 隨著模型參數數量的增加 , 智能體無動作的程度也會隨之增加 。 因此 , 強化學習社區必須考慮一種新的部署框架 , 以便在現實世界中實現基礎模型規模化的強化學習 。 為此 , 本文提出了一個用于異步多過程推理和學習的框架 。
論文地址:https://openreview.net/pdf?id=fXb9BbuyAD 代碼地址 https://github.com/CERC-AAI/realtime_rl 論文標題: ENABLING REALTIME REINFORCEMENT LEARNING AT SCALE WITH STAGGERED ASYNCHRONOUS INFERENCE
在該框架中 , 允許智能體充分利用其可用算力進行異步推理與學習 。 具體而言 , 本文提出了兩種交錯式推理算法 , 其核心思想是通過自適應調整并行推理過程的時序偏移 , 使智能體能夠以更快的固定間隔在環境中執行動作 。
本文證明:只要計算資源足夠 , 無論模型有多大、推理時間有多長 , 使用任意一種算法都可以做到在每一個環境步都執行動作 , 從而完全消除無動作遺憾 。
本文在 Game Boy 和 Atari 實時模擬中測試了提出的新框架 , 這些模擬的幀率和交互協議與人類在主機上實際玩這些游戲時所體驗到的幀率和交互協議同步 。
論文重點介紹了異步推理和學習在《寶可夢:藍》游戲中使用一個擁有 1 億參數的模型成功捕捉寶可夢時所展現的卓越性能 。 需要注意的是 , 智能體不僅必須快速行動 , 還必須不斷適應新的場景才能取得進展 。
此外 , 論文還重點介紹了該框架在像俄羅斯方塊這樣注重反應時間的實時游戲中的表現 。 結果證明 , 在使用異步推理和學習時 , 模型規模越大 , 性能下降的速度就越慢 。 然而 , 大模型性能下降的根本原因是延遲遺憾效應尚未得到解決 。
用單個神經網絡最小化無動作和延遲遺憾
論文地址:https://openreview.net/pdf?id=YOc5t8PHf2 項目地址:https://github.com/avecplezir/realtime-agent 論文標題: HANDLING DELAY IN REAL-TIME REINFORCEMENT LEARNING
第二篇論文提出了一種架構解決方案 , 用于在實時環境中部署神經網絡時最大限度地減少無響應和延遲 , 因為在實時環境中 , 交錯推理并非可行 。 順序計算在深度網絡中效率低下 , 因為深度網絡中每一層的執行時間大致相同 。 因此 , 總延遲會隨著網絡深度的增加而成比例增加 , 從而導致響應緩慢 。
這一局限性與早期 CPU 架構的缺陷如出一轍 —— 當指令只能串行處理時 , 會導致計算資源利用率低下且執行時間延長 。 現代 CPU 采用 pipelining 技術成功解決了這一問題 , 該技術允許多條指令的不同階段并行執行 。
【強化學習的兩個「大坑」,終于被兩篇ICLR論文給解決了】
受此啟發 , 本文在神經網絡中引入了并行計算機制:通過一次計算所有網絡層 , 有效降低了無動作遺憾 。
為了進一步減少延遲 , 本文引入了時序跳躍連接(temporal skip connections) , 使得新的觀測信息可以更快地傳遞到更深的網絡層 , 而無需逐層傳遞 。
該研究的核心貢獻在于:將并行計算與時序跳躍連接相結合 , 從而在實時系統中同時降低無動作遺憾和延遲遺憾 。
下圖對此進行了說明 。 圖中縱軸表示網絡層的深度 , 從初始觀測開始 , 依次經過第一層、第二層的表示 , 最終到達動作輸出;橫軸表示時間 。 因此 , 每一條箭頭代表一層的計算過程 , 所需時間為 δ 秒 。
在基線方法中(左圖) , 一個新的觀測必須依次穿過全部 N 層網絡 , 因此動作的輸出需要 N × δ 秒才能獲得 。
通過對各層進行并行計算(中圖) , 可以將推理吞吐量從每 Nδ 秒一次提高到每 δ 秒一次 , 從而減少無動作遺憾 。
最終 , 時序跳躍連接(如右圖所示)將總延遲從 Nδ 降低至 δ—— 其機制是讓最新觀測值僅需單次 δ 延遲即可傳遞至輸出層 。 從設計理念來看 , 該方案通過在網絡表達能力與時效信息整合需求之間進行權衡 , 從根本上解決了延遲問題 。
此外 , 用過去的動作 / 狀態來增強輸入可以恢復馬爾可夫特性 , 即使在存在延遲的情況下也能提高學習穩定性 。 正如結果所示 , 這既減少了延遲 , 也減少了與優化相關的遺憾 。
兩者結合使用
交錯式異步推理與時序跳躍連接是彼此獨立的技術 , 但具有互補性 。 時序跳躍連接可減少模型內部從觀測到動作之間的延遲 , 而交錯推理則確保即使在使用大模型時 , 也能持續穩定地輸出動作 。
兩者結合使用 , 可以將模型規模與交互延遲解耦 , 從而使在實時環境中部署既具有強表達能力、又響應迅速的智能體成為可能 。 這對于機器人、自動駕駛、金融交易等高度依賴響應速度的關鍵領域具有重要意義 。
通過使大模型在不犧牲表達能力的前提下實現高頻率決策 , 這些方法為強化學習在現實世界的延遲敏感型應用中落地邁出了關鍵一步 。
參考鏈接:
https://mila.quebec/en/article/real-time-reinforcement-learning
推薦閱讀















- WAIC 2025觀察 | “沖上去”的超聚變,如何做智能體時代的探索者?
- 炸圈的ChatGPT Agent ,到底有哪些能耐?能不能替代普通牛馬?
- 硬核「吵」了30分鐘:這場大模型圓桌,把AI行業的分歧說透了
- Google將AI驅動的照片生成視頻功能擴展至更多應用
- 被大模型逼瘋的甲方,開始反擊!
- 清華大學團隊讓AI學會識別表情背后的真實感受
- “四成AI六小龍的員工在看機會”,脈脈一則數據背后的火爆真相
- 不知你是否見過:芯片收藏家展示其最稀有的x86 CPU
- 復旦聯合南洋理工提出基于視覺Grounding的多輪強化學習框架MGPO
- 這家初創公司認為電子郵件是AI智能體實用化的關鍵