
文章圖片
文章圖片
文章圖片

文章圖片

文章圖片
文章圖片
文章圖片

文章圖片
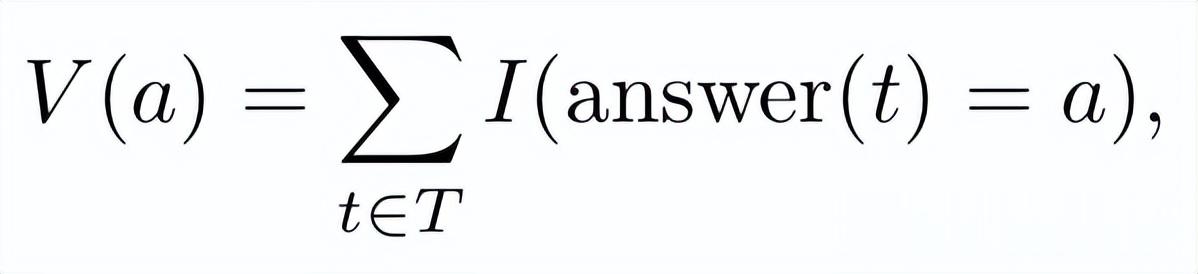
文章圖片

文章圖片

文章圖片
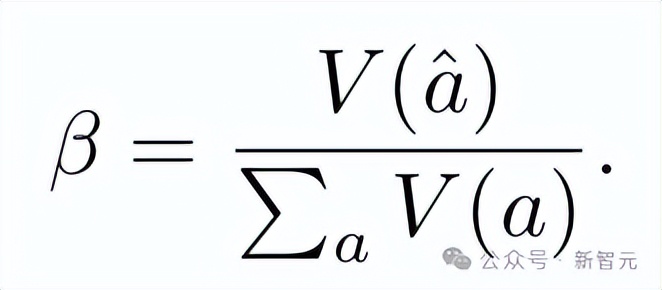
文章圖片

文章圖片
文章圖片
編輯:定慧 好困
【新智元導讀】DeepConf由Meta AI與加州大學圣地亞哥分校提出 , 核心思路是讓大模型在推理過程中實時監控置信度 , 低置信度路徑被動態淘汰 , 高置信度路徑則加權投票 , 從而兼顧準確率與效率 。 在AIME 2025上 , 它首次讓開源模型無需外部工具便實現99.9%正確率 , 同時削減85%生成token 。
如何讓模型在思考時更聰明、更高效 , 還能對答案有把握?
最近 , Meta AI與加州大學圣地亞哥分校的研究團隊給出了一個令人振奮的答案——Deep Think with Confidence(DeepConf) , 讓模型自信的深度思考 。
論文地址:https://arxiv.org/pdf/2508.15260
項目主頁:https://jiaweizzhao.github.io/deepconf
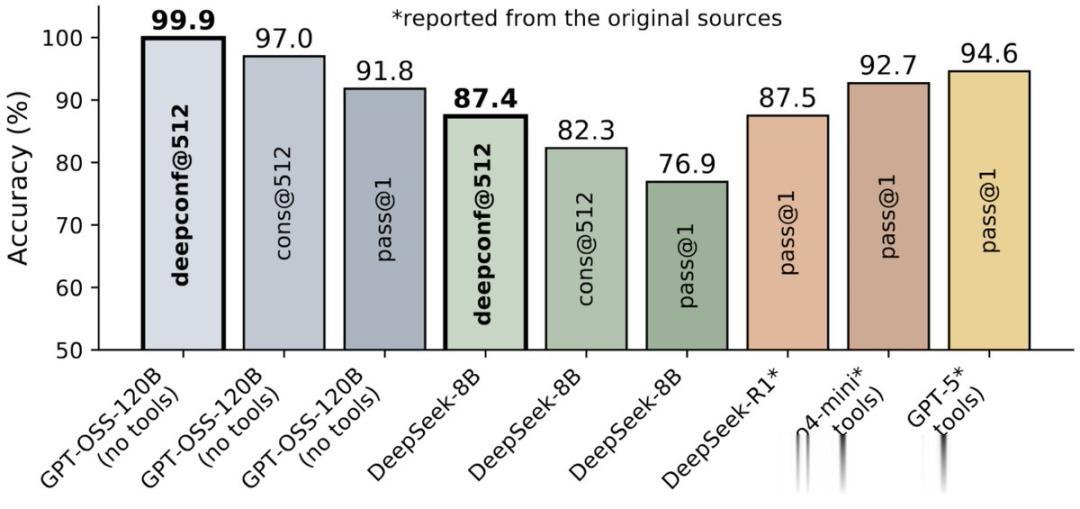
這項新方法通過并行思考與「置信度篩選」 , 不僅讓模型在國際頂尖數學競賽AIME 2025上拿下了高達99.9%的正確率 。
可以說 , 這是首次利用開源模型在AIME 2025上實現99.9%的準確率 , 并且不使用任何工具!
并且在保持高質量推理的同時 , 將生成的token數量削減了84.7% 。
DeepConf還為并行思考(parallel thinking)帶來了多項硬核優勢:
- 性能飆升:在各類模型與數據集上 , 準確率平均提升約10%
- 極致高效:生成token數量銳減高達85%
- 即插即用:兼容任何現有模型——無需額外訓練(也無需進行超參數微調?。 ?/li>
- 輕松部署:在vLLM中僅需約50行代碼即可集成
核心思想是DeepConf通過「置信度信號」篩選推理路徑 , 從而得到高質量答案 , 并在效率與準確率之間取得平衡 。
- 橫軸(token index):表示模型生成的推理步驟(隨著token逐步增加) 。
- 縱軸(confidence):表示每條推理路徑在該步驟上的置信度水平 。
- 綠色曲線:表示不同推理路徑的置信度軌跡 , 越深的綠色表示置信度越高 。
- 紅色叉叉:低于置信度閾值的推理路徑 , 被動態篩除 。
- 綠色對勾:最終被保留下來的高置信度路徑 。
- 最終表決:這些路徑在基于置信度加權的多數表決下 , 最終得出統一答案:29 。
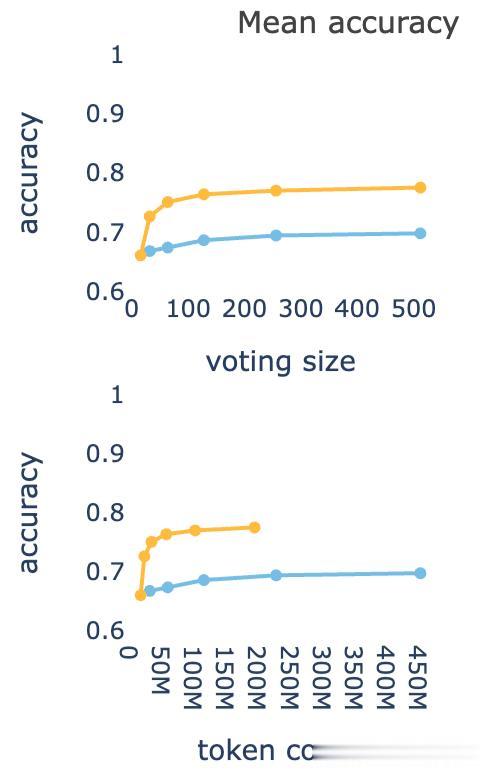
通過準確率對比曲線 , 上圖可以看出縱軸是accuracy(準確率) , 黃色曲線(DeepConf)比藍色曲線(標準方法)明顯更高 。
表明DeepConf在相同投票規模下能達到更高的準確率 。
下圖橫軸是token數量(推理所需的計算成本) , 黃色曲線在準確率保持較高的同時 , token消耗明顯更少 。
表明DeepConf大幅減少了無效token的生成 , 推理效率更優 。
DeepConf讓模型不再「胡思亂想」 , 而是高效地走在高置信度的推理軌道上 。
DeepConf支持兩種工作模式:
- 離線模式:根據置信度篩選已完成的推理路徑 , 然后根據質量對投票進行加權 。
- 在線模式:當置信度實時降至閾值以下時 , 立即停止生成 。
DeepConf的秘訣是什么?
其實 , LLM知道自己何時開始不確定的 , 只是大家一直沒有認真關注過他們的「思考過程」 。
之前的方法在完整生成之后使用置信度/熵用于測試時和強化學習(RL) 。
DeepConf的方法不同 , 不是在完成后 , 而是在生成過程中捕捉推理錯誤 。
DeepConf實時監控「局部置信度」 , 在錯誤的推理路徑消耗數千個token之前及時終止 。
只有高質量、高置信度的推理路徑才能保留下來!
DeepConf是怎樣「用置信度篩選、用置信度投票」?
這張圖展示了DeepConf在離線思考時的核心機制:
它先判斷哪些推理路徑值得信賴 , 把不靠譜的路徑提前剔除 , 再讓靠譜的路徑進行加權投票 , 從而得到一個更準確、更高效的最終答案 。
首先是每一token「有多確定」 。
【比GPT-5還準?AIME25飆到99.9%刷屏,開源模型首次!】當模型在寫推理步驟時 , 其實每個詞(token)背后都有一個「信心值」 。
如果模型覺得「這一步答案很靠譜」 , 信心值就高 。 如果它自己都拿不準 , 這個信心值就會低 。
上圖里用不同深淺的綠色和紅色標出來:綠色=更自信 , 紅色=不自信 。
其次 , 不光要看單token , 還要看整體趨勢 。
DeepConf不只看某一個詞 , 而是會滑動窗口:看看一小段話里的平均信心值 , 衡量「這段話整體是否靠譜」 。
重點看看最后幾句話的信心值 , 因為最終答案、最終結論往往決定于結尾 。
DeepConf也會記下這條推理鏈里最差的一步 , 如果中間有明顯「翻車」 , 這條路徑就不太可靠 。
這樣一來 , 每條完整的推理鏈路都會得到一個綜合的「置信度分數」 。
最后 , 是先淘汰 , 再投票 。
當模型并行生成很多條不同的推理路徑時:
- 第一步:過濾 , 把「置信度分數」排序 , 最差的10%直接丟掉 , 避免浪費 。
- 第二步:投票 , 在剩下的推理鏈里 , 不是簡單數票 , 而是按照置信度加權投票 。
最后看一下結果 , 在圖的右邊可以看到:有的路徑說「答案是109」 , 有的說「答案是103、104、98」 。
但由于支持「109」的路徑更多、而且置信度更高 , 所以最終投票選出了109作為答案 。
成績刷爆99.9%
比GPT-5還高
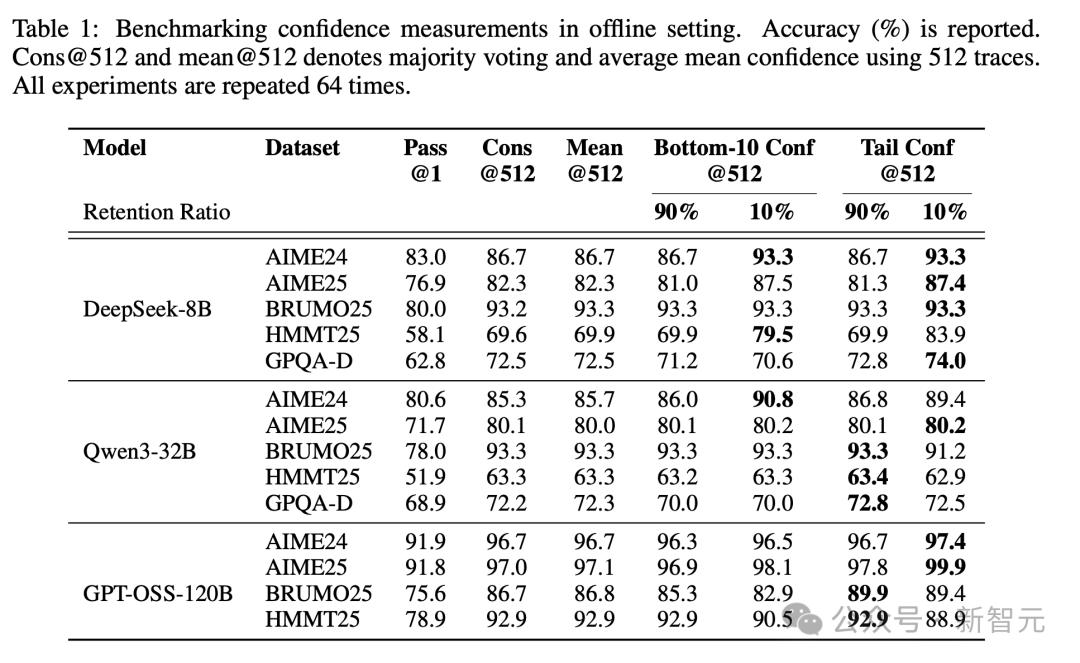
離線模式結果:在AIME 2025上達到99.9%的準確率(基線為97%)!
在5個模型×5個數據集上實現普適性增益 。
在所有設置下均取得約10%的穩定準確率提升 。
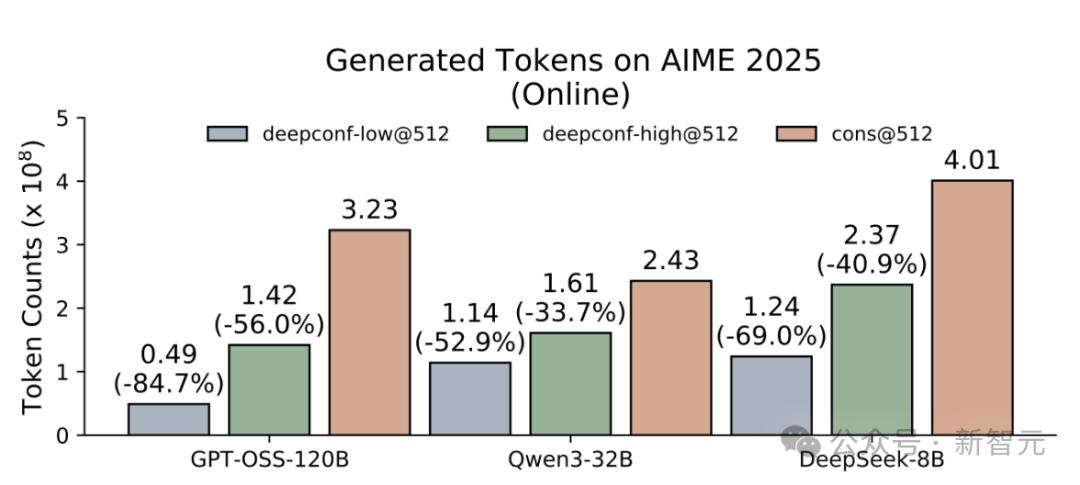
在線模式結果:在所有基準測試中節省33%-85%的token!
在AIME 2025基準測試中 , 使用GPT-OSS-120B , 在減少85%的token消耗下 , 仍達到97.9%的準確率 。
該方法適用于從8B到120B的各類開源模型——在不犧牲質量的前提下實現實時高效 。
在離線環境中對置信度度量進行基準測試 。 報告的數值為準確率(%) 。
Cons@512和mean@512分別表示使用512條推理軌跡進行的多數投票結果 , 以及平均置信度的均值 。 所有實驗均重復進行了64次 。
在在線環境中對DeepConf進行基準測試 。
在投票規模預算為512的條件下 , 報告多數投票方法與DeepConf(高/低)的方法的準確率(%)以及生成的token數量(×10?) 。
基于置信度的深度思考
研究者的思考是:到底怎么把「置信度」用得更巧妙 , 讓模型既想得更準 , 又想得更快呢?
正如前文所述 , 這里可以分成兩個使用場景:
- 離線思考:等模型把一整條推理路徑都寫完了 , 再回頭去評估每條路徑的置信度 , 把靠譜的結果聚合在一起 。 這樣做的好處是能最大化提升答案的準確性 。
- 在線思考:在模型一步步生成推理的過程中 , 就實時參考置信度 。 如果發現某條思路不靠譜 , 可以及時停掉 , 避免浪費算力 。 這樣能邊走邊篩選 , 提升效率甚至精度 。
離線思考
在離線思考模式下 , 每個問題的所有推理路徑均已生成 。
此時的核心挑戰是:如何聚合來自多條路徑的信息 , 從而更準確地確定最終答案 。
針對這一點 , 研究人員采用了標準的多數投票(majority voting)方法 。
- 多數投票(Majority Voting)
設T為所有已生成路徑的集合 , 對于任意路徑t∈T , 設answer(t)為從該路徑中提取的答案文本 。
那么 , 每個候選答案a的票數為:
- 置信度加權多數投票
對于每個候選答案a , 它的總投票權會被重定義為:
- 置信度過濾
具體來說就是 , 通過路徑的置信度分數 , 篩選出排序前η%的路徑 , 從而確保只有最可靠的路徑參與最終答案的決定 。
選擇前10%:專注于置信度最高的少數路徑 。 適用于少數路徑就能解決問題的場景 , 但風險是如果模型存在偏見 , 容易選錯答案 。
選擇前90%:納入更廣泛的路徑 。 這種方法能保持多樣性、減少模型偏見 , 在各路徑置信度相差不大時尤其穩健 。
圖3闡釋了各種置信度度量方法以及基于置信度的離線思考的工作原理 。
算法1則提供了該算法的詳細實現 。
在線思考
在線思考模式通過在生成過程中實時評估推理路徑的質量 , 來動態終止低質量的路徑 , 進而確保其在后續的置信度過濾階段大概率能被排除 。
對此 , 研究人員提出了兩種基于最低分組置信度 , 并會自適應地中止生成過程并調整推理路徑的預算的方法:DeepConf-low和DeepConf-high 。
其中 , 共包含兩大核心組件:離線預熱與自適應采樣 。
- 離線預熱(Offline Warmup)
對于每個新的提示詞 , 首先生成Ninit條推理路徑(例如 , Ninit=16) 。
停止閾值s定義為:
在所有配置下 , DeepConf-low均統一采用前η=10%的策略 , 而DeepConf-high則統一采用前η=90%的策略 。
在在線生成過程中 , 一旦某條推理路徑的置信度低于預熱階段的數據所設定的、能夠篩選出置信度排序前η%路徑的最低門檻 , 生成過程就會被終止 。
- 自適應采樣(Adaptive Sampling)
問題難度通過已生成路徑之間的一致性程度來評估 , 其量化方式為多數投票權重與總投票權重的比值:
若β<τ , 則表明模型未能就當前問題達成共識 , 推理路徑的生成將繼續 。 反之 , 則停止生成 , 并利用現有路徑確定最終答案 。
由于采用的是最低分組置信度 , 一個足夠大的預熱集便能產生對停止閾值s的精確估計 。
因此 , 任何被在線終止的路徑 , 其分組置信度必然低于s , 也就會被離線過濾器所排除 。
這樣 , 在線流程便能近似于離線的最低分組置信度策略 , 并且隨著Ninit的增加 , 其準確率會逼近離線策略的準確率 。
圖4中闡釋了在線生成的過程 。
算法2則提供了該算法的詳細實現 。
具體過程 , 我們就用上圖里的這道「勾股三元組計數」問題舉個例子 。
DeepConf要在生成推理的同時判斷:哪條思路靠譜、該繼續;哪條思路不靠譜、該盡早停 , 從而少花token、又更準 。
兩個階段:先定閾值 , 再在線篩
1. Offline Warm-up(上圖右側 , 離線預熱)
先離線跑幾條完整的推理軌跡(Trace 1~5) , 給每條算一個「整體有多靠譜」的分數 。
按分數做一次置信度過濾 , 好的軌跡在上方(綠色) , 差的在下方(紅色) 。
據此確定一個停止閾值s(圖中綠色箭頭標注) 。
簡單來說就是低于 s 的 , 通常是不值得繼續的推理 。
這一步就像「熱身+標定」 , 模型把「該不該停」的門檻先定好 。
2. Online Generation(上圖中間 , 在線生成)
正式解題時 , 同時展開多條并行思路(多行的方塊序列) 。
對每條思路 , 系統滾動地評估「這段話最近一小段的可靠度」(圖中方塊從左到右代表一步步的生成) 。
左下 & 右下的小曲線各自表示模型的「把握」程度 。
左下綠曲線表示模型對接下來的詞更「有把握」 , 示例文本是正經的數學推理(如「勾股三元組公式…」) , 這類內容通常被保留 。
右下紅曲線表示模型在猶豫或「自我懷疑」 , 示例文本是「讓我再想想、回頭檢查一下…」 , 這類猶豫/兜圈子的片段常被判為低置信度 , 從而觸發在線早停 。
先離線確定「可靠度閾值s」 , 再在線用s給并行思路「邊走邊檢查」 。
不靠譜就當場叫停 , 靠譜的繼續前進 。 這樣就能做到既快又準了 。
作者介紹
Yichao Fu
論文一作Yichao Fu是加州大學圣地亞哥分校(UC San Diego)計算機科學與工程系的博士生 , 師從張昊教授 , 也就是老朋友Hao AI Lab的負責人 。
此前 , 他在浙江大學獲得計算機科學學士學位 。
他的研究興趣主要為分布式系統、機器學習系統以及高效機器學習算法 , 近期專注于為LLM的推理過程設計并優化算法與系統 。
他參與的項目包括:Lookahead Decoding、vllm-ltr和Dynasor 。
擴展閱讀:AI話癆終結者!UCSD清華提出「思維掃描術」Dynasor-CoT , 推理巨省token
參考資料:
https://jiaweizzhao.github.io/deepconf/
https://huggingface.co/papers/2508.15260
https://x.com/jiawzhao/status/1958982524333678877
推薦閱讀













- 比肩華為!明年小米將商用玄戒O2,有望集成自研5G基帶
- GPT-5變蠢背后:抑制AI的幻覺,反而讓模型沒用了?
- 格力“勁敵”進場!華為鴻蒙空調來了,比小米更難對付!
- 焊門成功!999元起,紅米Note15系列正式發布!性價比如何?
- 萬物皆可!桌面充電站也能運行經典游戲《Doom》:效果比預期要好
- 不愧是性價比之王!紅米發布3款新機,龍晶玻璃+7000mAh+捅破天
- 2025年55-65寸電視推薦,華為智慧屏這兩款性價比高口碑好
- 科大訊飛半年報:AI辦公硬件出海同比增長超3倍 有望實現新增量
- GPT-5 Pro獨立做數學研究,OpenAI總裁:這是生命跡象
- vivo Vision體驗首發:又輕又小還實用,比蘋果頭顯強多了