
文章圖片
文章圖片

文章圖片
文章圖片

機器之心報道
機器之心編輯部
什么?2025 年世界人工智能大會(WAIC)第二天 , 幾位行業大佬「吵」起來了 。
是的 , 你沒聽錯!他們「吵架」的熱度 , 堪比盛夏的天氣 , 直逼 40 度高溫 。
事情的起因是在一場圓桌論壇上 , 剛聊到模型訓練范式 , 大家就展開了尖峰辯論 。
但這場關于訓練范式的思想碰撞 , 很快轉移到了模型架構、訓練數據、開閉源等尖銳的問題上 。 每個問題都深入大模型發展的核心要害 。
最直觀的感受:「這是 AI 行業頂流的公開 battle , 我愿稱之為今年最硬核『吵架』現場 。 」臺上嘉賓你來我往 , 臺下觀眾掌聲不斷 。
而這場圓桌論壇 , 是由商湯科技承辦的 WAIC 2025 大模型論壇的「模型之問」圓桌 —— 探討的是「大模型技術演進與發展之路」 。
圓桌主持人由商湯科技聯合創始人、執行董事、首席科學家林達華擔任主持 。 嘉賓陣容堪稱當前大模型生態的多路代表:包括階躍星辰首席科學家張祥雨 , 上海人工智能實驗室青年領軍科學家、書生大模型負責人陳愷 , 北京智譜華章科技股份有限公司總裁王紹蘭 , 范式集團聯合創始人、首席科學官陳雨強 , 英偉達全球開發者生態副總裁 Neil Trevett 。
可以說這場論壇匯聚了來自基礎模型研發、行業落地應用、算力平臺等多個關鍵環節的代表性力量 , 是一次不同路徑、不同視角的深入對話 。
在這場 30 分鐘的對話中 , 每一位嘉賓發言的背后 , 既是對技術路線的選擇 , 也關乎產業未來的走向 , 值得每一個人深思 。
一開場 , 林達華表示:「大模型技術發展到今天 , 可以說是在繁花似錦的背后 , 我們也進入到了一個十字路口 。 過去大半年的時間里 , 大模型的技術格局經歷了一個重要的范式轉變 。 從最初以預訓練為主、監督學習為輔的模式 —— 這一范式由 OpenAI 所開創 —— 逐漸向注重推理能力提升的強化學習范式過渡 。 這個轉變標志著 AI 領域在技術上的進一步演化 。 」
隨著這個觀點的拋出 , 這場圍繞大模型的圓桌論壇正式拉開帷幕 。
預訓練與強化學習
在大模型爆發初期 , 基本是以預訓練為主 , 比如 OpenAI 發布 GPT-4o 時 , 當時所有的計算資源都投入在預訓練上 。 很多人認為如果預訓練不足 , 模型能力上限將被鎖死 。
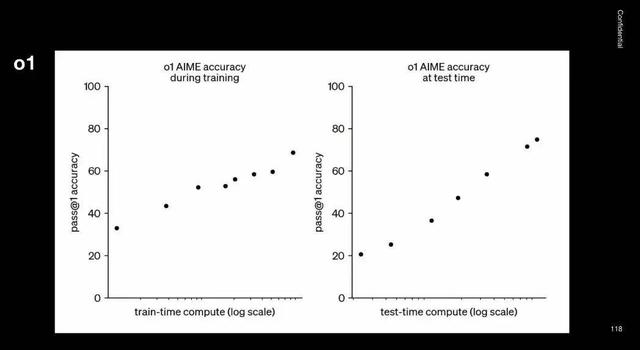
隨著 o1 的發布 , OpenAI 提出在預訓練好的模型上 , 用強化學習做后訓練(PostTraining) , 能顯著提高模型推理能力 。 如下圖左邊顯示隨著訓練時間的增加 , 模型性能隨之提升 。 這種走勢是每個訓練 AI 模型的人都熟悉的 。
右邊表明在「測試時間」增加時 , 模型的表現也會得到改善 。 這一發現代表了一個全新的擴展維度 —— 不僅僅是訓練時間擴展 , 還包括測試時間擴展 , 用到的訓練方法主要是強化學習 。
o1 的技術博客中展示了一張圖表:準確度和測試時計算之間存在對數線性關系 , o1 的性能隨著訓練時間和測試時的計算而平穩提高
在 OpenAI 看來 , 未來強化學習計算可能會成為主導 。
從 GPT-4o 到 o1 范式的轉變 , 不禁讓我們思考 , 原本由 OpenAI 所開創的以預訓練為主、監督學習為輔的范式 , 現在逐漸轉向了更加注重推理能力提升的強化學習范式 。 此外 , OpenAI 前首席科學家伊利亞也提出了類似觀點 , 預訓練時代即將終結 。
隨著推理模型的崛起 , 強化學習越來越得到大家重視 。 因此一個值得深思的問題被提出 , 預訓練和強化學習我們應該怎么平衡?
張祥雨首先肯定了這套范式的合理性(從預訓練到監督微調再到 RL) 。 對于預訓練而言 , 本質就是壓縮語料的一個過程 , 之后在模型內部形成一個更加緊湊的表示 。 這個表示對模型學習世界知識和建模非常有幫助 。
但與此同時 , 預訓練通常基于 Next Token 預測 , 這其實是一種行為克隆的形式 。 而行為克隆傳統上被認為存在一些難以規避的問題 —— 比如無論你用了多少數據、模型做得多大 , 它都很難真正建立起目標導向的推理能力 。
因為壓縮只是盡可能復現已有內容 , 而推理本質上是要求模型能找到一條邏輯自洽、通向目標的因果鏈 。 因此 , RL 應運而生 。
張祥雨還指出了未來這條范式的發展方向 , 他認為如何進一步擴展 RL , 使其能夠接受自然語言反饋 , 而不僅僅是像數學、代碼這種確定性反饋很關鍵 。
在張祥雨的分享中 , 我們捕捉到了一個非常重要且值得深思的技術范式拓展 , 那就是將強化學習進一步延伸到大規模預訓練 。 特別是在推理階段(即 Test Time)使用強化學習來增強推理性能 , 這確實是一個非常具有啟發性的建議 。
陳愷則強調了預訓練的重要性 。 他表示 , 強化學習之所以能夠大放異彩 , 是因為它依賴于一個強大的冷啟動模型 。 過去 , 冷啟動模型可能依賴于預訓練和監督學習(SFT) , 但現在大家對預訓練的重視程度逐漸提高 。 預訓練為強化學習提供了一個良好的基礎 , 使其能夠探索多種未來的可能性 , 從而發揮其應有的作用 。
陳愷進一步討論了強化學習未來面臨的挑戰 , 即獎勵或反饋機制的問題 。 這個問題將成為強化學習進一步拓展到更多任務時的一個關鍵挑戰 。 目前 , 強化學習主要用于解決一些有明確答案的任務 , 比如填空和問答題 , 但實際上 , 許多有效且有價值的任務并沒有唯一確定的答案(這和張祥雨的觀點類似) 。 因此 , 強化學習需要探索新的獎勵和反饋機制 , 這可能依賴于新的評價標準 , 或者通過與環境的實際交互反饋來形成獎勵體系 。
此外 , 陳愷還表示強化學習也給基礎設施帶來了新的挑戰 。 盡管強化學習已經取得了一些進展 , 但從效率上來看 , 仍然存在較大的提升空間 。 強化學習需要大量算力 , 且模型需要不斷進行探索和學習 。 如果未來強化學習開始依賴更多的交互反饋 , 這對基礎設施的要求將會更高 , 對相關技術和資源的挑戰也將更加嚴峻 。
Transformer 架構與非 Transformer 架構
在整個模型研發過程中 , 訓練范式是非常重要的一部分 , 而訓練范式又依托于高效的模型架構 。
從 2017 年至今 , Transformer 統治 AI 領域已經八年之久 。 如果從 2019 年的 GPT-2 出發 , 回顧至 2024–2025 年的 ChatGPT、 DeepSeek-V3 、LLaMA 4 等主流模型 , 不難發現一個有趣的現象:盡管模型能力不斷提升 , 但其整體架構基本保持高度一致 。
然而 , 隨著模型參數飆升至千億級、上下文窗口拉伸至百萬 Token , Transformer 的一些限制開始顯現 。比如 , 其最大的問題是自注意力機制的 O (n^2) 擴展性 , 當序列長度 n 增加時 , 計算量和內存占用呈平方級增長 。 其次 , 注意力機制需要存儲大量中間結果和 KV 緩存 , 顯存很快被占滿;第三 , Transformer 缺乏顯式的長期記憶機制 , 導致在需要多步推理或跨文檔對齊的任務上 , 小樣本泛化能力急劇下降 。
對此 , 業界和學界開始新的探索 , 他們主要沿著兩條技術路線展開 。
一是優化現有 Transformer 架構 , 例如 , 位置編碼從最初的絕對位置發展為旋轉位置編碼(RoPE);注意力機制也從標準的多頭注意力逐步過渡為更高效的分組查詢注意力(Grouped-Query Attention) , 另外在激活函數方面 , GELU 被更高效的 SwiGLU 所取代 。
另一條則是跳出 Transformer , 探索全新架構范式 。 如 Mamba 系列通過狀態空間模型(SSM)實現線性復雜度的長序列建模 , 展現出比 Transformer 更優的延遲性能與可控推理能力;RetNet、RWKV 等結構則融合了 RNN 的記憶優勢與 Transformer 的并行性 , 力圖找到效率與能力的最優平衡點 。
值得注意的是 , 當前的大模型架構發展也呈現出混合設計趨勢 , 如由 AI21 Labs 推出的 Jamba 就是混合架構典型 , 其結合了經典的 Transformer 模塊和 Mamba 模塊 。
年初發布的 DeepSeek V3 表明 , 即使是優化現有 Transformer 架構 , 也可以大幅度降低模型訓練和推理成本 。 這就帶來一個值得深思的問題:我們是基于 Transformer 架構進行創新?還是開發非 Transformer 架構?
對于這一問題 , 張祥雨表示 , 模型架構并不是最重要的決定因素 , 架構是為系統和算法服務的 。 Transformer 架構沒有問題 。 現在流傳下來的仍然是最經典的 Transformer 架構 。
但現在的問題是 , 算法開始向 RL 遷移 , 而我們的應用場景也從推理時代向智能體時代轉變 。 而智能體最重要的特性是自主性 , 它必須能夠主動與環境交互 , 并從環境中進行學習 。
這就意味著 , 我們的模型架構需要具備類似人類的能力 , 能夠建模一種無限流或無限上下文的能力 。 因此 , 張祥雨認為 , (在智能體時代)傳統模式已經遇到了阻礙 , 像是傳統的 RNN 架構 , 未來短時間內可能會重新成為下一代主流架構的設計考慮之一 。
真實數據與合成數據之爭
但我們不可忽視的是 , 大模型的背后 , 還有數據 。 過去 , AlexNet 及其后續工作解鎖了 ImageNet , Transformer 的興起解鎖了海量的互聯網數據 。 然而今天 , 我們正面臨一個殘酷現實:高質量語料正在趨于枯竭 。 隨著已被爬取的內容越來越多 , 邊際新增的優質數據正在減少 。
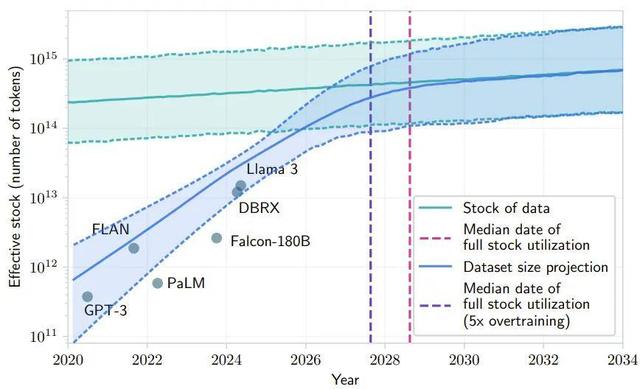
有研究預計 , 如果 LLM 保持現在的發展勢頭 , 預計在 2028 年左右 , 已有的數據儲量將被全部利用完 。 屆時 , 基于大數據的大模型的發展將可能放緩甚至陷入停滯 。 與此同時 , 擁有版權、隱私等限制的數據 , 更是加劇了垂直領域的發展 。
圖源:來自論文《Will we run out of data? Limits of LLM scaling based on human-generated data》
在此背景下 , 合成數據被寄予厚望 , 國內外很多公司開始采用這種方式 。 比如 Anthropic 首席執行官 Dario Amodei 曾經表示 , 對于高質量數據耗盡的困境 , Anthropic 正在嘗試模型合成數據的方法 , 也就是使用模型生成更多已有類型的數據 。 這一策略也在 OpenAI、Meta、Google DeepMind 等公司的新一代模型訓練中被廣泛應用 。
然而 , 合成數據在一定程度上緩解了數據難題 , 但它本身也引發了一系列新的挑戰與隱憂 。 2024 年登上《自然》封面的一項研究認為如果放任大模型用生成的數據進行訓練 , AI 可能會崩潰 , 在短短幾代內將原始內容迭代成無法挽回的胡言亂語 。
一邊是高質量數據資源日漸枯竭 , 另一邊則是對合成數據的高度依賴與不確定性并存 。
這種擔憂 , 也發生在英偉達內部 。 Neil Trevett 表示 , 英偉達在圖形生成和物理仿真方面也面臨數據困擾的問題 , 尤其是那些無法獲取、獲取成本高、涉及倫理風險或隱私問題的數據 。
圓桌現場 , Neil Trevett 給出了英偉達的一個解決思路 , 利用物理仿真生成模擬場景 , 用來訓練大模型 。 這種方式尤其適用于構造一些在真實世界中難以采集的邊緣案例 , 比如交通事故場景 , 或者機器人遇到異常情況時的應對 。
【硬核「吵」了30分鐘:這場大模型圓桌,把AI行業的分歧說透了】不過 , Neil Trevett 也強調:不能完全依賴合成數據 。 用于合成數據的生成模型本身可能存在偏差、誤差或盲區 , 因此需要建立真實世界的驗證機制和反饋閉環 , 比如通過 human-in-the-loop 的方式 , 來輔助驗證訓練效果是否真實可用 。 Neil Trevett 還給出了幾個非常有前景的技術路徑 , 包括自監督學習、主動學習、混合式訓練流程等 。
王紹蘭則給出了不一樣的觀點 , 他認為對于預訓練而言 , 大家常提到的互聯網數據耗盡 , 其實是一個量的問題 , 可能更關鍵的是質的問題 。 也就是說 , 當初大模型所依賴的大量互聯網數據 , 它們的質量是否真的足夠好?這需要重新審視 。 接下來應該是進一步提升預訓練數據中的質量 。
王紹蘭還提到所謂數據耗盡并不像大家說的那樣夸張 , 原因是行業數據還沉淀在行業中 , 沒有被用來訓練模型 。 因此大模型想要落地到行業中去 , 必須用行業數據進行預訓練 。
關于合成數據問題 , 王紹蘭認為隨著大模型場景的不斷擴展 , 一些場景數據是極其稀缺的 , 甚至是完全不存在的 。 因此 , 只能依賴合成數據和仿真環境來補足 。
然而 , 這種做法會帶來一系列挑戰 , 如果仿真不夠真實 , 那么生成的數據也會存在偏差 , 最終會影響模型訓練效果 。 因此 , 我們不能把合成數據看作一個萬能鑰匙 , 它有價值 , 但不能解決一切問題 , 背后仍有大量工程上的挑戰需要克服 。
最后 , 王紹蘭還建議:對于行業中非敏感、非涉密的關鍵數據 , 應當考慮在行業內部建立數據共享機制或聯盟組織 , 共同挖掘、整理這些數據 , 為大模型在各類實際場景中的應用提供更可靠的「彈藥庫」 。 這一建議一發出 , 現場掌聲不斷 。
基礎模型與 Agent 向左向右
從來不是一道單選題
進入到 2025 年 , 我們可以觀察到一個很明顯的趨勢 , 基礎模型的研發速度逐漸放緩 , 而以 Agent 為代表的應用成為了爆點 。 國內外廠商陸續推出了自動化執行任務的 Agent 產品 , 比如 OpenAI 推出的 Operator、深度研究以及 ChatGPT agent、智譜 AI 推出的 AutoGLM 沉思等 。
這正是隨著大模型進入到應用深水區以來 , 行業內加速構建商業閉環并著眼產業落地的真實寫照 。 同時 , 對于一些以 AGI 為終極目標的廠商來說 , 基礎模型的研發同樣不會停滯 。 如何平衡基礎模型投入與應用落地之間的關系 , 成為廠商在戰略決策層面的核心議題 。
智譜在持續迭代基座大模型 GLM 系列 , 覆蓋語言模型、多模態模型等的同時 , 也積極推動大模型在各行各業的落地 。 面對這種雙軌布局是否太分散精力的疑問 , 王紹蘭表示兩者并不沖突 。
一方面 , 基礎模型仍處于快速演進的階段 , 行業普遍對當前模型成果感到振奮 , 但距離 AGI 的目標仍有較大差距 。 如果類比自動駕駛的分級 , 當前大模型大致處于 L3 階段 , 僅完成了預訓練、對齊與基礎推理 , 并剛剛進入到了具備反思與沉思能力的深度推理階段 。 未來仍需要繼續進化 , 即使是 OpenAI 即將發布的 GPT-5 , 與 AGI 仍有距離 。 他認為 , 包括智譜在內 , 對基礎模型的探索將持續下去 。
另一方面 , 王紹蘭也強調 , 模型的價值不應只停留在純理論研究層面 。 如果不展開模型的商業化落地 , 它們的價值就無從體現 。 大模型要「用起來」 , 直至變成生產力革命的那一天 。 如今 , 大模型正通過 Agent 等形態拓展自身應用 。 同時在落地的過程中 , 各行各業的領軍企業和生態伙伴也要具備大模型思維 , 積極擁抱這場范式變革 。
同樣地 , 第四范式在大模型落地方面也走在了行業前列 , 尤其是將 AI 技術應用于金融等重點行業 。 對于如何平衡基礎模型的持續研發與行業應用落地 , 陳雨強首先指出在技術發展極為迅速的當下 , 要保證自身在行業中的競爭力 , 其中最關鍵的是要用好已有的開源或閉源模型 。
接著 , 陳雨強談到了基礎模型能力以及引發的數據問題 。 當前 , 已經有超過 30% 的流量來自模型輸出而非傳統搜索引擎 , 這也導致面臨人為破壞數據等風險 。 此外 , 用于評估大模型的工具(如 Arena)雖有價值 , 但也存在局限 。 很多普通用戶不關心答案是否真的正確 , 而是像不像好答案 , 這就導致排版精美的算法在輸出結果時得分更高 , 進一步加劇數據偏差問題 。
最后 , 他提到 , 在企業落地中 , 尤其涉及金融等高敏感領域 , 仍存在諸多挑戰 。 比如在反欺詐場景 , 基礎大模型難以直接處理像每天十億用戶交易記錄這樣的大規模數據輸入 。 這意味著 , 大模型的落地要在基礎模型能力、數據質量等多個層面持續進行技術突破 。
開源模型即使非最強
也能鞭策整個行業進步
除了訓練范式、架構的持續進化以及解決數據瓶頸之外 , 開源與閉源同樣影響著大模型技術路徑的選擇、產業生態的構建以及人工智能的格局 。
一直以來 , AI 領域便存在著開源與閉源兩大陣營 。 在國內外頭部大模型廠商中 , OpenAI 在 GPT-3 之后就完全轉向了閉源 , 而以 LLaMA、DeepSeek、Qwen、Kimi 等為代表的開源模型陣營 , 正不斷逼近甚至部分超越閉源大模型的性能表現 。
其中 , DeepSeek 的開源模型憑借其優異的性能和極低的部署成本 , 迅速在全球范圍內獲得了廣泛關注和應用 , 甚至對以英偉達 GPU 和閉源模型為主導的傳統 AI 產業鏈構成了沖擊 。 可以預見 , 開源與閉源將在未來的 AI 生態中持續展開博弈 。
陳愷從自己多年來的開源領域經驗出發 , 探討了開源如何在大模型時代產生深遠影響 。 就在昨天 , 他所在的上海人工智能實驗室開源了「書生」科學多模態大模型 Intern-S1 , 并基于此打造了「書生」科學發現平臺 Intern-Discovery 。
在他看來 , 一方面 , 開源不僅重塑行業內不同玩家之間的分工與資源投入方式 , 還推動了資源的更合理配置 。 另一方面 , 盡管開源模型未必是性能最強的 , 但它能夠有效避免重復投入 , 促使廠商專注于真正需要解決的問題 。
更重要的是 , 對于行業內仍在訓練基礎模型并以 AGI 為終極目標的玩家來說 , 開源無疑形成一種實質性壓力:如果閉源模型比不過開源成果 , 其存在價值可能就會受到質疑 。 因此 , 開源不一定總能做到最好 , 卻能鞭策整個行業以更高效的方式持續演進 。
而作為全球領先的芯片供應商 , 英偉達高度重視并持續支持全球 AI 生態的發展 , 并投入很多 。 特別在開源方面 , 英偉達為開源大模型訓練與部署提供了算力引擎 , 通過強大的芯片、好用的工具讓模型易用性更強 。
Neil Trevett 表示 , 開源的力量毋庸置疑 , 如其他技術領域一樣 , 開源是推動 AI 行業前進的強大「工具」 。 然而 , 開源是否適合每家公司 , 需要他們根據自身成本效益和競爭策略來判斷 , 比如開源是否能節省成本、是否會削弱自身競爭優勢等 。 因此 , 他認為 , 未來行業可能會走向開源與閉源結合的混合模式 。
同時 , 開源也帶來了一些新挑戰 , 比如模型分叉、碎片化和濫用 , 需要行業共同探索治理方式 。 Neil Trevett 堅信 , 隨著行業的發展 , 這些都會逐步得到解決 。
至此 , 這場圓桌論壇畫上了圓滿的句號 。 從訓練范式到架構演進 , 從數據焦慮到開源閉源之爭 , 再到 Agent 落地與行業融合 , 這場由商湯承辦的「模型之問」圓桌論壇 , 展現了大模型時代最真實的技術分歧 , 也匯聚了業界最權威的思考 。
這場硬核辯論 , 或許正是 AI 行業走向成熟的重要一步 。
推薦閱讀















- 清華&騰訊混元X發現「視覺頭」:僅5%注意力頭負責多模態視覺理解
- 萬億美元新大陸!誰將主宰「人機共生」智能體經濟時代?
- 多模態大模型學會回頭「看」:中科院自動化所提出GThinker模型
- 摩爾線程WAIC亮出硬核科技:國產全功能GPU加速AI與千行百業
- AI領域的「賣鏟人」涌現WAIC,行業的“掘金時刻”正在到來
- WAIC 2025︱中國電信AI科技范兒圈粉全場 智慧車、“鋼鐵俠”硬核應用成焦點
- 具身智能,騰訊「低調入局」
- WAIC機器人探展:我被全場最靚的崽「Moz1」種草了
- 短片可以不「爽」嗎?vivo X FIRST 給了肯定答案
- 榮耀全新千元機:8300mAh+滿級防水+硬核抗摔,實用性滿分