文章圖片

文章圖片
【驍龍8至尊版2曝光,但最有看點的地方并不是跑分】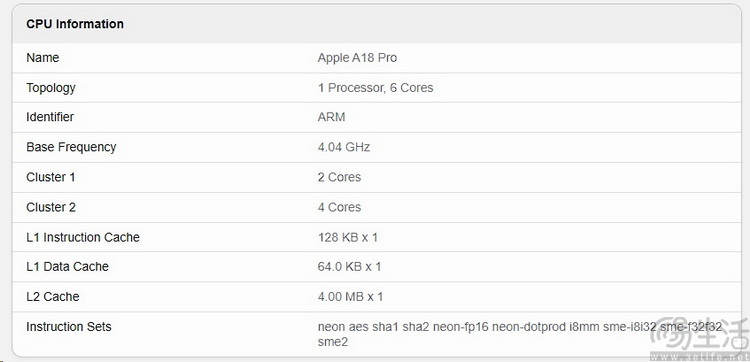
文章圖片
文章圖片

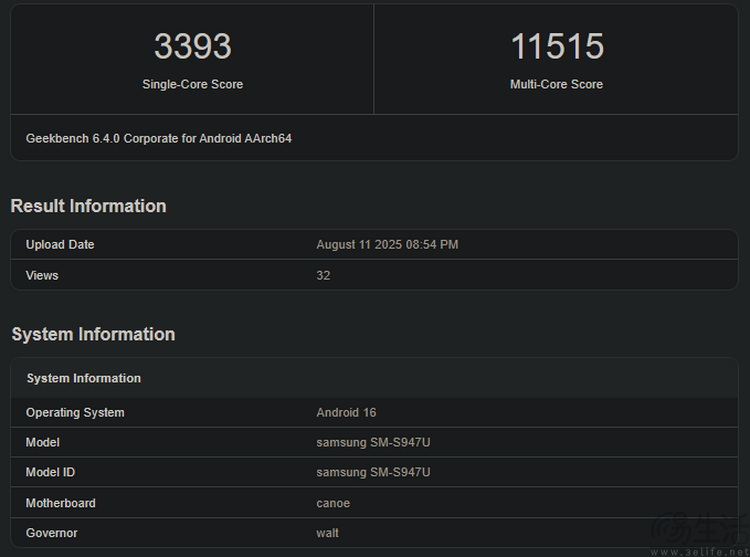
雖然距離正式發布大概還有一個多月 , 但疑似驍龍8至尊版2(SM8850)的跑分成績已經在GeekBench的服務器上出現 。
此次曝光的信息來自一臺三星“SM-S947U”手機 , 所對應的可能是Galaxy S26 Edge 。 從跑分來看 , 它在GeekBench 6.4中獲得了單核3393分、多核11515分的成績 。
如果大家有關注我們三易生活的評測內容 , 那么對于這樣的成績就可能不會感到太過驚奇 。 畢竟 , 這只比現款驍龍8至尊版的典型跑分水準(單核3000上下 , 多核10000上下) , 高出了大概10%而已 。
那么這是否意味著 , 驍龍8至尊版2的CPU性能進步幅度不大呢?并不盡然 。 一方面 , 根據更進一步的信息來看 , 這臺三星手機在整個跑分過程中 , CPU的峰值頻率只達到了4GHz , 而不是“滿血”的4.74GHz 。 這就表明它要么是遇到了過熱節流問題 , 要么干脆就不是正式版的芯片或固件 , 所以頻率就“沒上去” , 并不能代表驍龍8至尊版2的真實峰值性能 。
但這次曝光的信息中真正讓我們感到“觸動”的 , 壓根就不是驍龍8至尊版2的跑分數字本身 , 而是GeekBench除了性能測試之外 , 所“探測”的到其他東西 。
從128位到2048位 , 驍龍新旗艦多了“超算血統”
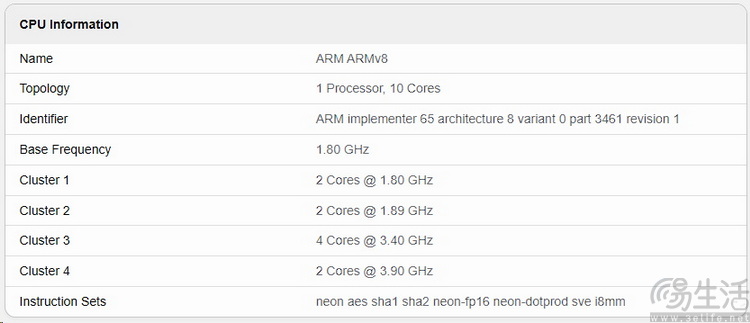
我們先將視線集中在此次曝光的跑分截屏下方區域 , 在這里GeekBench列出了它所識別到的 , 驍龍8至尊版2所支持的一系列指令集信息 。
從中可以清楚地看到 , 驍龍8至尊版2除了支持“古老的”neon指令集外 , 還支持sve和sme2這兩個新得多的指令集 。
這是什么概念呢?通過查詢公開信息可知 , neon指令集誕生于ARM v7時代 , 最早見于2005年的Cortex-A8架構 , 它最大支持128bit(位)的向量計算字長 。
而sve和sme2則要“先進”得多 , 它們分別誕生于2016年和2021年 , 最初都是由超級計算機的CPU首發 , 用于AI訓練等繁重的工作 。 所以這兩個指令集最先進的地方 , 就在于它們都可以支持到最大2048bit的超大規模字長 , 甚至超過了目前x86服務器CPU所支持的512bit AVX指令 。 在它們被“移植”到移動平臺后 , 這一關鍵技術特性也并沒有被“閹割” 。
當然 , 這并不是說高通給驍龍8至尊版2增加這兩個新的指令集 , 就一定與超算有關(雖然他們確實可能有借助Oryon架構重回超算市場的打算) 。
它們真正的意義在于 , 一方面sve和sme2作為ARM IP體系下最新的、旨在增強處理器浮點性能的指令集 , 相比于古老的neon , 能夠大幅增強現代ARM處理器在面對復雜多媒體任務的性能表現 。 說人話 , 就是能增強游戲、視頻編輯等場景的CPU效率 。 而且這兩個指令集在超算上本就是為AI而生 , 所以“移植”到移動端后 , 對增強CPU的AI計算能力自然就意義不小 。
最新版的Intel指令集文檔顯示 , AVX10.2將強制大小核全部支持512bit計算能力
另一方面 , 關注PC行業的朋友可能知道 , 目前消費級x86 CPU普遍支持256bit加速運算的AVX2指令集 。 最快到2026年 , 英特爾就會在NovaLake-S平臺加入AVX10.2指令集 , 實現全部核心的512bit加速運算功能 。
而現階段的高通Oryon架構 , 因為只支持最大128bit的neon指令集 , 就導致其在PC平臺(也就是驍龍X系列)上運行需要AVX2(256bit指令集)的程序時 , 效率大受影響 。 因此當驍龍8至尊版2加上最大能夠實現2048bit向量計算的這兩個新指令集后 , 就讓我們會對大概率也將采用新架構的下一代驍龍X PC平臺的性能、以及x86轉譯的兼容性 , 有了更高的期望 。
下一代是變強了 , 可這一代反而成為了“奇跡”
如果大家以為 , 我們僅僅就只是因為驍龍8至尊版2引入了新指令集 , 可能會帶來巨大的浮點性能改進而感到興奮 , 就未免把事情想得太過簡單了 。
首先 , 大家都知道驍龍8至尊版是基于ARM v8.7 IP的架構設計 , 這意味著它在最底層的指令集上 , 要落后于蘋果A18 Pro、聯發科天璣9400、小米玄戒O1等競爭對手 。 因為后者全都是基于ARM v9.2的架構方案 , 從“根子上”來說 , 確實要比現在的驍龍8至尊版更先進 。
蘋果A18 Pro , ARM v9.2 , 有sve、也有sme2
聯發科天璣9400 , ARM v9.2, 有sve、無sme2
小米玄戒O1 , ARM v9.2 , 有sve、無sme2
那么這是否意味著 , 上述的這幾款ARM V9.2的處理器 , 早就已經能支持sve、sme2這些先進指令集了呢?我們同樣找來了它們的GeekBench跑分信息 。 可以看到 , 其中只有A18 Pro確實早早就內置了sve和sme2 , 而聯發科和小米的ARM V9.2方案 , 就都只有sve , 并未配備sme2指令集 。
從ARM的商業模式來說 , 哪怕大家都是v9.2代次的架構 , 具體內置哪些指令集其實也是“可選”的 。 所以蘋果敢于早早地實裝先進的浮點加速指令集 , 很大程度上是因為他們有封閉生態 , 所以有信心可以“督促”開發者盡可能積極地對新架構、新指令集做適配 。
而其他家的ARM v9.2方案不選擇sme2 , 顯然也不只是為了節約成本 , 而是多少有考慮到這一先進指令集在目前的安卓生態里還過于小眾 , 即便硬件上了 , 也不一定能夠促使開發者去主動進行適配 。
但大家要知道 , 與它們同期的驍龍8至尊版 , 別說是沒有sme2(因為它是與ARM v9綁定 , 基于v8.7的Oryon自然就不可能有) , 就連sve指令集也并沒有配備 。
換句話說 , 如果高通的競爭對手真能在2024年底到2025年秋季的這段時間 , 充分地宣傳“使用ARM v9 CPU的好處” , 并敦促那些游戲和大型APP開發者使用sve指令集 , 其實他們原本是有可能在性能上充分發揮出代次優勢的 。
可結果呢?大家都知道 , 無論是在本就支持sve、sme2的跑分軟件里 , 還是在各主流游戲和生產力應用中 , 在上述這段時間里的那些、本來架構更先進的競爭對手 , 結果卻并沒有一個能夠真正在“實際性能”上超越驍龍8至尊版 。 換句話說 , 也就是高通用了一個相對落后的底層設計 , 卻做出了更好的實際表現 。
要知道從以往的經驗來看 , 這可不是一件容易的事情 。 比如早年間的英特爾Monahans(即PXA310)、英偉達Tegra2 , 甚至包括高通自己的雙核版本Scorpion(MSM8260) , 都曾因為底層的指令集、架構缺憾 , 在市場宣發和“錢景”上遭遇了設計更完善競爭對手的“強烈沖擊” 。 可到了驍龍8至尊版這里 , 卻完全顛覆了“落后(架構)必然挨打”的常識 , 硬生生地用較老的底層設計 , 打翻了一票明明更先進的競爭對手 。
優勢不只取決于硬件 , 驍龍的表現再次證明了這一點
那么 , 驍龍8至尊版到底是怎么做到這種“反殺”的呢?
從硬件設計層面來說 , 大家都知道驍龍8至尊版與同期的競品相比有兩個明顯特征 , 一是主頻要高得多 , 二是去掉了L3和SLC緩存 , 用超大的、帶寬更高的L2緩存取而代之 。 也就是說 , 高通當時的Oryon架構或許在底層指令集上“有點老” , 但他們確實用了更高的成本 , 在硬件規模上堆出了當時“公版ARM架構”實現不了的超高主頻和超大緩存 。
相比之下 , 無論是同期的蘋果和聯發科 , 還是后來的小米 , 首先在處理器的部分單元設計上確實都呈現出遜色于高通的水準 , 至少它們都沒能搞定那么恐怖的主頻 。
從部分平臺明明用了ARM v9.2指令集 , 卻“不愿意”實裝sme2這個現象來看 , 所反映出的也不只是相關廠商想要節約成本這么簡單 。 因為這實際上也體現出 , 它們對于說服開發者“拋棄”高通、專為自己做優化可能還缺乏信心 。
其實這也很好理解 。 畢竟我們不久前在《高通攢了個“游戲生態”的局 , 再次秀出技術優勢》中 , 報道過他們今年的“驍龍游戲技術賞” 。 在此次活動中 , 比起高通的代表 , 來自各大手機廠商、游戲引擎平臺、游戲開發者方面的登臺時間顯然要長得多 。 從這些合作伙伴對于驍龍8至尊版硬件性能、開發工具 , 以及性能優化套件的盛贊來看 , 高通如今所取得的成績 , 顯然不僅僅是來自于硬件設計或者分優勢那么簡單 。
而這也就很直接地提醒了目前所有的芯片廠商 , 比起單純地追求硬件規格、架構方面的領先 , 生態和軟件建設在很多時候也能對市場表現起到關鍵性的作用 。 當然 , 如果在這個基礎上 , 硬件還能做到足夠強大 , 那自然也就更加“無敵”了 。
【本文部分圖片來自網絡】
推薦閱讀













- 蘋果發布 iOS 26 beta6 版本,這些功能進行優化
- 小米終于妥協,6000mAh+驍龍8sGen4+5倍光變,國補后跌至新低價
- 驍龍8 Elite 2未滿速跑分出爐:臺積電N3P+全面提頻,新機也在打磨中
- 低于5000元?蘋果或將推出廉價版MacBook
- 小米堅決清倉,驍龍8至尊版旗艦只賣2300元,2K屏+IP68+120W
- 高通驍龍8 Elite 2跑分出爐:飆到4.74GHz 史無前例
- 實測GPT-5 Pro:別被普通版騙了!Pro才是OpenAI真正的頂級模型
- 高通驍龍 8 Elite 2 & 驍龍 8 Gen 5 來襲: 旗艦芯片的雙子星
- 廉價版“iPhone17 Air”真機曝光,太丑了
- iPhone 17系列價格曝光:只有標準版沒漲價