文章圖片

文章圖片

文章圖片

文章圖片

文章圖片

文章圖片

文章圖片

文章圖片

文章圖片

文章圖片

文章圖片

文章圖片

機器之心報道
作者:楊文、杜偉
最近 , 一個長相酷似韓國影星河正宇的博主 , 在 TikTok 上發視頻吐槽:「老婆總是喜歡亂 P 我睡覺的照片 , 咋整?」
本以為是撒狗糧 , 沒想到還真撞上了 P 圖界的邪修大神 。 她總能把千奇百怪的睡姿 , 恰到好處地融進各種場景 , 腦洞大得能隨機笑死一個路人 。
視頻來源:https://www.tiktok.com/@awakesoul3
這看似沙雕的 P 圖背后 , 其實揭示出了一個趨勢:圖像編輯的需求正變得越來越個性化 , 也對工具的智能化程度提出了更高的要求 。
就在今天 , 火山引擎整個大活 , 發布了豆包?圖像編輯模型 SeedEdit 3.0 , 并上線火山方舟 。
體驗地址:https://console.volcengine.com/auth/login/
作為豆包家族的重要成員 , 圖像編輯模型 3.0 主打一個「全能且可控」 。
具體來說 , 它有三大優勢:更強的指令遵循、更強的主體保持、更強的生成質量 , 特別是在人像編輯、背景更改、視角與光線轉換等場景中 , 表現更為突出 , 還在多項關鍵編輯指標之間取得了極佳平衡 。
舉個例子 。 它能一鍵更換雜志封面文字 , 同時保持其他元素不變:
Prompt:Change 'MORE' to 'MAGAZINE'
或者隨意調整打光、畫面氛圍:
Prompt:保持畫面不變 , 室內黑暗 , KTV 氛圍 , 球形燈 , 五顏六色燈光
甚至一句模糊指令就能讓電商產品海報替換背景:
Prompt:根據圖中物品的屬性替換背景為其適合的背景場景
接下來 , 咱們就實測一把 , 看看升級后的圖像編輯模型 3.0 到底有多硬核 。
一手實測
AI 修圖 , 看不出「科技與狠活」
AI 圖像編輯模型的出現 , 讓許多手殘黨都成了 P 圖達人 , 不過問題也隨之而來:用嘴 P 圖固然方便 , 但這些 AI 往往會出現「誤傷」 。
比如你只想改個背景 , 結果人物的面部和姿勢卻變了;你明明下達了精準的指令 , 它們卻偏偏聽不懂「人話」 , 對著原圖一頓亂改;好不容易搞對了主體和背景 , 畫面又丑得別具一格 。
現在好了 , 豆包?圖像編輯模型 3.0 已經解決這些「通病」 , 只需一句簡單的提示詞 , 就能針對畫面元素增、刪、改、替 。
打字 P 圖 , 指哪改哪
日常生活中 , 大概每個人都會遇到這些抓狂的瞬間:出門旅游拍照 , 忍著羞恥心凹好造型 , 卻半路殺出個路人甲亂入鏡頭;想用明星美照當壁紙 , 但正中間打著又大又丑的水印 , 裁剪都無從下手 。
這時 , AI 消除功能就派上用場 。
比如在泰勒?斯威夫特的街拍場景中 , 豆包?圖像編輯模型 3.0 可以精準鎖定黃衣女生和水印 , 完成雙重清除 , 同時還不傷及主體人物和背景細節 。
提示詞:刪除穿黃衣服的女生 , 刪除水印 , 其他要素保持不變 。
它還能同時處理消除路人、雨傘變色兩項復雜任務 。 路人消失后背景自然補全 , 毫無 PS 痕跡;雨傘變色也嚴格鎖定目標物體 , 未波及人物服飾或環境 。
提示詞:消除后面兩個路人 , 雨傘變成紅色 , 其他元素保持不變 。
如果感覺畫面平平無奇 , 想增加點元素提升視覺沖擊 , 同樣只需一句指令 , 就能讓安妮?海瑟薇體驗一把「房子著火我拍照」的刺激 。
提示詞:后面的房子著火了 。
再來試試 AI 替換功能 。 什么換文字、換背景、換動作、換表情、換風格、換材質…… 豆包?圖像編輯模型 3.0 通通可以搞定 。
比如 , 把汽水瓶上的文字「夏日勁爽」改為「清涼一夏」 , 它不僅沿用原有字體設計 , 還保留了所有的背景元素 。
提示詞:圖中文字 “夏日勁爽” 改為 “清涼一夏” 。
再比如 , 把梅西和 C 羅自拍照的背景 , 從上海外灘瞬移至悉尼歌劇院 , 看來以后只要動動嘴就能打卡全球各大熱門景點了 。
或者將人物動作替換為「懷抱小狗」 , 畫面沒有出現穿幫或者比例失調的情況 。
提示詞:這個女生抱著一只小狗 。
此外 , 豆包?圖像編輯模型 3.0 還能轉換風格 , 比如水彩風格、吉卜力風格、插畫風格、3D 風格等 。
圖 1 為原圖;圖 2 為水彩風格;圖 3 為吉卜力風格;圖 4 為新海誠風格
除了以上常規功能 , 豆包?圖像編輯模型 3.0 還有不少進階玩法 , 包括光影變化、黑白照片上色、商業海報制作、線稿轉寫實等 。
在完整保留海邊靜物原始構圖的基礎上 , 該模型精準重構黃昏暖色調光影 , 使藍白格子桌布、玫瑰花與海面均自然鍍上落日余暉 。
提示詞:保持原畫面內容不變 ,更改光影黃昏風格光影 。
給黑白照片上色時 , 我們還可以自定義風格 , 比如輸入「日系風格」 , 直出膠片感大片 , 氛圍感拉滿 。
提示詞:給這張照片上色 , 日系風格 。
我們還可以制作商業產品海報 , 比如讓它根據物品的屬性替換為適合的背景 , 并在海報上添加字體 。 這下電商老板們該狂喜了 , 畢竟一年也能省不少設計成本 。
提示詞:根據圖中物品的屬性替換為其適合的背景場景 , 畫面中自然融入以下文案文字: 主標題為 “清新自然 靜謐之選” 副標題為 “感受肌膚的舒緩之旅” 字體設計感高級 , 排版自然協調 , 不添加任何邊框、裝飾線、圖框或圓角 , 僅保留通透畫面與內容構圖 , 適合作為品牌宣傳海報 , 瓶身其他元素保持不變
提示詞:將圖中背景換成沙灘
或者把服裝和建筑設計的線稿轉成寫實風格 。
提示詞:根據線稿改為真實人物、真實服裝
提示詞:把這個線稿圖改為真實的場景
一番體驗下來 , 我們也摸到了提示詞撰寫的門道:
每次編輯使用單指令會更好; 盡量使用清晰、分辨率高的底圖; 局部編輯時指令描述盡量精準 , 尤其是畫面有多個實體的時候 , 描述清楚對誰做什么 , 能獲取更精準的編輯效果; 發現編輯效果不明顯的時候 , 可以調整一下編輯強度 scale , 數值越大越貼近指令執行 。與 GPT-4o、Gemini 2.5 Pro 掰掰手腕
目前 , 市面上有不少模型可以執行圖片編輯功能 , 比如曾在全球刮起「吉卜力熱」的 GPT-4o、谷歌大模型扛把子 Gemini 2.5 Pro , 它們的 P 圖效果究竟如何 , 還得來個橫向對比 。
Round 1:文字修改
在針對商業海報文字編輯任務的測試中 , 通用大模型暴露出了文字生成短板 。
GPT-4o 將畫面中的文字替換為無法辨認的亂碼 , Gemini 2.5 Pro 則未嚴格遵循替換指令 , 而是在原海報文字的下方進行了文字添加 。
只有豆包?圖像編輯模型 3.0 精準完成「店家推薦」文字替換 , 還保留了原字體材質與背景元素 , 也沒有出現「鬼畫符」等缺陷 。
圖 1: 原圖;圖 2: 豆包?圖像編輯模型 3.0;圖 3:GPT-4o;圖 4:Gemini2.5 pro;提示詞:把文字「金絲酥單品」改成「店家推薦」 , 其他元素不變
Round 2:風格轉換
我們讓這三款大模型把寫實人物攝影照片轉成涂鴉插畫風格 , 豆包?圖像編輯模型 3.0 嚴格遵循雙重約束指令 , 生成的畫面審美也在線 。
相比之下 , GPT-4o 和 Gemini 2.5 Pro 改出來的圖看起來更像隨意畫的兒童涂鴉 , 女孩的五官有些模糊走樣 , 背景的細節也丟失不少 。
圖 1: 原圖;圖 2: 豆包?圖像編輯模型 3.0;圖 3:GPT-4o;圖 4:Gemini2.5 pro;提示詞:保持背景結構 , 保持人物特征 , 風格改成涂鴉插畫風格
Round 3:物體、文字消除
再來對比下 AI 消除功能 。
原圖元素較多 , 路人、店招 , 還有一行淺淺的水印 , 豆包?圖像編輯模型 3.0 成功消除畫面中所有路人及文字 , 包含店鋪招牌 , 同時精準修復背景空缺區域 。
而 GPT-4o 和 Gemini2.5 Pro 的消除功能總是「丟三落四」 , GPT-4o 忘記刪除店招 , Gemini2.5 Pro 則只 P 掉了水印 , 其他指令要求一概忽視 。
圖 1: 原圖;圖 2: 豆包?圖像編輯模型 3.0;圖 3:GPT-4o;圖 4:Gemini2.5 Pro;提示詞:保留滑板男孩 , 刪除畫面中所有路人 , 并刪除所有文字 , 其他元素不變
整體而言 , 相較于 GPT-4o 和 Gemini 2.5 Pro , 豆包?圖像編輯模型 3.0 理解指令更到位 , 改圖效果更精準自然 , 尤其是「文字生成」功能 , 幾乎不用抽卡 , 完全可以達到商用的程度 。
技術揭秘
從模型架構到推理加速 , 全方位進化
煉成這樣一個超級實用、易用且好玩的 P 圖神器 , 豆包?圖像編輯模型 3.0(以下統稱 SeedEdit 3.0) 依托的是一整套技術秘籍 。
作為 AIGC 領域的重要分支 , 可編輯的圖像生成要解決結構與語義一致性、 多模態控制、局部區域精細編輯、前景背景分離、融合與重建不自然、細節丟失與偽影等一系列技術難題 。
基于豆包文生圖模型 Seedream 3.0 , SeedEdit 3.0 很好地解決了上述難題 , 在圖像主體、背景和細節保持能力上進一步提升 。 在內部真實圖像測試基準測試中 , SeedEdit 3.0 更勝其他模型一籌 。
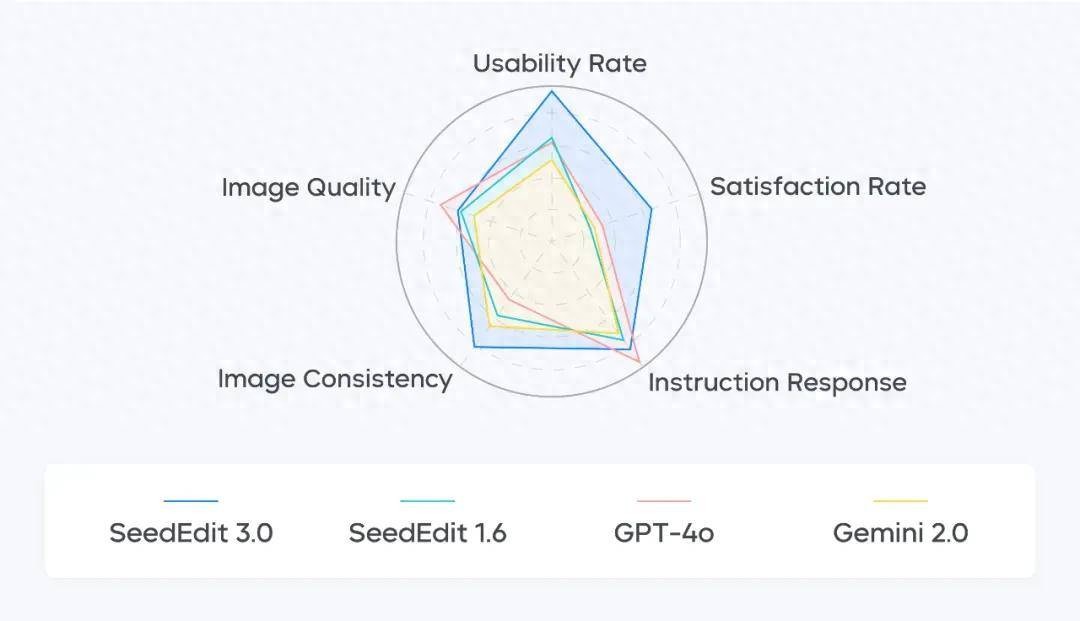
定量比較結果如下所示 , 其中左圖利用 CLIP 圖像相似度評估模型編輯保持效果 , SeedEdit 3.0 領先于前代 1.0、1.5、1.6 以及其他 SOTA 模型 Gemini 2.0、Step1X 和 GPT-4o , 僅在指令遵循方面不如 GPT-4o;右圖顯示 SeedEdit 3.0 在人臉保持方面具有明顯優勢 。
下圖為部分定性比較結果 , 直觀來看 , SeedEdit 3.0 在動作自然度、構圖合理性、人物表情與姿態還原性、視覺一致性、清晰度與細節保留等多個維度上表現更好 。
為了達成這樣的效果 , SeedEdit 3.0 團隊從數據、模型和推理優化三個層面進行了深度優化與創新 。
首先是數據層面 , 一方面引入多樣化的數據源 , 包括合成數據集、編輯專家數據、傳統人工編輯操作數據以及視頻幀和多鏡頭數據 , 并包含了任務標簽、優化后的描述和元編輯標記信息(下圖) 。 而基于這些數據 ,模型在真實數據與合成的「輸入 - 輸出編輯空間」中進行交錯學習 , 既不損失各種編輯任務的信息 , 又提升對真實圖像的編輯效果 。
另一方面 , 為了有效地融合不同來源的圖像編輯數據 , 團隊采用了一種多粒度標簽策略 。 對于差別比較大的數據 , 通過統一任務標簽區分;對于差別較小的數據 , 通過加入特殊 Caption 區分 。 接下來 , 所有數據在重新標注、過濾和對齊之后進行正反向的編輯操作訓練 , 實現全面梳理和整體平衡 。
可以說 , 更豐富的數據源以及更高效的數據融合 , 為 SeedEdit 3.0 處理復雜圖像編輯任務提供了強大的適應性和魯棒性 。
其次是模型層面 , SeedEdit 3.0 沿用了 SeedEdit 的架構 , 底部視覺理解模型從圖像中推斷出高層次語義信息 , 頂部因果擴散網絡充當圖像編碼器來捕捉細粒度細節 。 此外 , 視覺理解與擴散模型之間引入了一個連接模塊 , 將前者的編輯意圖(比如任務類型和編輯標簽等)與后者對齊 。
在此基礎上 , 團隊將文生圖模型 Seedream 2.0 中的擴散網絡升級為 Seedream 3.0 , 無需進行任何細化便可以原生生成 1K 至 2K 分辨率圖像 , 并增強了人臉與物體特征等輸入圖像細節的保留效果 。 得益于此 , 模型在雙語文本理解與渲染方面的能力也得到了增強 , 并可以輕松擴展到多模態圖像生成任務 。
SeedEdit 3.0 模型架構概覽
而為了訓練出現有架構 , 團隊采用了多階段訓練策略 , 包括預訓練和微調階段 。 其中 , 預訓練階段主要對所有收集的圖像對數據進行融合 , 通過圖像多長寬比訓練、多分辨率批次訓練 , 使模型從低分辨率逐步過渡到高分辨率 。
微調階段則主要優化輸出結果以穩定編輯性能 , 過程中重新采樣大量精調數據并從中選出高質量、高分辨率樣本;然后結合模型過濾器和人工審核對這些樣本二篩 , 兼顧高質量數據和豐富編輯類別;接下來利用擴散損失對模型進一步微調 , 尤其針對人臉身份、美感等對用戶價值極高的屬性 , 引入特定獎勵模型作為額外損失 , 提升高價值能力表現;最后對編輯任務與文本到圖像任務聯合訓練 , 既提升高分辨率圖像編輯效果 , 又增強泛化性能 。
為了實現更快的推理加速 , SeedEdit 3.0 采用了多種技術手段 , 包括蒸餾、無分類器蒸餾、統一噪聲參照、自適應時間步采樣、少步高保真采樣和量化 。 一整套的方案 , 讓 SeedEdit 3.0 大幅縮短了從輸入到輸出的時間 , 并減少計算資源的消耗 , 節省更多內存 。
最終 , 在蒸餾與量化手段的多重加持下 , SeedEdit 3.0 實現了 8 倍的推理加速 , 總運行時長可以從大約 64 秒降至 8 秒 。 這樣一來 , 用戶等待的時間大大降低 。
想要了解更多技術與實驗細節的小伙伴 , 請參閱 SeedEdit 3.0 技術報告 。
技術報告地址:https://arxiv.org/pdf/2506.05083
寫在最后
也許 AI 圈的人已經注意到了 , 最近一段時間 , 包括圖像、視頻在內 AIGC 創作領域的關注度有所回落 , 尤其相較于推理模型、Agent 等熱點略顯安靜 。 然而 , 這些賽道的技術突破與產品演進并沒有停滯 。
在國外 , 以 Midjourney、Black Forest Labs 為代表的 AI 生圖玩家、以 Runway、谷歌 DeepMind 為代表的 AI 視頻玩家 , 繼續模型的更新迭代 , 推動圖像與視頻生成技術的邊界 , 提升真實感與創意性 。 而國內 , 以字節跳動、阿里巴巴、騰訊為代表的頭部廠商在圖像、視頻生成領域依然高度活躍 , 更新節奏也很快 , 從技術突破與應用拓展兩個方向發力 。
這些頭部廠商推出的大模型產品還通過多樣化的平臺和形態廣泛觸達用戶 , 比如 App、小程序等 , 為創作者提供了便捷的內容創作工具 。 這種「模型即產品」的能力既提升了易用性 , 也激發了用戶的參與感與創造力 。
就拿此次的豆包?圖像編輯模型 3.0 來說 , 它在國內首次做到了產品化 , 無需像傳統圖像編輯軟件一樣描邊涂抹、修修補補 , 輸入簡單的自然語言指令就能變著花樣 P 圖 。 我們在實際體驗中已經感受到了它的魔力 , 換背景、轉風格以及各種元素的增刪與替換 , 幾乎無所不能 。
該模型的出現無疑會帶來圖像創作領域的一次重大轉型 , 跳出傳統圖像編輯的桎梏 , 邁入到自動化、智能化、創意化的階段 。 這意味著 , 沒有專業化技能的 C 端普通用戶得到了一個強大的圖像二創工具 , 在大幅提升創作效率的同時還能解鎖更多創意空間 。
當然 , 豆包?圖像編輯模型 3.0 的應用潛力不局限于日常的修圖需求 , 隨著更加深入地挖掘廣泛的行業特定需求 , 未來它也有望在影視創作、廣告設計、媒體、電商、游戲等 AIGC 相關的 B 端市場激發新的應用潛力 , 助力企業提高內容生產效率 , 在競爭中用 AI 搶占先機 。
【P圖手殘黨有救了,豆包·圖像編輯模型3.0,一個對話框搞定增刪改替】利用該模型 , 影視制作團隊可以快速調整鏡頭畫面、添加特效、替換背景等 , 從而簡化制作流程、縮短制作周期;電商商家可以快速定制化產品圖像和宣傳圖 , 并根據消費者偏好和市場需求進行個性化創作;游戲開發者可以快速調整角色、場景的設計元素 , 節省時間 。 這些看得見的應用前景 , 顯然會帶來顛覆性的變化 , 推動行業朝著高效、便捷的方向演進 。
推薦閱讀












- 鴻蒙5.1生態加速跑 超多設備可升級解鎖獨有體驗
- Meta太能“搶錢”,難怪小扎有底氣瘋狂搶人
- 有這桌搭太簡單,伸縮線材+多口快充,安克桌面充mix上手體驗
- 預算只有兩千元該買什么手機?選一加Ace 5至尊版
- 7000大電池+高通新神U+IP65防水防塵,這款899的神機有點猛啊
- 從數字人到有溫度的機器人,京東把 AI 深度應用的路線圖「摸透」了
- 聯想moto razr60冰鉆限定版下周發,還有限定版耳機
- 三星多款新機、平板曝光,外觀有變動
- 炸圈的ChatGPT Agent ,到底有哪些能耐?能不能替代普通牛馬?
- 大模型隱私安全和公平性有“蹺蹺板”效應,最佳平衡法則剛剛找到