
文章圖片
文章圖片

文章圖片
頭圖由AI生成
智東西
作者 | 程茜
編輯 | 心緣
智東西9月9日報道 , 昨天 , 阿里發布最新語音識別模型Qwen3-ASR-Flash , 該模型基于Qwen3基座模型訓練 , 支持11種語言和多種口音 。 用戶可以通過ModelScope、HuggingFace和阿里云百煉API Qwen3-ASR-Flash免費體驗 。
在ASR(自動語音識別)的多項基準測試中 , Qwen3-ASR-Flash在方言、多語種、關鍵信息識別、歌詞等方面的識別錯誤率明顯低于谷歌Gemini-2.5-Pro、OpenAI GPT-4o-Transcribe、阿里巴巴語音實驗室Paraformer-v1、字節豆包Doubao-ASR 。
具體來看 , 該模型支持中文、英語、法語、德語等11個語種 , 識別過程中能自動分辨語音語種、自動過濾靜音和背景噪聲等非語音片段 , 其是基于海量多模態數據以及千萬小時規模的ASR數據構建的語音識別服務 。
此外 , 用戶還可定制ASR結果 , 通過在上傳音頻時添加關鍵信息術語、音頻發生背景等上下文信息 , 就能使識別結果匹配這些已有信息 。
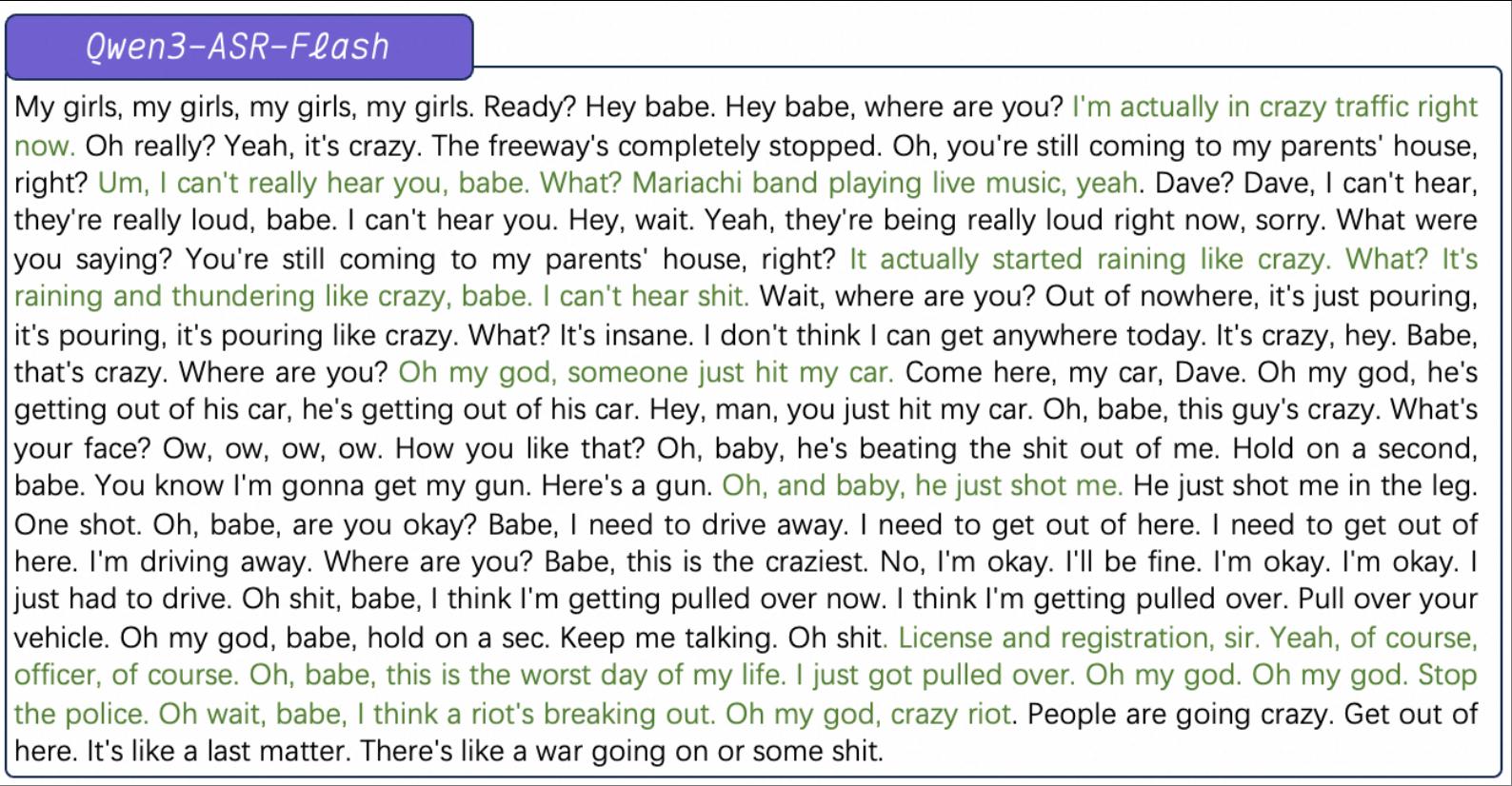
下面是官方放出的電競比賽解說音頻示例 。 研究人員為這一場景配置了背景信息 , 包括關鍵詞列表、這場游戲的背景等 。 因此識別結果中 , 即使電競解說人員的語速非常快也沒有影響識別游戲專業術語的效果 。
https://oss.zhidx.com/fec737df52316dd65dba06796cdb1eb9/68befd80/uploads/2025/09/68bf7afe744dc_68bf7afe6ff29_68bf7afe6fede_csgo.wav
ModelScope地址:
https://modelscope.cn/studios/Qwen/Qwen3-ASR-Demo
Hugging Face地址:
https://huggingface.co/spaces/Qwen/Qwen3-ASR-Demo
阿里云百煉API調用地址:
https://bailian.console.aliyun.com/?tab=doc#/doc/?type=modelurl=2979031
一、能識別游戲解說、英文說唱 , 連續多種噪音抗干擾拉滿官方放出了5個演示示例 , 包含多種類型噪聲、多語種快速切換、方言、專業名詞的音頻識別難題 。
第一個是夾雜手機鈴聲、車鈴聲、音樂聲、水聲、雷聲等多種類型的連續噪音 , 其中還會有不同人物之間切換對話 , Qwen3-ASR-Flash在多人同時說話或者說話間隔非常短的情況下也對語音進行了準確識別 , 沒有受到噪聲干擾 。
https://oss.zhidx.com/383cc163e20957eddc21e7e86a4b3f07/68befd80/uploads/2025/09/68bf7ae0b33d2_68bf7ae0ab8c0_68bf7ae0ab888_noise3.wav
第二個是英文說唱 。 英文說唱的特點是語速快、歌詞中單詞連讀情況多 , 識別結果中很多歌詞中的單詞連讀、長難句識別準確 , 且沒有受到背景音樂的干擾 。
https://oss.zhidx.com/b2535c852c6391fdc4b1c8e71e963b26/68befd80/uploads/2025/09/68bf7b0a871b3_68bf7b0a80b74_68bf7b0a80b42_en_rap2.wav
第三個是方言的識別 。 這一場景中 , 音頻中主人公正在開車 , 有主人公的方言和智能語音客服的普通話穿插出現 , 音頻中智能語音客服將“糾正”錯誤識別成了“96” , Qwen3-ASR-Flash進行了準確識別 。
https://oss.zhidx.com/16a9a5026b271ec29d2b519f5384b210/68befd80/uploads/2025/09/68bf7b174e73d_68bf7b1747a22_68bf7b17479f3_noise1.wav
第四個是多語種句子切換 , 7秒的音頻里有英語、日語等5種語言 , 識別結果都進行了一一呈現 。
https://oss.zhidx.com/05e13dcd6a7ff02eddf2fc36c488c698/68befd80/uploads/2025/09/68bf7b2154e14_68bf7b214eed6_68bf7b214eea3_mls3.wav
最后是化學課程的一段音頻 。 識別結果中酯基、酸、醛、氨等化學名詞 , 以及音頻中人物的語氣詞識別并未出錯 。
https://oss.zhidx.com/5f39d32577be13371754b8f8187ad8d2/68befd80/uploads/2025/09/68bf7b289da6c_68bf7b2897f24_68bf7b2897ef8_course.wav
二、歌詞識別錯誤率低于8% , 可定制語音識別結果性能表現 , Qwen3-ASR-Flash的自動語音識別錯誤率 , 在中文、英文、多語言自動語音識別、歌詞、關鍵信息識別的錯誤率都要低于Gemini-2.5-Pro、GPT-4o-Transcribe、Paraformer-v1、Doubao-ASR 。
在歌詞識別中 , Qwen3-ASR-Flash支持清唱和帶畢竟音樂的整首歌識別 , 研究人員實測識別錯誤率低于8% 。
該模型支持普通話以及四川話、閩南語、吳語、粵語等方言 , 英式、美式及多地區口音的英語 , 其他語言如法語、德語、俄語、意大利語、西班牙語、葡萄牙語、日語、韓語和阿拉伯語 。
如果想要獲得定制化的ASR結果 , 用戶可提供任意格式的背景文本來獲得傾向性ASR結果 , 且用戶無需對上下文信息進行預處理 。
其支持的格式包括但不限于以下一種 , 簡單的關鍵詞或熱詞列表、任意長度和來源的完整段落或整篇文檔、以任意格式混合的關鍵詞列表與全文段落、無關甚至無意義的文本 。 研究人員提到 , 模型對無關上下文的負面影響具有高度魯棒性 。
基于此 , Qwen3-ASR-Flash可以利用該上下文識別并匹配命名實體和其他關鍵術語 , 輸出定制化的識別結果 。
結語:后續將迭代通用語音識別精度一直以來 , 復雜聲學環境、多樣化語音特征、專業術語等都是語音識別的最大難點 。 此次為了保證用戶對輸出結果的可控 , 阿里研究人員上線了背景文本上傳功能 , 使得這一生成結果能更加符合用戶的預期 。
【阿里端出最強語音模型!英文rap精準轉文字,準確率干翻全球】下一步 , 研究人員將提升Qwen3-ASR-Flash的通用識別精度 , 進一步降低普通用戶的使用門檻 。
推薦閱讀














- 權威報告:中國AI云市場阿里云占比35.8%位列第一 高于2到4名總和
- 阿里夸克“教育計劃”陷身份認證風波,在華留學生無法領取會員
- 中國力量閃耀IFA2025 海信引領高端出海新范式
- 替代國外芯片,國產最強的CPU、GPU、Soc分析
- 剛剛,阿里首個超萬億參數新王登基!Qwen3-Max屠榜全SOTA
- 7000mAh頂配小屏!小米這新機,預定年度最強
- 聯想發布二代旗艦掌機Legion Go 2:最強銳龍U、可拆卸手柄煥然一新
- 半年收入55億,最強國產“CPU+GPU”龍頭,替代intel+Nvidia
- iPhone17 Pro Max價格又變?續航最強卻意外“良心定價”
- 搞定3nm,100%自研,中國最強刻蝕機廠商,半年收入50億