
文章圖片

文章圖片
文章圖片

文章圖片

文章圖片

文章圖片
【谷歌大腦之父首次坦白,茶水間閑聊引爆萬億帝國,AI自我突破觸及門檻】
文章圖片
文章圖片
AI界傳奇Jeff Dean深度訪談重磅放出!作為谷歌大腦奠基人、TensorFlow與TPU背后的關鍵推手 , 他親述了這場神經網絡革命的非凡歷程 。
「現代互聯網架構之父」Jeff Dean的最新對談流出 。
這位AI領域的傳奇 , 是Google Brain的奠基者 , 也是推動神經網絡走向規模化的關鍵人物 。
從讓神經網絡「看懂貓」的重大突破 , 到TensorFlow與TPU的誕生 , 他的故事幾乎是一部AI發展史 。
在最新一期「登月播客」(The Moonshot podcast)深度訪談中 , Jeff Dean回顧了個人成長經歷、Google Brain的早期故事 , 以及他對AI未來的思考 。
節目中 , 他揭秘了他本人所知的一些細節和趣事:
· 小時候 , Jeff Dean打印了400頁源碼自學 。
· 90年代 , 他提出「數據并行/模型并行」概念時 , 還沒這些術語 。
· Google Brain的最初靈感 , 竟然是在谷歌的微型茶水間與吳恩達的一次閑聊中誕生 。
· 「平均貓」圖像的誕生 , 被Jeff比作「在大腦里找到了觸發祖母記憶的神經元」 。
· 他把AI模型比作「蘇格拉底式伙伴」 , 能陪伴推理、辯論 , 而不是單向工具 。
· 對未來的隱喻:「一億老師 , 一個學生」 , 人類不斷教AI模型 , 所有人都能受益 。
超級工程師 , 早已看好神經網絡Jeff是工程超級英雄口中的「工程超級英雄」 , 很少有人像Jeff Dean這樣的單個工程師 , 贏得人們如此多的仰慕 。
主持人的第一個問題是:JeffDean是如何成為工程師的?
Jeff Dean認為他有一個不同尋常的童年 。 因為經常搬家 , 在12年里他換了11所學校 。
在很小的時候 , 他喜歡用樂高積木搭建東西 , 每次搬家總要帶上他的樂高套裝 。
當九歲的時候 , 他住在夏威夷 。
Jeff的父親是一名醫生 , 但他總是對計算機如何用于改善公共衛生感興趣 。 當時如果想用計算機 , 他只能去健康部門地下室的機房 , 把需求交給所謂的「主機大神」 , 然后等他們幫你實現 , 速度非常慢 。
在雜志上 , Jeff的爸爸看到一則廣告 , 買下了DIY計算機套件 。 那是一臺Intel 8080的早期機型(大概比Apple II還要早一兩年) 。
最初 , 這臺電腦就是一個閃爍燈和開關的盒子 , 后來他們給它加了鍵盤 , 可以一次輸入多個比特 。 再后來 , 他們安裝了一個BASIC解釋器 。 Jeff Dean買了一本《101個BASIC語言小游戲》的書 , 可以把程序一行一行敲進去 , 然后玩 , 還能自己修改 。
這就是他第一次接觸編程 。
后來 , Jeff一家搬到明尼蘇達州 。 全州的中學和高中都能接入同一個計算機系統 , 上面有聊天室 , 還有交互式冒險游戲 。
這就像「互聯網的前身」 , 比互聯網普及早了15~20年 。
當時 , Jeff大概13、14歲 , 他在玩兒的一款多人在線的游戲源碼開源了 。
Jeff偷偷用了一臺激光打印機 , 把400頁源代碼全都打印了出來 , 想把這款多人主機游戲移植到UCSD Pascal系統上 。
這個過程讓他學到了很多關于并發編程的知識 。
這是Jeff Dean第一次編寫出并不簡單的軟件 。
大概是91年 , 人工智能第一次抓住了Jeff Dean想象力 。
具體而言 , 是使用lisp代碼進行遺傳編程 。
而在明尼蘇達大學本科的最后一年 , Jeff Dean第一次真正接觸了人工智能 。
當時 , 他上了一門并行與分布式編程課 , 其中講到神經網絡 , 因為它們本質上非常適合并行計算 。
那是1990年 , 當時神經網絡剛好有一波熱潮 。 它們能解決一些傳統方法搞不定的小問題 。
當時「三層神經網絡」就算是「深度」了 , 而現在有上百層 。
他嘗試用并行的方法來訓練更大的神經網絡 , 把32個處理器連在一起 。 但后來發現 , 需要的算力是100萬倍 , 32個遠遠不夠 。
論文鏈接:https://drive.google.com/file/d/1I1fs4sczbCaACzA9XwxR3DiuXVtqmejL/view
雖然實驗規模有限 , 但這就是他和神經網絡的第一次深度接觸 , 讓他覺得這條路很對 。
即便到了90年代末 , 神經網絡在AI領域已經完全「過時」了 。 之后 , 很多人放棄了「神經網絡」研究 。
但Jeff Dean并沒有完全放棄 。 當時整個AI領域都轉移了關注點 , 他就去嘗試別的事情了 。
畢業后 , 他加入了Digital Equipment Corporation在Palo Alto的研究實驗室 。
數字設備公司Digital Equipment Corporation , 簡稱DEC , 商標迪吉多Digital , 是成立于1957年的一家美國電腦公司 , 發明了PDP系列迷你計算機、Alpha微處理器 , 后于1998年被康柏電腦收購
后來 , 他加入谷歌 , 多次在不同領域「從頭再來」:
搜索與信息檢索系統、大規模存儲系統(Bigtable、Spanner)、機器學習醫療應用 , 最后才進入Google Brain 。
谷歌大腦秘辛:一次茶水間閑聊在職業生涯里 , Jeff Dean最特別的一點是:一次又一次地「從零開始」 。
這種做法激勵了很多工程師 , 證明了「影響力」不等于「手下的人數」 , 而是推動事情發生的能力 。
就像把雪球推到山坡上 , 讓它滾得足夠快、足夠大 , 然后再去找下一個雪球 。 Jeff Dean喜歡這種方式 。
然后在Spanner項目逐漸穩定后 , 他開始尋找下一個挑戰 , 遇到了吳恩達 。
在谷歌的茶水間偶然碰面 , 吳恩達告訴Jeff Dean:「在語音和視覺上 , 斯坦福的學生用神經網絡得到了很有前景的結果 。 」
Jeff一聽就來了興趣 , 說:「我喜歡神經網絡 , 我們來訓練超大規模的吧 。 」
這就是Google Brain的開端 , 他們想看看是否能夠真正擴大神經網絡 , 因為使用GPU訓練神經網絡 , 已經取得良好的結果 。
Jeff Dean決定建立分布式神經網絡訓練系統 , 從而訓練非常大的網絡 。 最后 , 谷歌使用了2000臺計算機 , 16000個核心 , 然后說看看到底能訓練什么 。
漸漸地 , 越來越多的人開始參與這個項目 。
谷歌在視覺任務訓練了大型無監督模型 , 為語音訓練了大量的監督模型 , 與搜索和廣告等谷歌部門合作做了很多事情 。
最終 , 有了數百個團隊使用基于早期框架的神經網絡 。
紐約時報報道了這一成就 , 刊登了那只貓的照片 , 有點像谷歌大腦的「啊哈時刻」 。
因為他們使用的是無監督算法 。
他們把特定神經元真正興奮的東西平均起來 , 創造最有吸引力的輸入模式 。 這就是創造這只貓形象的經過 , 稱之為「平均貓」 。
在Imagenet數據集 , 谷歌微調了這個無監督模型 , 在Imagenet 20000個類別上獲得了60%的相對錯誤率降低(relative error rate reduction) 。
同時 , 他們使用監督訓練模型 , 在800臺機器上訓練五天 , 基本上降低了語音系統30%的錯誤率 。 這一改進相當于過去20年的語音研究的全部進展 。
因此 , 谷歌決定用神經網絡進行早期聲學建模 。 這也是谷歌定制機器學習硬件TPU的起源 。
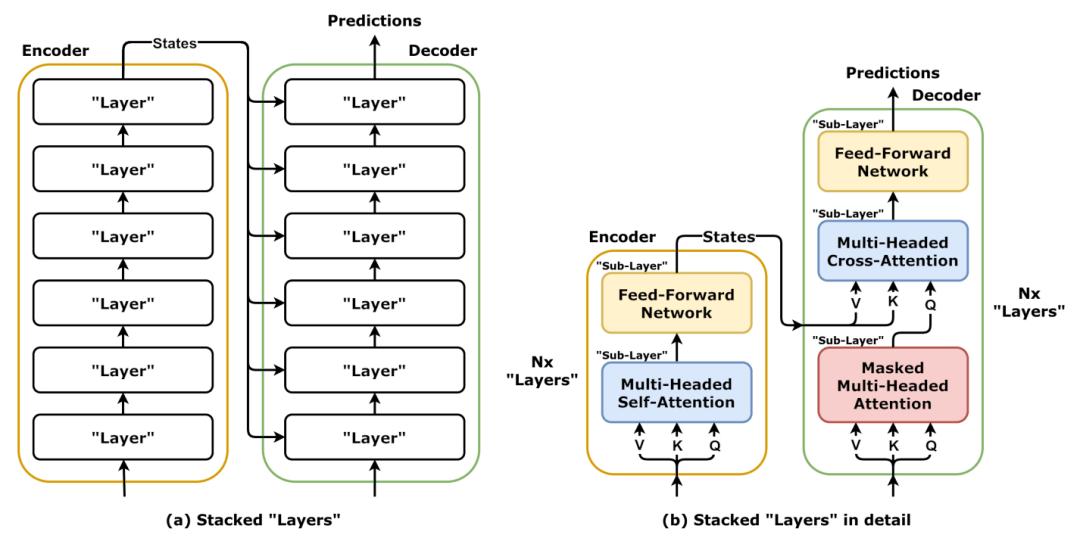
注意力機制三部曲之后不久 , 谷歌大腦團隊取得了更大的突破 , 就是注意力機制(attention) 。
Jeff Dean認為有三個突破 。
第一個是在理解語言方面 , 詞或短語的分布式表示(distributed representation) 。
這樣不像用字符「New York City」來表示紐約市 , 取而代之的是高維空間中的向量 。
紐約市傾向于出現的固有含義和上下文 , 所以可能會有一個一千維的向量來表示它 , 另一個一千維的向量來表示番茄(Tomato) 。
而實現的算法非常簡單 , 叫做word2vec(詞向量) , 基本上可以基于試圖預測附近的詞是什么來訓練這些向量 。
論文鏈接:https://arxiv.org/abs/1301.3781
接下來 , Oriol Vinyals Ilya Sutskever和Quoc Le開發了一個叫做序列到序列(sequence to sequence)的模型 , 它使用LSTM(長短期記憶網絡) 。
論文鏈接:https://arxiv.org/abs/1409.3215
LSTM有點像是一個以向量作為狀態的東西 , 然后它處理一堆詞或標記(tokens) , 每次它稍微更新它的狀態 。 所以它可以沿著一個序列掃描 , 并在一個基于向量的表示中記住它看到的所有東西 。
它是系統運行基礎上的短期記憶 。
結果證明這是建模機器翻譯的一個非常好的方法 。
最后 , 才是注意力機制 , 由Noam Shazeer等八人在Transformer中提出的注意力機制 。
這個機制的想法是 , 與其試圖在每個單詞處更新單個向量 , 不如記住所有的向量 。
所以 , 注意力機制是這篇非常開創性的論文的名字 , 他們在其中開發了這種基于transformer的注意力機制 , 這個機制在序列長度上是n平方的 , 但產生了驚人的結果 。
LLM突破觸及門檻 , 自動化閉環顛覆人類一直以來 , LLM神經網絡運作機制很難被人理解 , 成為一個無法破譯的「黑箱」 。
而如今 , 隨著參數規模越來越龐大 , 人們無法像理解代碼一樣去理解LLM 。
研究人員更像是在做「神經科學」研究:觀察數字大腦的運作方式 , 然后試著推理背后的機制 。
人類理解模型的想法 , 未來會怎么發展?
Jeff Dean對此表示 , 研究這一領域的人 , 把它稱之為「可解釋性」 。 所謂可解釋性 , 就是能不能搞清楚LLM到底在做什么 , 以及它為什么會這么做?
這確實有點像「神經科學」 , 但相較于研究人類神經元 , LLM畢竟是數字化產物 , 相對來說探測比較容易 。
很多時候 , 人們會嘗試做一些直觀的可視化 , 比如展示一個70層模型里 , 第17層在某個輸入下的情況 。
這當然有用 , 但它還是一種比較靜態的視角 。
他認為 , 可解釋性未來可能的發展一個方向——如果人類想知道LLM為何做了某種決定 , 直接問它 , 然后模型會給出回答 。
主持人表示 , 自己也不喜歡AGI術語 , 若是不提及這一概念 , 在某個時候 , 計算機會比人類取得更快的突破 。
未來 , 我們需要更多的技術突破 , 還是只需要幾年的時間和幾十倍的算力?
Jeff Dean表示 , 自己避開AGI不談的原因 , 是因為許多人對它的定義完全不同 , 并且問題的難度相差數萬億倍 。
就比如 , LLM在大多數任務上 , 要比普通人的表現更強 。
要知道 , 當前在非物理任務上 , 它們已經達到了這個水平 , 因為大多數人并不擅長 , 自己以前從未做過的隨機任務 。 在某些任務中 , LLM還未達到人類專家的水平 。
不過 , 他堅定地表示 , 「在某些特定領域 , LLM自我突破已經觸及門檻」 。
前提是 , 它能夠形成一個完全自動化閉環——自動生成想法、進行測試、獲取反饋以驗證想法的有效性 , 并且能龐大的解決方案空間中進行探索 。
Jeff Dean還特別提到 , 強化學習算法和大規模計算搜索 , 已證明在這種環境中極其有效 。
在眾多科學、工程等領域 , 自動化搜索與計算能力必將加速發展進程 。
這對于未來5年、10年 , 甚至15-20年內 , 人類能力的提升至關重要 。
未來五年規劃當問及未來五年個人規劃時 , Jeff Dean稱 , 自己會多花些時間去思考 , 打造出更加強大、更具成本效益的模型 , 最終部署后服務數十億人 。
眾所周知 , 谷歌DeepMind目前最強大的模型——Gemini 2.5 Pro , 在計算成本上非常高昂 , 他希望建造一個更優的系統 。
JeffDean透露 , 自己正在醞釀一些新的想法 , 可能會成功 , 也可能不會成功 , 但朝著某個方向努力總會有奇妙之處 。
參考資料https://www.youtube.com/watch?v=OEuh89BWRL4
本文來自微信公眾號“新智元” , 作者:KingHZ 桃子, 36氪經授權發布 。
推薦閱讀













- 谷歌Gemini一次提示能耗≈看9秒電視,專家:別太信,有誤導性
- 蘋果AI華人總監跳槽Meta,核心團隊再-1,庫克被迫求助谷歌
- 李楠點評谷歌Pixel 10:這才是真正的AI手機 友商都是噱頭
- 谷歌的一個小調整,揭開了手機快充的真面目
- 谷歌Pixel 10系列發布,搶先蘋果發3nm N3P工藝
- AI有多耗電?谷歌:一次文字回答平均耗電0.24Wh
- 享年101歲,AI之父明斯基的“反對者”走了,一生都在尋找另一種AI
- 谷歌技術報告披露大模型能耗:響應一次相當于微波爐叮一秒
- 谷歌全新小型圓形音箱曝光,或將對標HomePod Mini
- 奧特曼首曝GPT-6,親口承認GPT-5「搞砸了」,接入大腦讀心,估值或飆破5000億