
文章圖片

文章圖片
文章圖片

文章圖片

文章圖片

文章圖片

文章圖片

文章圖片
文章圖片

文章圖片
文章圖片

文章圖片

本文第一作者為新加坡國立大學博士生高崇凱 , 其余作者為新加坡國立大學博士生劉子軒、實習生池正昊、博士生侯懿文、碩士生張雨軒、實習生林宇迪 , 中國科學技術大學本科生黃俊善 , 清華大學本科生費昕 , 碩士生方智睿 , 南洋理工大學碩士生江澤宇 。 本文的通訊作者為新加坡國立大學助理教授邵林 。
為什么機器人能聽懂指令卻做不對動作?語言大模型指揮機器人 , 真的是最優解嗎?端到端的范式到底是不是通向 AGI 的唯一道路?這些問題背后 , 藏著機器智能的未來密碼 。
近期 , 新加坡國立大學邵林團隊發表了一項突破性研究 VLA-OS , 首次系統性地解構和分析了機器人 VLA 模型進行任務規劃和推理 , 進行了任務規劃表征與模型范式的統一對比 。 這項工作通過系統、可控、詳細的實驗對比 , 不僅為研究者提供了翔實的研究成果 , 更為下一代通用機器人 VLA 模型指明了方向 。
通過 VLA-OS , 你可以獲得什么:
VLA 通用設計指南; 結構清晰的 VLA 代碼庫 , 擁有集各家之所長(RoboVLM、OpenVLA-OFT)的先進設計; 標注好的多模態任務規劃數據集; 規范的 VLA 訓練流程 。 VLA 的未來發展方向啟示 。
??論文標題:VLA-OS: Structuring and Dissecting Planning Representations and Paradigms in Vision-Language-Action Models Arxiv:https://arxiv.org/abs/2506.17561 項目主頁:https://nus-lins-lab.github.io/vlaos/ 源代碼:https://github.com/HeegerGao/VLA-OS 數據集:https://huggingface.co/datasets/Linslab/VLA-OS-Dataset 模型:https://huggingface.co/Linslab/VLA-OS
圖 1 VLA-OS 整體概覽
一、疑云密布:VLA 模型在進行任務規劃時到底該怎么做?
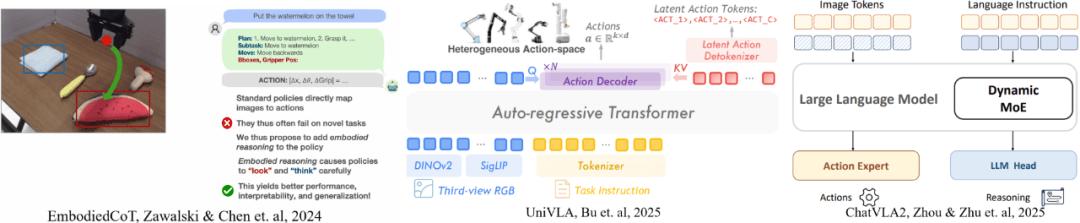
VLA 模型(Vision-Language-Action Model)近年來展現出令人印象深刻的、解決復雜任務的操作能力 。 端到端的 VLA 模型僅僅使用數據驅動的模仿學習就可以實現過去需要進行復雜系統設計才能完成的任務 , 直接從圖像和語言的原始輸入映射到機器人的動作空間 , 展現出了強大的 scale up 的潛力 。 圖 2 展示了一些端到端的 VLA 代表性工作 。
圖 2 一些端到端的 VLA 模型(ActionOnly-VLA)
然而 , 目前可用于訓練 VLA 的數據集相比起 LLM 和 VLM 來說還非常少 。 因此研究人員最近開始嘗試在 VLA 中添加任務推理模塊來幫助 VLA 使用更少的數據完成復雜的任務 。 主流的方式包括兩類:
使用一個端到端的模型來同時進行任務規劃和策略學習(Integrated-VLA) 。這些模型通常會在模仿學習的損失函數上增加一個用于任務規劃的損失函數 , 抑或是增加一些額外的任務規劃訓練表征 , 來使得基座大模型同時被任務規劃和策略學習的任務進行訓練 。 例如 EmbodiedCoT 添加了使用自然語言的任務分解的學習過程 , 而 UniVLA 采用了目標圖像推理特征的隱式提取 。 圖 3 展示了一些代表性工作:
圖 3 Integrated-VLA 的一些工作
使用分層的范式(Hierarchical-VLA) ,即一個上層模型負責任務規劃 , 另一個下層模型負責策略學習 , 二者之間沒有梯度回傳 。 例如 , Hi-Robot 使用一個 VLM 輸出任務分解后的簡單語言規劃指令 , 然后用一個 VLA 接收分解好的語言指令進行動作 。 圖 4 展示了一些代表性工作:
圖 4 Hierarchical-VLA 的一些工作
這些模型都展現出了令人印象深刻的實驗結果 。 然而 , 目前的這些工作互相之間區別很大 , 而且這些區別還是多維度的:從采用的 VLM backbone、訓練數據集、網絡架構、訓練方法 , 到針對任務規劃所采用的范式、表征 , 都千差萬別 , 導致我們很難判斷真正的性能提升來源 , 使得研究者陷入「盲人摸象」的困境 。
對于研究者來說 , 分析清楚這些 VLA 范式中到底是哪些部分在起作用、哪些部分還需要被提升是很關鍵的 。 只有清楚地知道這些 , 才能看清楚未來的發展方向和前進道路 。
圖 5 VLA 做任務規劃的變量太多 , 難以進行深入分析
鑒于這個問題 , 我們計劃采取控制變量的實驗方法 , 專注于任務規劃的「范式」和「表征」兩大方面 , 然后統一其他因素 , 并直指五大核心研究問題:
a. 我們該選用哪種表征來進行任務規劃?
b. 我們該選用哪種任務規劃范式?
c. 任務規劃和策略學習 , 哪部分現在還不夠好?
d. 對于采用任務規劃的 VLA 模型來說 , 是否還具備 scaling law?
e. 在 VLA 中采用任務規劃后 , 對性能、泛化性、持續學習能力有什么樣的提升?
圖 6 VLA-OS 將對其他因素進行統一 , 使用控制變量的方法研究范式和表征
二、抽絲剝繭:VLA-OS —— 機器人模型的「樂高式」實驗平臺
為了實現控制變量的實驗目標 , 我們需要針對 VLM backbone、數據集、模型架構、訓練方法進行統一 。
首先 , 我們構建了架構統一、參數遞增的 VLM 模型家族 。 市面上目前并沒有尺寸范圍在 0.5B ~ 7B 之間的 VLM 。 因此 , 我們需要自己進行構建 。 我們選取了預訓練好的 Qwen 2.5 LLM 的 0.5B/1.5B/3B/7B 四個模型作為 LLM 基座 , 然后為其配上使用 DINO+SigLIP 的混合視覺編碼器 , 以及一個映射頭 。 然后 , 我們使用 LlaVa v1.5 instruct 數據集 , 對整個 VLM 的所有參數進行了預訓練 , 將 LLM 變成 VLM , 用于給后續實驗使用 。
圖 7 VLA-OS 可組合模塊家族
然后 , 我們針對三個 VLA 的任務規劃范式 , 設計了可組合的 VLA-OS 模型家族 , 首次實現三大范式的公平對比 。 我們設計了統一的動作頭(action head)和推理頭(planning head) , 使用統一的 KV Cache 提取方法來將 VLM 中的信息輸入給各個頭 。 如圖 7 所示 。
其中動作頭是一個與 LLM 骨干網絡具有相同層數的標準 Transformer , 在每一層中使用分塊因果注意力(Block-Wise Causal Attention)從 LLM 骨干網絡的鍵值(KV)中提取輸入信息 。 規劃頭中 , 語言規劃頭是一個與 LLM 骨干網絡具有相同層數的標準 Transformer , 視覺規劃頭是一個使用下文定義的坐標編碼詞表的 transformer , 而目標圖像規劃頭是一個采用類似于 VAR 架構的自回歸圖像生成器 , 也是一個與 LLM 骨干網絡具有相同層數的標準 Transformer 。 值得注意的是 , 我們的代碼結構兼容 HuggingFace 上的 LLM , 而不是某一種特定的 LLM backbone 。
針對三種 VLA 范式(ActionOnly-VLA、Integrated-VLA、Hierarchical-VLA) , 我們組合使用 VLA-OS 的標準模塊 , 構建了對應的 VLA-OS 模型實現 , 如圖所示:
圖 8 VLA-OS 研究的三種 VLA 范式和對應的網絡實現
接著 , 為了構建能夠對任務規劃進行研究的統一、廣泛、多樣的訓練數據集 , 我們整理和收集了六類數據集 , 并對它們做了統一的多模態任務規劃表征標注 。 它們包括:
LIBERO:一個桌面級 2D 視覺機器人仿真操作任務集合; The COLOSSEUM:一個桌面級的 3D 視覺機器人仿真操作任務集合; 真實世界的可形變物體操作任務集合; DexArt:一個靈巧手的仿真操作任務集合; FurnitureBench:一個精細的、長時序任務的機器人仿真平臺操作任務集合; PerAct2:一個桌面級 3D 視覺雙臂機器人仿真操作任務集合 。我們的數據集總共包括大約 10000 條軌跡 , 在視覺模態(2D 和 3D)、操作環境(仿真、現實)、執行器種類(夾爪、靈巧手)、物體種類(固體、鉸鏈物體、可形變物體)、機械臂數量(單臂、雙臂)等維度上都具有廣泛的覆蓋性 。
圖 9 VLA-OS 六大數據集
在此基礎上 , 我們設計了三種任務規劃表征 , 并針對所有數據進行了統一標注:
語言規劃 。 語言規劃數據在每個時間步包含 8 個不同的鍵 , 包括 Task、Plan、Subtask、Subtask Reason、Move、Move Reason、Gripper Position 和 Object Bounding Boxes 。 這些鍵包含對場景的理解和任務的分解 。 例如 , 對于「open the top drawer of the cabinet」這個任務來說 , 語言規劃的標注為: TASK: Open the top drawer of the cabinet. PLAN: 1. Approach the cabinet. 2. Locate the top drawer. 3. Locate and grasp the drawer handle. 4. Open the drawer. 5. Stop. VISIBLE OBJECTS: akita black bowl [100 129 133 155
plate [17 131 56 158
wooden cabinet [164 75 224 175
SUBTASK REASONING: The top drawer has been located; the robot now needs to position itself to grasp the handle. SUBTASK: Locate and grasp the drawer handle. MOVE REASONING: Moving left aligns the robot's end effector with the drawer handle. MOVE: move left GRIPPER POSITION: [167 102 166 102 165 102 164 102 162 102 161 102 160 102 158 102 156 102 154 102 153 102 151 102 149 102 147 102 145 102 143 102
視覺規劃 。 視覺規劃包含了三種扎根在圖像上的空間語義信息 。 我們將整個圖像分為 32x32 個網格 , 采用位置標記loc_i來表示從左上到右下的第 i 個網格 。 我們使用這種位置標記對所有物體的邊界框、末端執行器位置流和目標物體可供性這三種表征作為視覺規劃表示 。 例如 , 對于「Put the cream cheese box and the butter in the basket」 , 視覺規劃表示的結果為: VISUAL OBJECT BBOXES: alphabet soup [loc_500loc_632
cream cheese [loc_353loc_452
tomato sauce [loc_461loc_624
ketchup [loc_341loc_503
orange juice [loc_538loc_767
milk [loc_563loc_791
butter [loc_684loc_783
basket [loc_448loc_775
. VISUAL EE FLOW:loc_387loc_387loc_387loc_419loc_419loc_419loc_419loc_419loc_419loc_419loc_419loc_451loc_451loc_451loc_451loc_451. VISUAL AFFORDANCE:loc_354loc_355loc_356loc_386loc_387loc_388loc_418loc_419loc_420 目標圖像規劃 。 目標圖像規劃直接使用第 K 個未來步驟的圖像作為目標圖像 。
圖 10 VLA-OS 的三種規劃表征
三、水落石出:視覺表征與分層范式崛起
針對規劃表征和 VLA 范式 , 我們通過 6 大測試數據集、超百次實驗 , 得出 14 條有價值的發現 。 這些發現展示出了視覺規劃表征和目標圖像表征相比起語言表征的優勢 , 以及分層 VLA 范式相比起其他范式的未來發展潛力 。
發現 1:VLA 模型結構和訓練算法仍然很影響性能 , VLA 的 scale up 時刻還未到來 。
我們首先針對 VLA-OS 模型進行了性能測試 。 在 LIBERO benchmark 上 , 我們對比了現有的常見 VLA 模型 , 涵蓋各種尺寸、是否預訓練、是否做任務規劃等等 。 我們對所有的模型都在相應的 LIBERO 數據集上進行了訓練 , 結果如下圖所示:
圖 11 VLA-OS 和其他模型的性能對比
我們可以看到 , VLA-OS-A 的性能優于 train from scratch 的 Diffusion Policy(提升 13.2%) , 預訓練+微調后的 OpenVLA 模型(提升 9.1%)、CoT-VLA(提升 4.5%)以及 DiT Policy(提升 3.2%) , 并與預訓練+微調后的 π?-FAST(提升 0.1%)表現相當 。
盡管本模型尚不及當前最先進(SOTA)的一些方法 , 但上述結果已充分表明我們模型的設計具有良好的性能和競爭力 。 需特別指出的是 , VLA-OS-A 是在無預訓練的條件下從頭開始訓練的 , 并僅使用了參數規模為 0.5B 的語言模型作為骨干網絡 。
發現 2:對于 Integrated-VLA 來說 , 隱式任務規劃比顯式任務規劃更好 。
我們在 LIBERO-LONG 基準測試集上開展了語言規劃、視覺規劃、圖像前瞻規劃及其組合方式的實驗 。 該基準包含 10 個長時間跨度任務 , 每個任務提供 50 條示教軌跡 , 旨在評估 Integrated-VLA 模型中隱式規劃與顯式規劃變體的性能表現 。 實驗結果如下所示 。
圖 12 隱式和顯式的 Integrated-VLA 性能對比
隱式規劃范式通過引入多種輔助任務規劃目標作為訓練過程中的附加損失項 , 從而在不改變推理階段行為的前提下 , 相較于 ActionOnly-VLA 實現性能提升 。
這表明 , 將任務規劃作為輔助損失引入訓練可以有效提高模型性能;然而 , 顯式規劃范式性能卻發生下降 , 這可能是因為:1)在推理階段 , 顯式規劃必須先完成整個規劃過程 , 隨后才能生成動作輸出 , 可能帶來規劃誤差累積問題 。
通常 , 規劃 token 的長度遠遠超過動作 token(約為 2000 對 8);2)顯式規劃的策略損失梯度會同時回傳給 VLM 和任務規劃頭 , 可能導致梯度沖突 。
發現 3:相較于語言規劃表示 , 基于視覺的規劃表示(視覺規劃和目標圖像規劃)在性能上表現更優 , 且具有更快的推理速度與更低的訓練成本 。
我們在 LIBERO-LONG 基準測試集上開展了語言規劃、視覺規劃、圖像前瞻規劃及其多種組合方式的實驗 。 該基準包含 10 個長時間跨度任務 , 每個任務提供 50 條示范 , 旨在系統評估不同類型規劃表示的性能表現 。 實驗結果如下所示 。
圖 13 不同規劃表征的性能對比
發現 4:在同時采用多種規劃表示的情況下 , Hierarchical-VLA 相較于 Integrated-VLA 范式表現出更優的性能 。
我們在 LIBERO-LONG 基準測試集上展示了 Integrated-VLA 與 Hierarchical-VLA 兩種范式在不同規劃表示下的性能對比結果 。
圖 14 同時使用多種規劃表征的性能對比
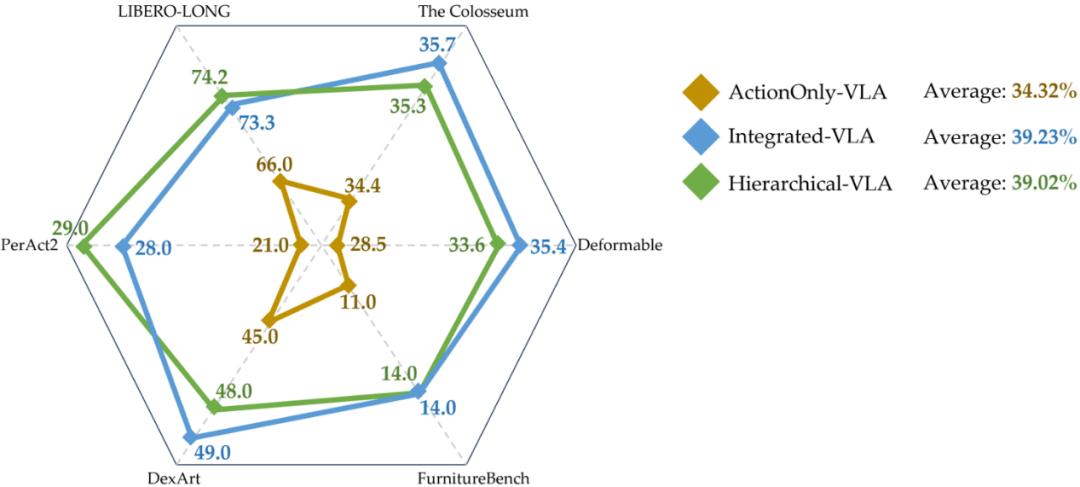
發現 5:Integrated-VLA 與 Hierarchical-VLA 在二維、三維、仿真及真實環境等多種任務中均顯著優于 ActionOnly-VLA , 且兩者整體性能相近 。
我們在六個基準測試集上展示了所有 VLA 范式的性能表現及其平均成功率 。 可以看出 , Integrated-VLA 與 Hierarchical-VLA 在所有基準上均優于 ActionOnly-VLA , 且兩者之間的性能差距較小 , 表現整體接近 。
圖 15 多種 benchmark 上的各種 VLA 范式性能對比
發現 6:Integrated-VLA 與 Hierarchical-VLA 在任務規劃預訓練中均表現出相似的收益 , 任務成功率均有所提升 , 增幅相近 。
發現 7:Hierarchical-VLA 展現出最強的泛化能力 。
我們展示了所有 VLA 范式在 The-Colosseum (ALL-Perturbation) 基準測試集上的泛化性能 , 以及 Integrated-VLA 與 Hierarchical-VLA 在 LIBERO-90 上進行任務規劃預訓練后的性能提升情況 , 并在 LIBERO-LONG 上進行了測試評估 。
結果表明 , Hierarchical-VLA 實現了最優的泛化性能 , 而 Integrated-VLA 與 Hierarchical-VLA 均能從任務規劃預訓練中獲得相似的性能提升 。
圖 16 泛化性能對比
發現 8:Hierarchical-VLA 在任務規劃方面優于 Integrated-VLA 。
為了明確任務失敗是源于規劃模塊還是策略學習模塊 , 我們對 Integrated-VLA(僅評估其任務規劃部分)與 Hierarchical-VLA 在 LIBERO-LONG 基準上進行分析性評估 , 覆蓋三種不同的規劃表示形式 。
具體地 , 我們手動將每個長時序任務劃分為若干子任務 , 并在評估過程中強制將環境重置至各子任務的初始狀態 。 我們分別計算每個子任務起點對應的規劃輸出的平均正確率(0 或 1)以及動作頭的執行成功率(0 或 1) , 從而獲得每個任務軌跡的任務分解得分(Task Decomposition Score , DCS)與策略執行得分(Policy Following Score , PFS) 。 需要指出的是 , 對于 Hierarchical-VLA , 我們在測試 PFS 時提供了任務規劃的真實結果(ground truth) 。
圖 17 純規劃性能對比
我們可以觀察到 , 在不同的規劃表示下 , Hierarchical-VLA 在任務規劃方面始終優于 Integrated-VLA , 表現出更強的規劃能力 。
發現 9:基于視覺的規劃表示更易于底層策略的跟隨 。
如上所述 , 我們展示了 Hierarchical-VLA 在不同規劃表示下的策略執行得分(Policy Following Score PFS) , 用于衡量底層策略對規劃結果的執行能力 。 結果表明 , 基于視覺的規劃表示在策略執行過程中具有更高的可跟隨性 。
圖 18 下層策略跟隨任務規劃性能對比
我們可以觀察到 , 基于視覺的規劃表示(包括視覺規劃與圖像前瞻規劃)更易于被底層策略所跟隨 , 表現出更高的策略可執行性 。
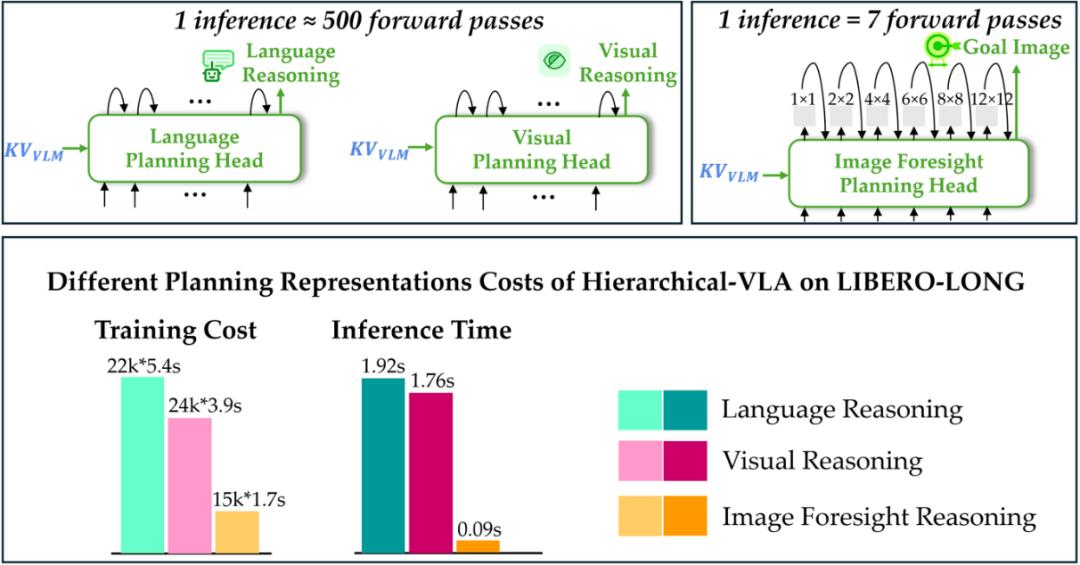
發現 10:語言規劃表示頭的自回歸特性是其訓練成本較高和推理速度較慢的主要原因 。 為進一步探究不同規劃表示在訓練成本與推理速度上的差異 , 我們在下圖中展示了 Hierarchical-VLA 中不同規劃頭的前向傳播過程 。
圖 19 不同規劃頭之間的工作模式對比
由于語言規劃頭與視覺規劃頭具備自回歸特性 , 它們在生成規劃 token 時需進行數百次前向傳播 , 導致訓練成本較高、推理速度較慢;而圖像前瞻規劃頭(本工作中采用類似 VAR 的生成器)僅需前向傳播 7 次即可生成完整的規劃 token , 推理開銷大約是語言與視覺規劃頭的 1/100 , 顯著更高效 。
發現 11:所有 VLA 范式的性能隨著標注動作的示范數據量增加而提升 , 具備良好的數據可擴展性 。
為評估數據可擴展性 , 我們在 LIBERO-LONG 數據集上進行實驗 , 該數據集包含 10 個任務 , 共計 500 條示范 。 我們分別使用 10%、40%、70% 和 100% 的數據量對三種 VLA 范式(模型規模為 S)進行訓練 , 并評估其性能隨數據規模變化的趨勢 。
【VLA-OS:NUS邵林團隊探究機器人VLA做任務推理的秘密】
圖 20 VLA 的數據可擴展性
我們可以看到 , 所有 VLA 范式均具備良好的數據可擴展性 , 隨著標注動作示范數據量的增加 , 其性能穩步提升 。
發現 12:在約 5000 條示范數據的「從零訓練」任務中 , LLM 骨干網絡應限制在 0.5B 參數規模以內 , 或總模型參數規模不超過 1B , 才能獲得更優的性能表現 。
為評估模型可擴展性 , 我們在 LIBERO-90 數據集上進行了實驗 , 該數據集包含 90 個任務 , 共計 4500 條示范 。 我們使用全部訓練數據 , 選取了不同參數規模(0.5B、1.5B、3B 和 7B)的 Qwen-2.5 語言模型作為骨干網絡進行對比實驗 , 以探索模型規模對性能的影響 。
圖 21 VLA 的模型可擴展性
我們可以觀察到 , 隨著模型規模的增大 , 各種 VLA 范式的性能并未隨之提升 , 反而在模型規模超過 3B 時出現下降的趨勢 。
發現 13:相比不含任務規劃的范式(ActionOnly-VLA) , 包含任務規劃的 VLA 范式(Integrated-VLA 與 Hierarchical-VLA)在前向遷移能力上更強 , 但遺忘速度也更快 。
我們在 LIBERO-LONG 的 10 個任務上 , 按照任務順序對三種 VLA 范式進行持續學習能力評估 。 實驗中采用 Sequential Finetuning(SEQL)作為終身學習算法 , 評估指標采用 LIBERO 提供的原始度量方式 , 包括前向遷移(Forward Transfer , FWT)和負向后向遷移(Negative Backward Transfer , NBT) 。
圖 22 不同 VLA 范式的持續學習能力
發現 14:相較于基于語言的規劃表示 , 基于視覺的規劃表示在持續學習中展現出更優的前向遷移能力 , 且遺忘速度更慢 。
我們在 LIBERO-LONG 的 10 個任務上 , 依次測試三種規劃表示在持續學習場景下的表現 。 實驗統一采用 Sequential Finetuning(SEQL)作為終身學習算法 , 并使用 LIBERO 提供的原始評估指標 , 包括前向遷移(Forward Transfer , FWT)和負向后向遷移(Negative Backward Transfer , NBT) 。
圖 23 不同規劃表征的持續學習能力
四、月映萬川:機器人 VLA 模型的「第一性原理」
設計指南(抄作業時間?。 ?
a) 首選視覺表征規劃和目標圖像規劃 , 語言規劃僅作為輔助;
b) 資源充足選分層 VLA(Hierarchical-VLA) , 資源有限選隱式聯合(Integrated-VLA) 。
c) 對于小于五千條示教軌跡的下游任務來說 , 模型規模控制在 1B 參數內完全夠用 。
破解長期謎題
a) 目前 VLA 的結構和算法設計仍然很重要 , 還沒有到無腦 scale up 的時刻 。
b) 策略學習和任務規劃目前來說都還需要提升 。
c) 任務規劃預訓練是有效的 。d) 持續學習的代價:規劃模型前向遷移能力更強 , 但遺忘速度更快 。
未來四大方向
視覺為何優于語言?→ 探索空間表征的神經機制理論上來說 , 三種規劃表征針對于目標操作任務所提供的信息均是完備的 , 那么為什么會有如此大的性能偏差呢? 如何避免規劃與動作的梯度沖突?→ 設計解耦訓練機制無論是在隱式 Integrated-VLA 和顯式 Integrated-VLA 的比較 , 還是在分層 VLA 和 Integrated-VLA 的泛化比較中 , 都是「損失函數解耦」的一方獲勝 , 也即任務規劃的損失梯度和策略動作的損失梯度耦合地越少 , 最終效果越好 。 超越 KV 提取 → 開發更高效的 VLM 信息蒸餾架構VLA-OS 目前采用的是類似于的模型結構設計 , 也就是提取每一層 LLM 的 KV 來給動作頭和規劃頭 。 但是 , 這使得動作頭和規劃頭的設計受限(例如 , 它們都必須和 LLM 有同樣多的層數的 Transformer) 。 是否還有更為高效、限制更少的設計? 構建萬億級規劃數據集 → 推動「規劃大模型」誕生VLA-OS 的實驗確認了無論使用哪種范式 , 增加任務規劃都會對模型性能有提升 , 而且對規劃頭進行預訓練還會進一步提升性能 。 因此 , 如何構建足夠量的機器人操作任務規劃數據集將是很有前景的方向 。
推薦閱讀












- 離散擴散語言模型如何演化?NUS綜述解構技術圖譜與應用前沿
- Manus跑路!禁中國IP訪問,虛假AI神話撐不住了?
- Manus“跑路”風波背后,AI Agent的商業化困局
- 從10萬邀請碼到裁員66%:Manus潰敗揭示通用AI Agent的狂歡與泡沫
- Manus“刪博、裁員、跑路新加坡”后,創始人首次復盤經驗教訓
- 剛剛,OpenAI 發布 ChatGPT 版 Manus!奧特曼:感受 AGI 時刻
- 剛剛,OpenAI 發布了自己的 Agent模式,Manus Style
- Manus搬去新加坡:這不只是“搬家”,更是“下棋”!
- Manus“出走”中國,為哪般?
- 基于經營效率考量,Manus調整部分業務團隊