
文章圖片
文章圖片
智東西
作者 | 李水青
編輯 | 云鵬
智東西9月5日消息 , 今天 , 谷歌開源一款全新的開放式嵌入模型EmbeddingGemma 。 該模型以小博大 , 擁有3.08億個參數 , 專為端側AI設計 , 支持在筆記本、手機等設備上部署檢索增強生成(RAG)、語義搜索等應用程序 。
EmbeddingGemma的一大特征是能生成隱私性良好的高質量嵌入向量 , 即使在斷網情況下也能正常運行 , 且性能直追尺寸翻倍的Qwen-Embedding-0.6B 。
Hugging Face開源頁面截圖
Hugging Face地址: https://huggingface.co/collections/google/embeddinggemma-68b9ae3a72a82f0562a80dc4
據谷歌介紹 , EmbeddingGemma具有以下幾大亮點:
1、同類最佳:在海量文本嵌入基準(MTEB)上 , 在500M以下的開放式多語言文本嵌入模型中 , EmbeddingGemma排名最高 。 EmbeddingGemma基于Gemma 3架構打造 , 已針對100多種語言進行訓練 , 并且體積小巧 , 經過量化后可在不到200MB的內存上運行 。
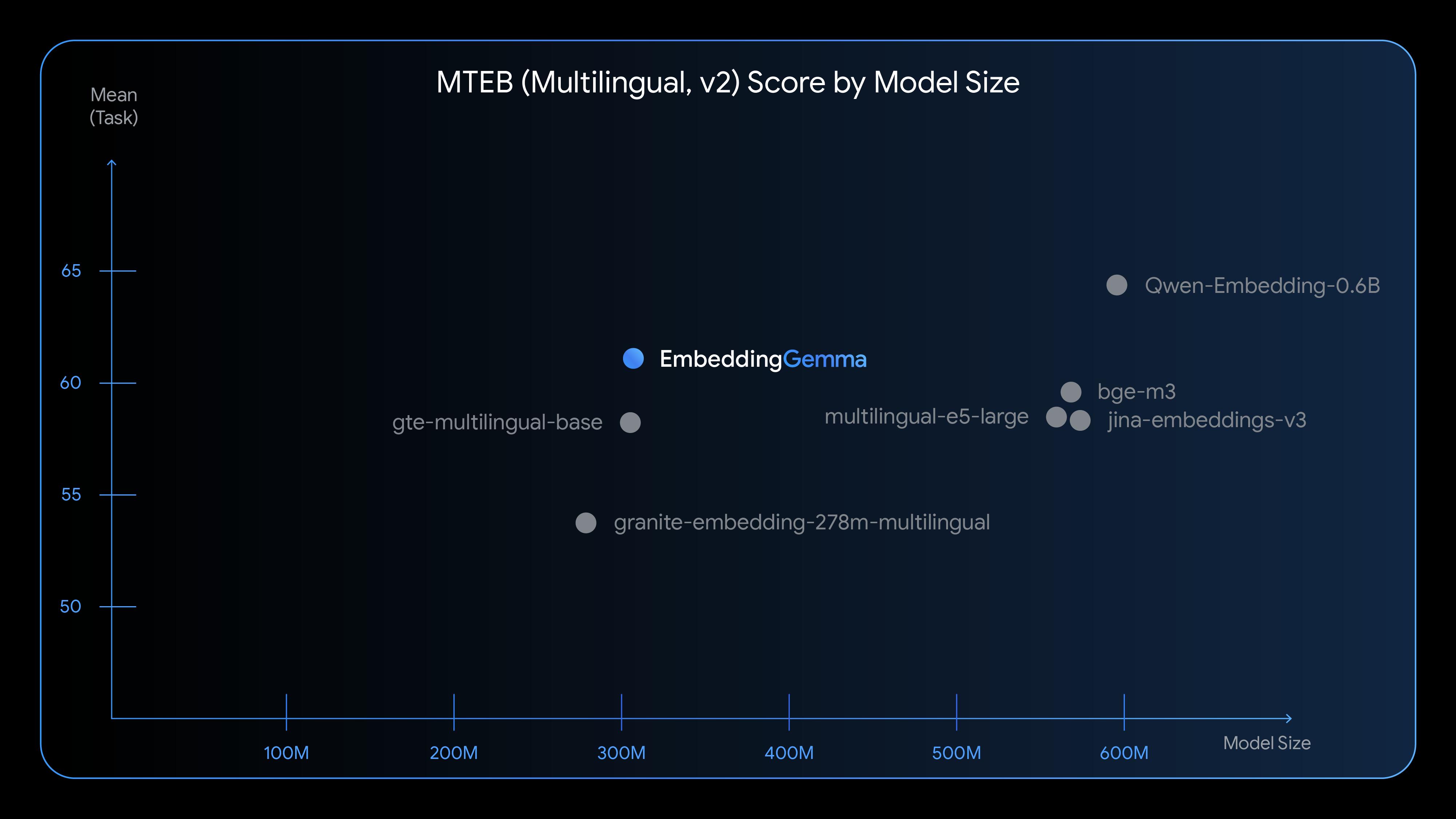
MTEB評分:EmbeddingGemma性能比肩比起尺寸大一倍的頂尖模型
2、專為靈活離線工作而設計:小巧、快速、高效 , 提供可自定義的輸出尺寸 , 以及2K令牌上下文窗口 , 可在手機、筆記本電腦、臺式機等日常設備上運行 。 它旨在與Gemma 3n配合使用 , 共同為移動RAG管道、語義搜索等解鎖新的用例 。
【0.3B!谷歌開源新模型,手機斷網也能跑,0.2GB內存就夠用】3、與流行工具集成:為了讓用戶輕松開始使用EmbeddingGemma , 它已經可以與用戶喜歡的工具一起使用 , 例如sentence-transformers、llama.cpp、MLX、Ollama、LiteRT、transformers.js、LMStudio、Weaviate、Cloudflare、LlamaIndex、LangChain等 。
一、可生成優質嵌入向量 , 端側RAG生成答案更準確EmbeddingGemma會生成嵌入向量 , 在本文語境中 , 它能將文本轉換為數值向量 , 在高維空間表征文本語義;嵌入向量質量越高 , 對語言細微差別與復雜特性的表征效果越好 。
EmbeddingGemma會生成嵌入向量
構建RAG流程存在兩個關鍵階段:一是根據用戶輸入檢索相關上下文 , 二是基于該上下文生成有依據的答案 。
為實現檢索功能 , 用戶可以先生成提示詞的嵌入向量 , 再計算該向量與系統中所有文檔嵌入向量的相似度——通過這種方式 , 能夠獲取與用戶查詢最相關的文本片段 。
隨后 , 用戶可將這些文本片段與原始查詢一同輸入生成式模型(如Gemma 3) , 從而生成符合上下文的相關答案 。 例如 , 模型能理解你需要聯系木工的電話 , 以解決地板損壞的問題 。
要讓這個RAG流程切實有效 , 初始檢索步驟的質量至關重要 。 質量不佳的嵌入向量會導致檢索到不相關的文檔 , 進而生成不準確或毫無意義的答案 。
而EmbeddingGemma的性能優勢正體現于此——它能提供高質量的(文本)表征 , 為精準、可靠的端側應用提供核心支持 。
二、以小博大 , 性能接近尺寸翻倍的Qwen-Embedding-0.6BEmbeddingGemma提供了與其規模相適應的最先進的文本理解能力 , 在多語言嵌入生成方面具有特別強大的性能 。
與其他流行嵌入模型的比較 , EmbeddingGemma在檢索、分類和聚類等任務上表現出色 。
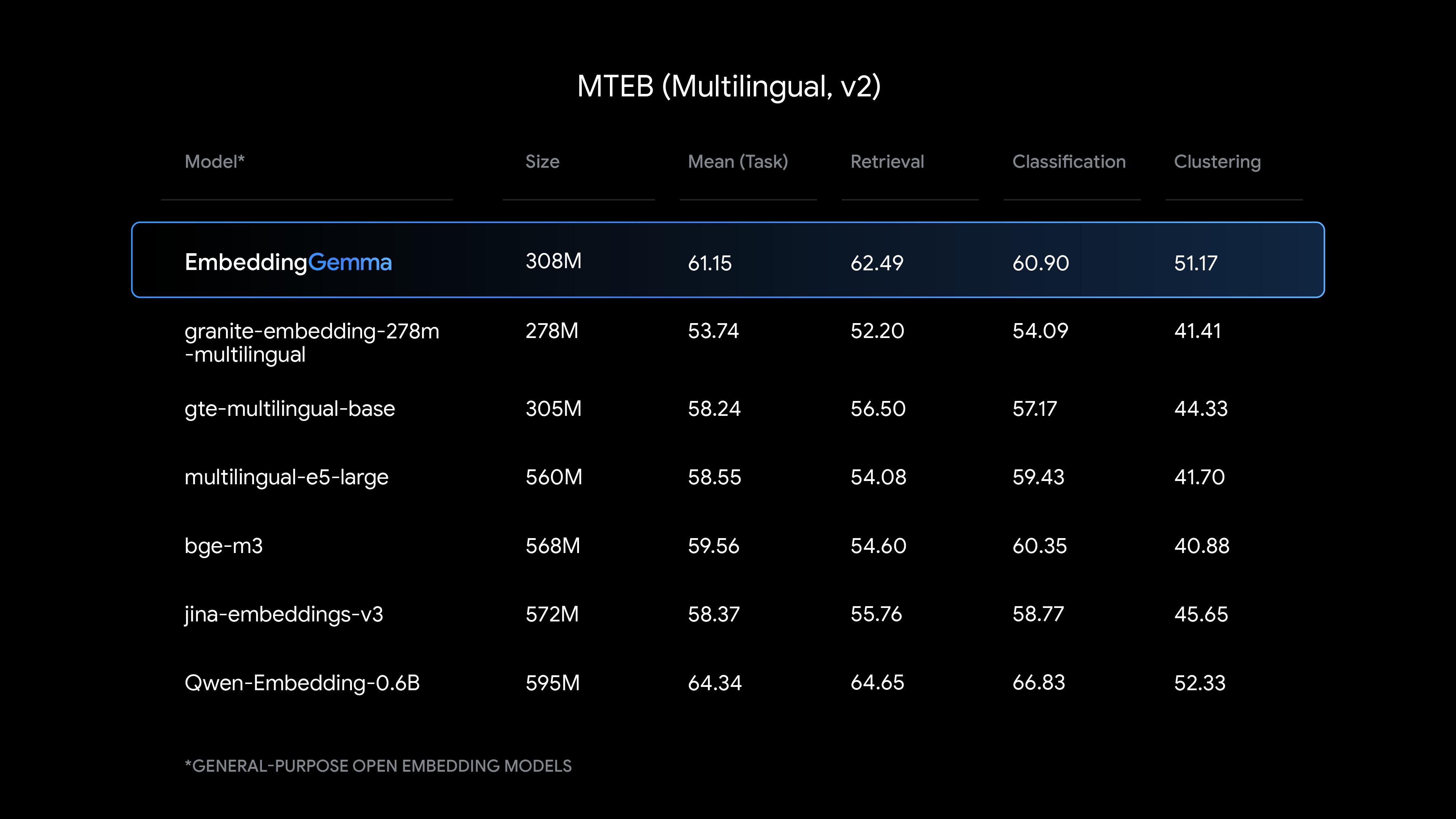
EmbeddingGemma在Mean(Task)、Retrieval、Classification、Clustering等測試中全面趕超了同等尺寸的gte-multilingual-base模型 。 其測試成績也已接近尺寸達到其兩倍的Qwen-Embedding-0.6B 。
EmbeddingGemma的測評情況
EmbeddingGemma模型擁有308M參數 , 主要由大約100M模型參數和200M嵌入參數組成 。
為了實現更高的靈活性 , EmbeddingGemma利用Matryoshka表征學習(MRL) , 在一個模型中提供多種嵌入大小 。 開發者可以使用完整的768維向量以獲得最佳質量 , 也可以將其截斷為較小的維度(128、256或512) , 以提高速度并降低存儲成本 。
谷歌在EdgeTPU上將嵌入推理時間(256個輸入token)縮短至
利用量化感知訓練(QAT) , 谷歌在保持模型質量的同時 , 顯著將RAM使用量降低至200MB以下 。
三、斷網可用 , 可在不到200MB內存上運行EmbeddingGemma支持開發者構建靈活且注重隱私的設備端應用 。 它直接在設備硬件上生成文檔嵌入 , 幫助確保敏感用戶數據的安全 。
它使用與Gemma 3n相同的分詞器進行文本處理 , 從而減少RAG應用的內存占用 。 用戶可使用EmbeddingGemma解鎖新功能 , 例如:
無需聯網即可同時搜索個人文件、文本、電子郵件和通知 。
通過RAG與Gemma 3n實現個性化、行業特定和離線支持的聊天機器人 。
將用戶查詢分類到相關的函數調用 , 以幫助移動智能體理解(用戶需求) 。
下圖為EmbeddingGemma的交互式演示 , 它將文本嵌入在三維空間中可視化 , 該模型完全在設備上運行 。
EmbeddingGemma的交互式演示(圖源:Hugging Face團隊的Joshua)
Demo體驗地址: https://huggingface.co/spaces/webml-community/semantic-galaxy)
結語:小尺寸大能力 , 加速端側智能發展EmbeddingGemma的推出標志著谷歌在小型化、多語言和端側AI上的新突破 。 它不僅在性能上接近更大規模的模型 , 還兼顧了速度、內存和隱私的平衡 。
未來 , 隨著RAG、語義搜索等應用不斷下沉至個人設備 , EmbeddingGemma或將成為推動端側智能普及的重要基石 。
推薦閱讀














- 谷歌TPU業務將獨立,估值高達9000億美元?
- TPU突圍,谷歌積極推銷自研芯片
- 谷歌無需拆分Chrome,可代價卻是安卓用戶支付
- 法國監管機構對谷歌公司處以3.25億歐元罰款
- 143億美金買來一場空,小扎向谷歌OpenAI低頭,史上最大AI賭注失速
- 自研SoC成為性能笑話,谷歌卻是在“端水”下大棋?
- 通義實驗室開源Mobile-Agent-v3刷新10項GUI基準SOTA
- AI讀網頁,這次真不一樣了,谷歌Gemini解鎖「詳解網頁」新技能
- 手機內存也有“公攤”,谷歌新機搞了個“AI專用”
- 又一國產多模態大模型開源,復雜聲音一耳朵分辨,多測試SOTA,還能聊哲學