
文章圖片

文章圖片
文章圖片
文章圖片

文章圖片
文章圖片
文章圖片

文章圖片
文章圖片
文章圖片

文章圖片
編輯:元宇
【新智元導讀】為了降低大模型預訓練成本 , 最近兩年 , 出現了很多新的優化器 , 聲稱能相比較AdamW , 將預訓練加速1.4×到2× 。 但斯坦福的一項研究 , 指出不僅新優化器的加速低于宣稱值 , 而且會隨模型規模的增大而減弱 , 該研究證實了嚴格基準評測的必要性 。
一直以來 , 預訓練 , 都是大模型訓練過程中最花錢的部分 。
比如 , 在DeepSeek V3中 , 它的成本占比就超過95% 。
誰能在這里節省算力 , 就等于賺了 。
長期以來 , AdamW都是「默認選項」 。 但最近兩年 , 出現了很多新的優化器 。
它們大都聲稱能夠相比AdamW , 將預訓練加速1.4×到2× , 但卻很少能真正落地 。
斯坦福大學的研究人員 , 認為問題主要出現在兩個方法學缺陷上:
一些基線的超參數調得不當;
許多實驗局限于較小規模的設置 , 導致這些優化器在更廣泛、更真實場景下的表現仍待驗證 。
論文地址:https://arxiv.org/abs/2509.02046
有趣的是 , 這篇論文的標題「神奇優化器在哪里」(Fantastic Pretraining Optimizers and Where to Find Them) , 正是「捏它」自《神奇動物在哪里》(Fantastic Beasts and Where to Find Them) 。
不得不說 , 論玩梗還是大佬們厲害!
不同縮放范式下的加速差異
研究人員對比了大模型在不同縮放范式下的加速差異 。
他們在四種不同的數據-模型比(相當于Chinchilla最優范式的 1×、2×、4×、8×)下進行基準測試 , 并將模型規模擴展到1.2B參數 。
圖1左上顯示 , 在被廣泛采用的GPT-3配方中 , 僅調一個超參數 , 就能讓預訓練獲得2×的加速 , 這突顯了正確超參數優化的重要性 。
研究表明 , 在一系列模型規模和數據-模型比上 , 進行細致的超參數調優與訓練結束時的評測是必要的 , 主要有三個原因:
首先 , 超參數不能盲目遷移 , 在優化器間固定超參數會導致不公平的比較 。
第二 , 新優化器的加速低于宣稱值 , 且隨模型規模增大而減弱 。 相對于研究人員調優的AdamW基線 , 其他優化器的加速不超過1.4× 。
此外 , 雖然Muon、Soap等新優化器在小模型(0.1B)上顯示出1.3×加速 , 但在8×Chinchilla比例下的1.2B參數模型上 , 加速會降到約1.1× 。
第三 , 早期的損失曲線可能產生顯著誤導 。
在學習率衰減期間 , 不同優化器的損失曲線可能多次交叉 , 因此用中間檢查點來評判優化器 , 得到的排名可能與在目標訓練預算下比較的結果不同 。
優化器設計的新見解
研究人員基于基準測試 , 帶來了三個關于優化器設計的新見解:
1. 小模型更適合基于矩陣的優化器
研究人員發現 , 對于小模型 , 基于矩陣的優化器 , 持續優于基于標量的優化器 。
基于標量的優化器(如AdamW、Lion、Mars等) , 需要通過標量操作逐個更新參數 。
經過適當調參后 , 所有基于標量的優化器的優化速度與AdamW相近 , 平均加速比不足1.2× 。
盡管其更新規則多樣 , 但在小于520M參數的模型上 , 基于矩陣的優化器相對AdamW均可帶來約1.3×的加速 。
2. 最優優化器的選擇 , 關鍵指標是「數據-模型比」
在1×Chinchilla范式下的贏家 , 隨著數據-模型比提升 , 可能不再最優 。
比如 , 在較小的Chinchilla比例下 , Muon一直是表現最好的優化器 。
但當數據-模型比增至8×或更高時 , Kron和Soap的表現優于Muon(圖3與圖4) 。
在本項研究中 , 研究人員研究了表1所列的11種優化器 。
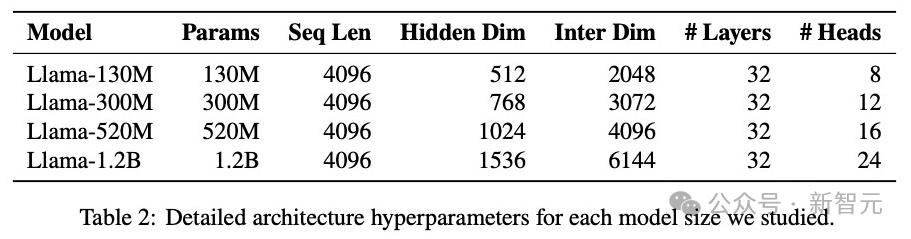
模型參數量 , 涵蓋了130M、300M、520M、1.2B四種規模 , 詳細超參數見表2 。
超參數的三種調參方式
按照不同階段 , 研究人員對超參數采用了三種不同程度的調參方式:
階段1:對超參數進行「細顆粒度」調參
研究人員在6種不同設置上執行該遍歷 , 具體為1×Chinchilla下的130M、300M、500M , 以及2×、4×、8×Chinchilla下的130M 。
對于每個優化器以及上述六種范式 , 研究人員都找到了一個按坐標的局部最優解 。
表3是一個針對300M參數、1×Chinchilla的AdamW示例性超參數優化過程 。
階段2:著重調整對「尺度敏感」的超參數
由于廣泛調參在更大規模實驗上代價過高 , 所以 , 研究人員對該過程進行了簡化 , 著重調整對「尺度敏感」的超參數 。
如表4 , 研究人員僅將對尺度敏感的超參數帶入階段2 , 從而把下一輪調參對象集中在那些跨尺度確實需要重新調參的超參數上 。
通過這組實驗 , 研究人員觀察到兩點現象:
1.基于矩陣的優化器始終優于基于標量的優化器 , 但所有優化器相對AdamW的加速比都不超過1.5×;
2.在基于矩陣的優化器內部 , Muon在1–4×Chinchilla比例下表現最佳 , 但隨著Chinchilla比例提高 , 會被Soap與Kron反超 。
階段3:為進一步外推而建立超參數縮放律
研究人員基于階段2獲得的優化超參數設置 , 擬合一個平滑的縮放律 , 用以預測每個隨尺度敏感的超參數的最優值 。
作為模型大小N , 與數據預算D的函數 , 研究人員將每個隨尺度敏感超參數h的最優值建模為:
其中A、B、α與β為學習得到的系數 。
研究人員在每個優化器的12個觀測三元組(N , D , h)上 , 用非線性最小二乘來估計這些參數 , 使預測與真實最優超參數值的平方誤差最小 。
為檢驗預測質量 , 研究人員在N=1.2B、Chinchilla=1的設置下對AdamW運行了完整的階段1遍歷 , 并將識別出的最優解與擬合出的超參數進行對比 。
在圖2上圖中 , 研究人員繪制了兩個階段的C4/EN驗證損失;在圖2下圖中 , 研究人員繪制了為部分優化器選擇的運行所對應的HellaSwag表現 。
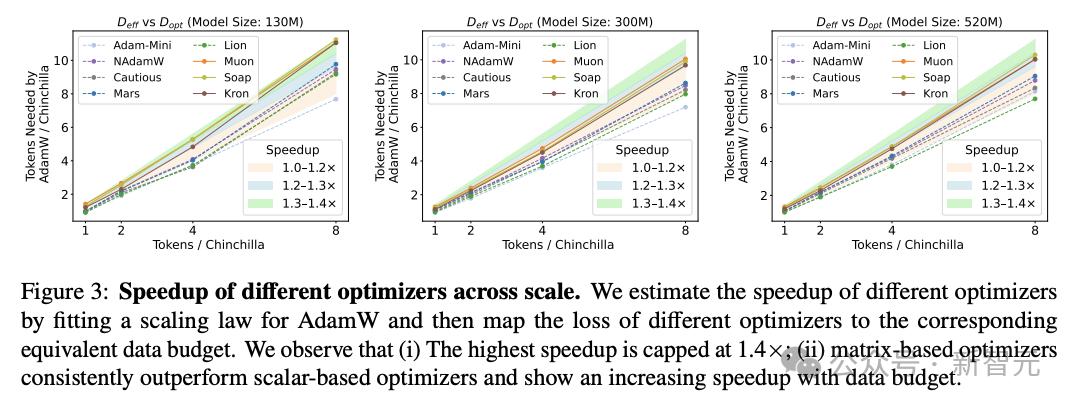
在圖3中 , 顯示了跨尺度的不同優化器加速 。
研究人員通過為AdamW擬合縮放律 , 并將不同優化器的損失映射到對應的等效數據預算來估計加速 , 得到了以下二點觀察:
1. 最高加速被限制在1.4×;
2. 基于矩陣的優化器始終優于基于標量的優化器 , 且隨數據預算增加呈現更高的加速(表現出超線性趨勢) 。
實證發現
1. 在0.1B–0.5B參數模型上的結果
在所有模型規模與算力預算下 , 方差減少類的Adam變體(NAdamW、Mars、Cautious)與基于矩陣的優化器都相對AdamW基線 , 帶來了加速 。
然而 , 沒有任何方法達到了過往文獻聲稱的2×的加速 。
研究人員得出如下結論:
(1)基于矩陣的方法優于基于標量的方法 。 加速比隨數據預算增加而上升 , 但隨模型規模增大而下降 。
(2)方差削減技術帶來小而穩定的提升 。
在基于標量的家族中 , 所有方差削減型的Adam變體(NAdamW、Mars、Cautious)都穩定地超過vanilla的AdamW——僅在最小規模實驗上有輕微落后 。
(3)AdamW的內存高效變體與AdamW的表現保持緊密 。
兩種內存高效的AdamW變體(Lion、Adam-mini) , 盡管輔助狀態更少 , 其表現與AdamW緊密跟隨 , 最多僅慢5% , 有時甚至優于AdamW 。
2. 在1.2B參數模型上的結果
研究人員利用擬合的超參數縮放律 , 將模型規模擴大到1.2B , 以考察優化器的加速如何隨模型規模變化 。
觀察到NAdamW、Muon與Soap依然相對AdamW帶來加速 , 但這些優化器的加速減弱到約1.1×(圖4 , 左與中) , 且不再帶來下游改進(表 5) 。
3. 高數據-模型比
在130M與520M模型的8×Chinchilla范式下 , Muon已被Soap超過 。
為進一步驗證 , 研究人員將三份300M模型訓練到16×Chinchilla , 并確認當數據-模型比增加時 , Muon不再是最優優化器(圖4 , 右) 。
研究人員推測 , 當數據-模型比增大時 , Soap與Kron保持的二階動量會更有效 。 從長期看 , 對參數方向異質性的自適應可能帶來更大的加速 。
該研究證實了嚴格基準評測的必要性 。
各優化器的共性現象
研究人員在預訓練中 , 通過對11種深度學習優化器進行了基準評測 , 發現它們相對AdamW的真實增益遠小于此前報道 。
由此 , 研究人員強調了三個關鍵教訓:
1.許多聲稱的加速源于超參數調優不足 , 因為公平的掃參會消除大多數表面的優勢;
2.基于早期或不一致的評估進行比較可能具有誤導性 , 因為在完整訓練軌跡上優化器的排名常會發生變化;
3.即使表現最好的替代方案也只提供溫和的加速 , 且隨模型規模增大而進一步減弱 , 在12億參數時降至1.1× 。
【震撼實錘!清華姚班校友揭1.4×加速陷阱:AI優化器為何名不符實?】作者介紹
Kaiyue Wen
Kaiyue Wen是斯坦福大學的博士生 。 目前在馬騰宇 (Tengyu Ma) 的課題組進行輪轉 , 同時與Percy Liang老師合作 。
他本科畢業于清華大學姚班 , 期間獲得了獲得了馬騰宇、劉知遠、Andrej Risteski、張景昭、王禹皓以及李志遠等多位老師的指導 。
他的研究興趣涵蓋深度學習的理論與應用 , 長遠目標是理解深度學習背后的物理學原理 , 并堅信理論分析與實證研究相結合是實現這一目標的關鍵 。
馬騰宇(Tengyu Ma)
Tengyu Ma是斯坦福大學計算機科學系和統計系的助理教授 。
他本科畢業于清華姚班 , 于普林斯頓大學獲得博士學位 。
他的研究興趣涵蓋機器學習、算法理論等方向 , 具體包括:深度學習、(深度)強化學習、預訓練/基礎模型、魯棒性、非凸優化、分布式優化以及高維統計學 。
Percy Liang
Percy Liang是斯坦福大學計算機科學副教授 , 兼任基礎模型研究中心(CRFM)主任 。 同時也是CodaLab Worksheets的創建者 , 并借此堅定倡導科研工作的可復現性 。
他專注于通過開源和嚴格的基準測試 , 提升基礎模型(特別是大語言模型)的可及性與可理解性 。
他曾圍繞機器學習和自然語言處理領域進行了廣泛研究 , 具體方向包括魯棒性、可解釋性、人機交互、學習理論、知識落地、語義學以及推理等 。
此前 , 他于2004年在MIT獲得學士學位 , 并于2011年在UC伯克利獲得博士學位 。
參考資料:
推薦閱讀











- 燧原科技趙立東:中國AI芯片創新之路上的清華力量
- 華為Mate80震撼亮相:設計拉滿,看完后我很欣慰
- 出席清華五道口金融EMBA論壇,Soul張璐闡述Z世代社交新趨勢
- iPhone 17 Pro火力全開:三主攝+12GB運存,看完后我大為震撼
- 重新定義個性化視頻體驗,快手與清華聯合提出靈犀系統
- 清華、北航聯合提出類腦空間認知框架,導航、推理、早餐樣樣精通
- iPhone 17 Air實錘了,不再支持SIM卡,華為也有望跟進!
- 大規模強化學習框架RLinf!清華、北京中關村學院、無問芯穹等開源
- 清華崔鵬團隊LimiX:首個結構化數據通用大模型,性能超越SOTA
- iPhone 17「實錘」,eSIM 穩了