文章圖片

文章圖片
英偉達規劃 2026 年 AI GPU 光通信方案 —— 硅光子與共封裝光學或成下一代 AI 數據中心標配 。
英偉達 CPO 技術實現低功耗高速互聯
隨著 AI GPU 集群規模持續擴大 , 跨網絡層的通信需求正推動光通信技術的應用 。 今年早些時候 , 英偉達透露其下一代機架級 AI 平臺將采用硅光子互連結合共封裝光學(CPO)技術 , 以更低功耗實現更高傳輸速率 。 在今年的 Hot Chips 會議上 , 英偉達進一步披露了下一代 Quantum-X 和 Spectrum-X 光子互連解決方案的細節 , 預計 2026 年落地 。
英偉達的技術路線圖與臺積電 COUPE 路線圖高度同步 , 后者分三個階段推進:第一代是適用于 OSFP 連接器的光引擎 , 支持 1.6 Tb/s 數據傳輸并降低功耗;第二代引入 CoWoS 封裝的共封裝光學 , 在主板層面實現 6.4 Tb/s 速率;第三代目標是在處理器封裝內實現 12.8 Tb/s 傳輸 , 并進一步削減功耗和延遲 。
為何選擇共封裝光學(CPO)?在大規模 AI 集群中 , 數千顆 GPU 需協同工作 , 這對處理器互連提出挑戰:傳統方案中每個機架通過短銅纜連接架頂(ToR)交換機 , 而新架構將交換機移至行列末端 , 以構建跨多機架的低延遲統一網絡 。 這一調整大幅延長了服務器與一級交換機的距離 , 當速率提升至 800 Gb/s 時 , 銅纜已無法滿足需求 , 幾乎所有服務器 - 交換機、交換機 - 交換機鏈路均需光連接 。
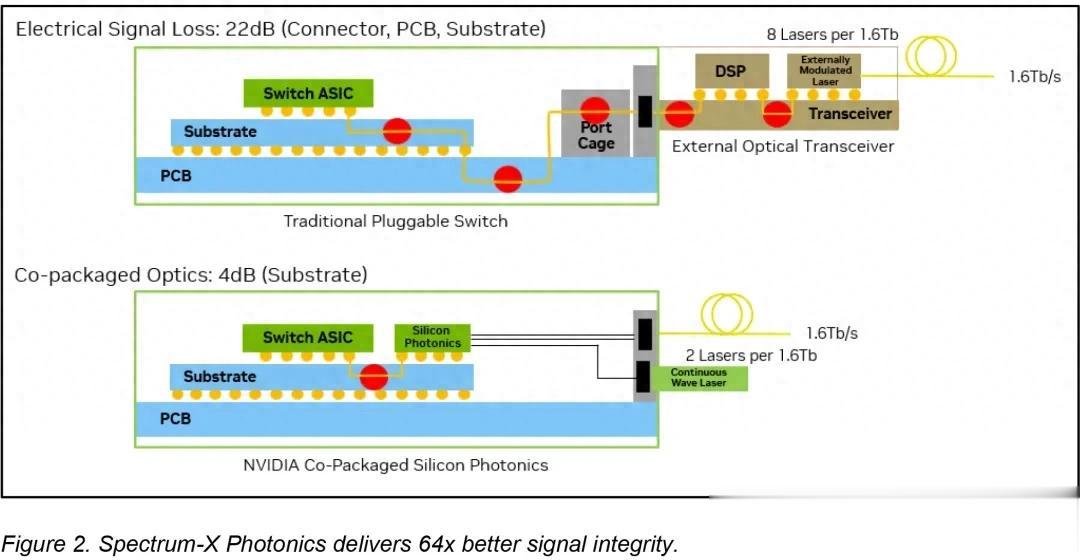
英偉達指出 , 在這種場景下使用可插拔光模塊存在明顯局限:信號需先離開 ASIC , 經電路板和連接器傳輸后再轉換為光信號 , 這會導致嚴重電損耗 ——200 Gb/s 信道上損耗可達約 22 分貝 , 需通過復雜處理補償 , 使單端口功耗升至 30W(進而需要額外散熱并可能成為故障點) 。 隨著 AI 部署規模擴大 , 這種方案幾乎難以承受 。
【能效躍升3.5倍、信號完整性提高64倍!英偉達AI GPU光通信方案曝光】
CPO 技術通過將光轉換引擎與交換機 ASIC 集成 , 避免信號經長電跡傳輸 , 而是直接耦合至光纖 , 從而將電損耗降至 4 分貝 , 單端口功耗降至 9W 。 這種架構省去大量易損元件 , 大幅簡化光互連部署 。
英偉達稱 , 借助臺積電 COUPE 平臺將光引擎直接集成到交換機芯片中 , 相比傳統可插拔收發器 , CPO 在效率、可靠性和可擴展性上實現顯著提升:能效提升 3.5 倍 , 信號完整性提高 64 倍 , 因有源器件減少使彈性提升 10 倍 , 且由于維護和組裝更簡單 , 部署速度加快約 30% 。
面向以太網與InfiniBand 的 CPO 方案英偉達將為以太網和 InfiniBand 技術同步推出基于 CPO 的光互連平臺:
Quantum-X InfiniBand 交換機:計劃 2026 年初推出 , 單交換機吞吐量達 115 Tb/s , 支持 144 個 800 Gb/s 端口 , 集成具備 14.4 TFLOPS 網絡內處理能力的 ASIC , 并支持第四代可擴展分層聚合縮減協議(SHARP)以降低集體操作延遲 , 采用液冷設計 。
Spectrum-X 光子平臺:2026 年下半年面向以太網推出 , 基于 Spectrum-6 ASIC 打造兩款設備:SN6810 提供 102.4 Tb/s 帶寬(128 個 800 Gb/s 端口) , SN6800 擴展至 409.6 Tb/s(512 個同速率端口) , 均采用液冷方案 。
英偉達設想 , 基于 CPO 的交換機將為規模與復雜度不斷提升的生成式 AI 集群提供動力 。 借助 CPO , 這類集群可省去數千個離散元件 , 實現更快安裝、更易維護和更低單連接功耗 , 使 Quantum-X InfiniBand 和 Spectrum-X 光子平臺在開機時間、首 token 響應時間和長期可靠性等指標上顯著優化 。
英偉達強調 , 共封裝光學并非可選增強功能 , 而是未來 AI 數據中心的結構性需求 。 這意味著該公司將把光互連技術作為對抗 AMD 等競爭對手機架級 AI 方案的核心優勢 —— 這也解釋了為何 AMD 近期收購了 Enosemi 。
技術演進路線值得注意的是 , 英偉達硅光子計劃的演進與臺積電 COUPE(緊湊型通用光子引擎)平臺深度綁定 。 臺積電第一代 COUPE 通過 SoIC-X 封裝技術將 65nm 電子集成電路(EIC)與光子集成電路(PIC)堆疊集成 。
臺積電 COUPE 路線圖分三階段推進:第一代面向 OSFP 連接器光引擎 , 實現 1.6 Tb/s 傳輸并降低功耗;第二代采用 CoWoS 封裝的共封裝光學 , 在主板層面支持 6.4 Tb/s;第三代目標是在處理器封裝內實現 12.8 Tb/s , 進一步降低功耗與延遲 。
推薦閱讀













- 全球首款熱力學計算芯片成功流片,能效可提升1000倍
- 功耗爭議來襲!驍龍8 Elite2與天璣9500,誰會能效不及預期?
- 我國人工智能專利數占全球60% 綜合實力整體性、系統性躍升
- 天璣9500最新爆料!GPU能效暴漲,或將開啟手游光追百幀時代
- 最高能效比!他又死磕“存算一體”2年 拿出全新端邊大模型AI芯片
- 撐起單卡到十萬卡算力!無問芯穹發布“三個盒子”,全場景提升智能效率
- 蘋果M4 Max與RTX 5090 GPU性能對比:電池模式下能效表現接近
- 蘋果A19 Pro性能浮出水面:中核IPC與能效雙優,略壓驍龍8至尊2代
- 華為Mate 80系列爆料:定制超20GB大內存,新處理器能效再提升
- 聯發科天璣9500率先采用Travis超大核:IPC性能/能效大幅提升