文章圖片

文章圖片

文章圖片

文章圖片
蘋果在 Hugging Face上放大招了!這次直接甩出兩條多模態主線:FastVLM主打「快」 , 字幕能做到秒回;MobileCLIP2主打「輕」 , 在 iPhone 上也能起飛 。 更妙的是 , 模型和Demo已經全開放 , Safari網頁就能體驗 。 大模型 , 真·跑上手機了 。
就在剛剛 , 蘋果在Hugging Face上重磅開閘:
這一次不是零碎更新 , 而是FastVLM與MobileCLIP2兩條多模態主線集中亮相 。
一個主打「快」 , 把首字延遲壓到競品的1/85;
另一個突出「輕」 , 在保持與SigLIP相當精度的同時 , 體積減半 。
打開攝像頭實時字幕、離線識別翻譯、相冊語義搜索 , 這些場景都能體驗 。
更重要的是 , 模型和Demo都已經開放 , 科研、應用到落地一步到位 。
實時字幕 , 不再卡頓的多模態FastVLM為何這么快?因為它換上了蘋果自研的FastViTHD編碼器 。
傳統多模態模型要么犧牲分辨率 , 要么被成千上萬的視覺token拖慢推理 。
而FastViTHD通過動態縮放和混合設計 , 讓模型既能看清高分辨率圖像 , 又能保持極低的延遲 。
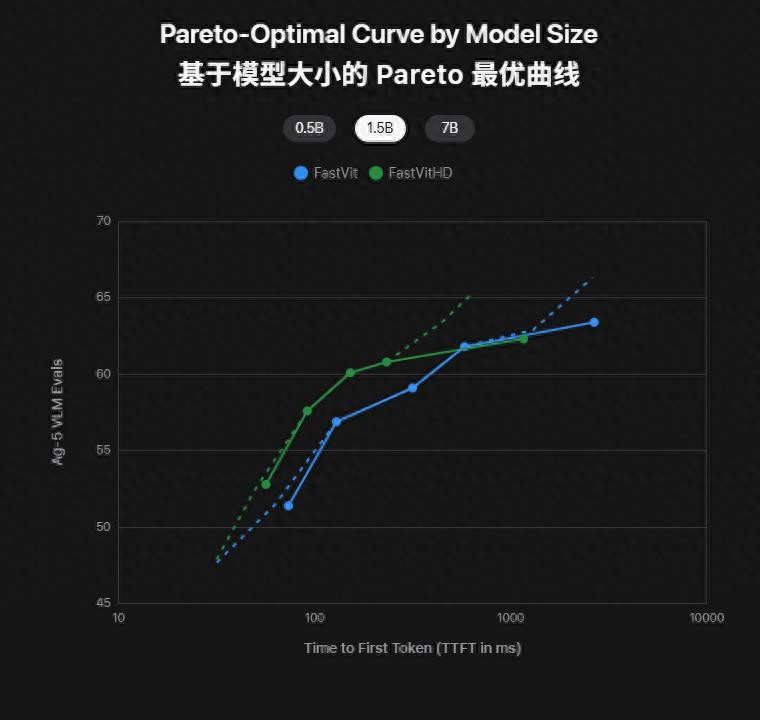
FastVit 與 FastVitHD 的性能對比:綠色曲線整體更靠左上 , 代表在同等規模下既更快又更準
從這條對比曲線能看得很清楚:同樣是0.5B、1.5B、7B參數量 , 綠色的FastVitHD總比藍色的FastVit更靠左上 。
換句話說 , 就是延遲更低、精度更高 。
這也就是FastVLM能在不降分辨率的情況下依舊秒回的秘密 。
FastVLM用更少的視覺token處理高分辨率輸入 , 直接把「算力負擔」減輕 。
那么 , 速度差距有多夸張?
官方對比顯示 , FastVLM-0.5B的首字延遲相對LLaVA-OneVision-0.5B快85× 。
不同模型在 7 個視覺語言任務上的平均準確率(縱軸)與首字延遲 TTFT(橫軸)的對比
從這張性能對比圖可以直觀看出:FastVLM越大 , 性能越強 , 但延遲始終壓得極低 。
FastVLM的0.5B、1.5B、7B模型 , 都穩定壓在左上角 。
對比LLaVA-OneVision、LLaVA-Next等傳統方案 , 不僅更慢 , 準確率也沒拉開差距 。
也就是說 , FastVLM 把快和準同時做到極致 , 不是「犧牲質量換速度」 , 而是真正實現了兩頭兼顧 。
使用低分辨率(左)和高分辨率(右)輸入圖像時VLM性能的比較
更關鍵的是 , FastVLM已經放到了Hugging Face , 配好WebGPU Demo , 用 Safari打開就能直接體驗 。
更小更快 , 零樣本也能打如果說 FastVLM 代表「極致的快」 , 那 MobileCLIP2就是「輕裝上陣」 。
它是蘋果在2024年推出MobileCLIP的升級版 。
研究團隊通過多模態蒸餾、captioner teacher和數據增強等手段 , 把「大腦」壓縮進「小身體」 , 既減輕了模型體積 , 又保住了理解力 。
過去 , 圖像檢索和描述往往依賴云端算力 , 如今MobileCLIP2能直接在iPhone上完成推理 。
照片不必上傳 , 結果幾乎即時返回 , 不僅快 , 而且更安全 。
從整體測試曲線來看 , MobileCLIP2 在「精度-延遲」坐標軸上整體更靠左上 。
這意味著它在保持高精度的同時 , 把延遲顯著壓低 。
MobileCLIP2在ImageNet-1k上的 zero-shot表現:相比SigLIP和舊版MobileCLIP , 更小的延遲下實現相近甚至更高的精度 。
在測試中 , S4模型在ImageNet-1k上與SigLIP-SO400M/14精度相當 , 但參數量僅有一半 。
在iPhone 12 ProMax上 , 延遲更是比DFN ViT-L/14低了2.5倍 。
相比之下 , B模型相對上代MobileCLIP-B又提升了+2.2% , 而S0/S2則以接近ViT-B/16的精度實現了更小體積與更快速度 。
從體驗到集成 , 兩步就能上手蘋果這次不只是發模型 , 還順手鋪好了路:先試Demo , 再集成開發 。
最直觀的方式 , 就是去Hugging Face打開他們提供的FastVLM WebGPU Demo 。
在Safari授權攝像頭后 , 就能立刻看到實時字幕效果 。
MobileCLIP2 的模型卡同樣提供推理接口 , 上傳一張照片或輸入一句描述 , 就能馬上出現結果 。
體驗過后 , 如果想把這些功能真正變成應用 , 開發者可以用Core ML+Swift Transformers工具鏈 , 把模型直接集成到iOS或macOS里 。
蘋果在WWDC和Hugging Face的文檔中都給了現成示例 , GPU和神經引擎都能調動 , 性能和能耗都有保證 。
這意味著「在iPhone 上跑大模型」不再只是一個演示 , 而是可以被直接拿來做相冊搜索、相機翻譯、直播字幕等具體功能 。
「體驗+開發」 , 對開發者來說再也不是口號 , 而是真實可用的路徑 。
光看模型介紹很難有感覺 , 真正打動人的 , 還是那些使用成功的瞬間 。
當你打開FastVLM的WebGPU Demo , 舉起手機攝像頭對著紙上的字——幾乎是瞬間識別 。
FastVLM能快速識別圖像中的文字
在Reddit社區 , 有人親測后寫道:
「快得不可思議 , 盲人用屏幕閱讀器都能實時跟上 。 橫著拿手機 , 邊走邊敲盲文輸入 , 都不卡 。 」—— r/LocalLLaMA
這句話把FastVLM的速度感形容得淋漓盡致:
不僅普通用戶能體驗 到「字幕秒回」 , 在無障礙場景下 , 它甚至讓盲文輸入與屏幕閱讀器同步成為可能 。
還有技術社區的用戶補充道:
「FastVLM 能做到高效又準確的圖像文本處理 , 速度和精度都比同類模型更出色 。 」 —— r/apple
從生活中的真實體驗 , 到技術層面的驗證 , 網友們的評價都指向一個結論:FastVLM不只是快 , 而且快得可靠 。
FastVLM vs MobileCLIP2 該怎么?。 ?看了這篇介紹 , 可能有人會問:那我到底該用哪個?
如果你是內容創作者、博主 , 追求字幕秒出的體驗 , 那FastVLM是首選 。
如果你更需要相機翻譯、離線識別 , 那MobileCLIP2更合適 。
當然 , 如果你的應用場景既涉及實時字幕 , 又需要圖文檢索 , 那么二者完全可以組合使用 。
但要注意 , WebGPU在不同瀏覽器和機型上的兼容性并不完全一致;
而且端側模型雖然解決了隱私和延遲 , 但在算力和續航上始終存在權衡 。
即便如此 , 這一次蘋果在Hugging Face上的「開閘」 , 依然有著標志性意義 。
不僅放出了模型 , 還把Demo、工具鏈、文檔全部交到社區手里 。
對開發者來說 , 這已經不是一篇論文 , 而是一條能被立刻走通的路線 。
從快到輕 , 從體驗到集成 , FastVLM和MobileCLIP2展示了一個清晰的信號——
在iPhone上跑大模型 , 不再是遙遠的未來 , 而是觸手可及的現在 。
參考資料https://huggingface.co/apple
https://x.com/ClementDelangue/status/1962526559115358645
https://machinelearning.apple.com/research/fast-vision-language-models?utm_source=chatgpt.com
https://www.heise.de/en/news/FastVLM-Apple-s-new-image-to-text-AI-should-be-significantly-faster-10382408.html?utm_source=chatgpt.com
https://ossels.ai/apple-mobileclip2-on-device-ai/?utm_source=chatgpt.com
【蘋果端側AI兩連發,模型體積減半、首字延遲降85倍,iPhone離線秒用】本文來自微信公眾號“新智元” , 作者:傾傾 , 36氪經授權發布 。
推薦閱讀
















- 華為蘋果小米或上演“旗艦三國殺”
- 一加13系列手機銷量數據曝光:兩款機型賣出115萬臺
- 蘋果秋季新品發布會有望推出M5芯片iPad Pro 以紀念iPad Pro誕生十周年
- 國內手機榜單更新:OPPO第三,蘋果跌出前五,第一名無人撼動
- 最猛升級+最猛備貨1億臺,iPhone17ProMax是蘋果的最猛底牌?
- 8300毫安電池有兩把刷子,淺談榮耀X70的續航,難怪會熱銷
- 誰該買iPhone 16e?這兩類人可以,其他人別碰
- 蘋果計劃在 2025 年底前在中國市場推出 Apple Intelligence
- 蘋果四位AI大將出走,其中三位是華人
- 蘋果新品官宣:9月10日,正式發布