
文章圖片

文章圖片
文章圖片
文章圖片
GPT-5比人類醫生還會看X光片?!
最新研究顯示 , GPT-5對醫學影像的推理和理解準確率分別比人類專家高出24.23%和29.40% 。
來自埃默里大學醫學院的研究團隊把GPT-5和GPT-4o以及更小的GPT-5變體(GPT-5-mini、GPT-5-nano)進行了比較 , 分析它們在醫療領域處理多模態信息的能力 。
【GPT-5超越人類醫生,推理能力比專家高出24%,理解力強29%】通過一系列標準化測試發現GPT-5在所有測試中的表現都比其他模型好 , 尤其是在MedXpertQA的多模態測試中 , 它的推理和理解得分比GPT-4o分別提高了近30%和36% , 甚至比人類醫生還高 。
AI看病歷常見 , 可是比人類醫生還會看就不常見了 , 所以GPT-5是怎么做到的?
AI在多模態醫學領域超越人類新手醫生研究人員對GPT-5、GPT-4o以及GPT-5的mini和nano版本進行了系統測試 。
測試分為三類:純文本的USMLE考試、多模態的MedXpertQA測試還有還有放射科的VQA-RAD , 都是零樣本設置 , 不依賴數據微調 。
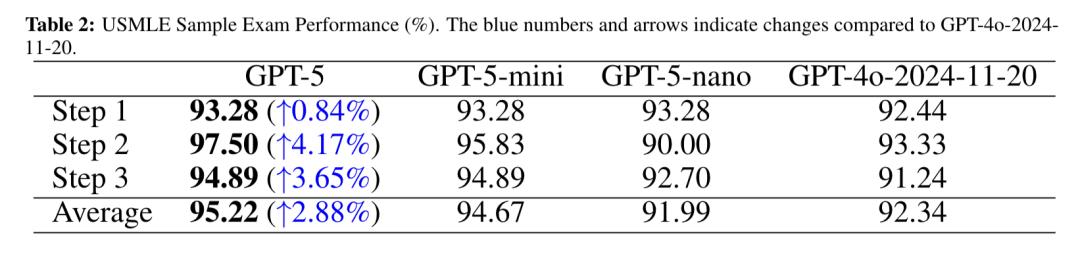
USMLE是美國醫師執照考試 , 有標準化的命題和嚴格的評分體系 , 是全球醫學教育和人才評估的重要參考基準 。
該考試分為三個步驟:Step1主要考察基礎醫學知識 , Step2聚焦臨床應用知識 , Step3側重實踐 。
在此次研究中 , GPT-5在USMLE考試中全面超越GPT-4o , 且平均得分領先于其他模型 。
MedXpertQA測試是一個用于評估模型專家級醫學知識與高級推理能力的綜合基準 , 有文本測試和多模態測試 , 共涵蓋4460道題目 , 涉及17個醫學專科和11個身體系統 , 其數據源自超20個美國醫師執照考試、歐洲放射學委員會考試等權威內容 。
其中多模態的MedXpertQA測試利用它的MM子集展開 , MM子集引入了帶有多樣化圖像及豐富臨床信息(病歷、檢查結果等)的專家級考試題 。
為增加難度 , 多模態子集的題目還擴充至5個選項 , 能更有效地評估模型在貼近真實場景下的醫學診斷推理能力 。
依據之前的數據 , GPT-5推理和理解得分比GPT-4o分別提高了近30%和36% 。
下圖詳細對比了未取得執照的人類專家與GPT-5系列模型及GPT-4o在MedXpertQA測試的文本子集(Text)和多模態子集(MM)中的表現 , 涵蓋推理、理解及平均三個維度 。
在文本測試中 , GPT-4o三項得分均低于人類專家 , GPT-5-nano同樣全面落后 , GPT-5-mini 推理和平均得分略超人類專家 , 而GPT-5表現最優 , 得分大幅領先 。
在多模態測試中 , GPT-4o推理和平均得分略低 , GPT-5-nano整體與人類專家持平 , GPT-5-mini大幅超越人類專家 , GPT-5優勢最為顯著 , 推理超人類專家24%、理解得超人類專家29% , 展現出強大的多模態醫學推理能力 。
VQA-RAD測試是醫學視覺問答測試 , 該數據集包含315張放射影像以及與之對應的3515個問答對 。 常用于評估醫學多模態大語言模型解讀復雜醫學圖像并生成準確文本描述的能力 。
在此次研究中 , GPT-5的匹配率為70.92% , 高于GPT-4o及小變體GPT-5-nano , 而其輕量化變體GPT-5-mini的表現略優 , 嚴格匹配率達到74.90% 。
考慮到VQA-RAD規模相對較小且具有放射科專項屬性 , 這種得分差異可能源于較小模型存在數據集特定的過擬合現象 。
看了這么多測試結果 , 那么GPT-5為什么能全面碾壓前輩GPT-4o呢?
GPT-5構建了端到端的多模態架構團隊認為 , GPT-5能力提升核心源于其跨模態注意力與對齊能力的增強 。
GPT-5與GPT-4o的核心差距 , 本質上是從文本主導的混合處理到原生多模態深度融合的代際跨越 。
GPT-4o在處理跨模態任務時 , 仍依賴文本轉譯+外部工具調用的間接模式:例如解析醫學影像時 , 需先通過第三方模型將圖像信息轉化為文本描述 , 再基于文本進行推理 。
這種模態轉換中介不僅增加了信息損耗(如圖像中的細微病變可能在轉譯中被忽略) , 還導致推理鏈條斷裂——模型難以直接建立影像特征-病理機制-治療方案的因果關聯 。
而GPT-5構建了端到端的多模態架構:通過共享標記化技術 , 將文本、影像、音頻等信息編碼為統一向量空間的符號 , 再借助跨模態注意力機制實現感知-推理-決策的無縫銜接 。
并且 , 團隊認為在MedXpertQA Text、USMLE Step 2這樣的推理密集型任務中 , GPT-5的進步更突出是因為思維鏈提示與GPT-5增強的內部推理能力形成了協同效應 , 使其能更準確地完成多步推理 。
不過研究人員也指出 , 盡管GPT-5在標準測試中表現優秀 , 但要說明的是 , 這些測試都是在理想環境下進行的 , 題目和數據都是標準化的 , 現實中患者的情況千奇百怪 , 還可能遇到各種突發狀況 。
所以 , GPT-5要真走進診室當助理 , 還得經過更多實戰考驗 。
這不 , KCDH_A數字健康研究中心對AI進行了放射科的終極考試 , 這是一項AI從未見過的、跨模態的檢測任務 , 涵蓋了CT、MRI和X光 , 模擬日常實踐中實際遇到的復雜真實病例 。
測試結果顯示 , 所有AI模型得分均低于實習醫生 , 而擁有執業資格的放射科醫生比AI領先更多 , 雖然GPT-5剛剛進入頂尖AI的位置 , 但也遠低于人類 。
該實驗室的研究人員表示:
雖然我對AI發展感到興奮 , 我們實驗室也在每天使用AI模型 , 但AI取代放射科醫生與現實的差距仍然很大 。
由此可見 , AI獨自看病歷之前 , 還是得先磨練磨練 。
論文地址:https://arxiv.org/abs/2508.08224
參考鏈接:
[1
https://x.com/omarsar0/status/1955252499142627788
[2
https://x.com/emollick/status/1955381296743715241
[3
https://x.com/DrDatta_AIIMS/status/1954586822849523789
推薦閱讀













- Hinton預言「AI媽媽」刷屏硅谷!李飛飛:人類或將毫無尊嚴
- 奧維云網數據顯示小米空調線上市占率超越格力,小米高管稱新時代來了
- GPT-5之后,奧特曼向左,梁文鋒向右
- GPT-5超越人類醫生!推理能力比專家高出24%,理解力強29%
- 谷歌開源Gemma 3 270M,性能超越Qwen 2.5同級模型
- Meta視覺基座DINOv3王者歸來:自監督首次全面超越弱監督,商用開源
- 為什么AI越來越讓人失望?
- 我們都錯怪GPT-5了,路由統一算力,免費用戶也能創造收益
- 奧特曼曝驚世預言:2035年GPT-8治愈癌癥,人類將為算力爆發三戰
- 新加坡大學:多AI協作解決復雜文檔超越大模型