
文章圖片
文章圖片
文章圖片
文章圖片
文章圖片
文章圖片
文章圖片
機器之心報道
機器之心編輯部
清華大學、北京中關村學院、無問芯穹聯合北大、伯克利等機構重磅開源RLinf:首個面向具身智能的“渲訓推一體化”大規模強化學習框架 。
人工智能正在經歷從 “感知” 到 “行動” 的跨越式發展 , 融合大模型的具身智能被認為是人工智能的下一發展階段 , 成為學術界與工業界共同關注的話題 。
在大模型領域 , 隨著 o1/R1 系列推理模型的發布 , 模型訓練的重心逐漸從數據驅動的預訓練 / 后訓練轉向獎勵驅動的強化學習(Reinforcement Learning RL) 。 OpenAI 預測強化學習所需要的算力甚至將超過預訓練 。 與此同時 , 能夠將大規模算力高效利用的 RL infra 的重要性也日益凸顯 , 近期也涌現出一批優秀的框架 , 極大地促進了該領域的發展 。
圖1 : OpenAI 在紅杉資本閉門會上的分享
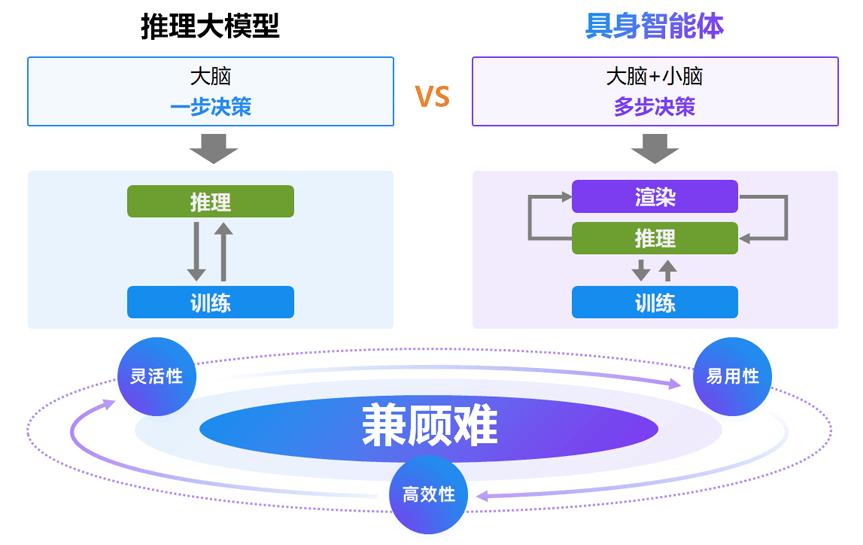
然而 , 當前框架對具身智能的支持仍然受限 。 相比推理大模型這一類純大腦模型 , 具身智能領域存在大腦(側重推理、長程規劃 , 如RoboBrain)、小腦(側重執行、短程操作 , 如OpenVLA)及大小腦聯合(快慢系統 , 如pi 0.5)等多樣模型 。
其次 , 具身智能除了包含Agentic AI的多步決策屬性外 , 他還有一個獨特屬性:渲訓推一體化 。 與工具調用智能體、瀏覽器智能體所交互的仿真器相比 , 具身仿真器通常需要高效并行物理仿真和3D圖形渲染等 , 因此當前主流仿真器通常采用GPU加速 , 耦合多步決策帶來了算力和顯存競爭的新挑戰 。
總的來說 , 具身智能領域不僅繼承了推理大模型和數字智能體的難點 , 同時還引入了新的渲訓推一體化特征 , 再加上具身智能模型尚未收斂 , 對框架的靈活性、高效性和易用性提出挑戰 。
圖 2:推理大模型與具身智能體對比圖
在這樣的背景下 , 清華大學、北京中關村學院和無問芯穹聯合推出了一個面向具身智能的靈活的、可擴展的大規模強化學習框架 RLinf 。
代碼鏈接:https://github.com/RLinf/RLinf Hugging Face鏈接:https://huggingface.co/RLinf 使用文檔鏈接:https://rlinf.readthedocs.io/en/latest/RLinf 的 “inf” 不僅代表著 RL “infrastructure” , 也代表著 “infinite” scaling , 體現了該框架極度靈活的系統設計思想 。
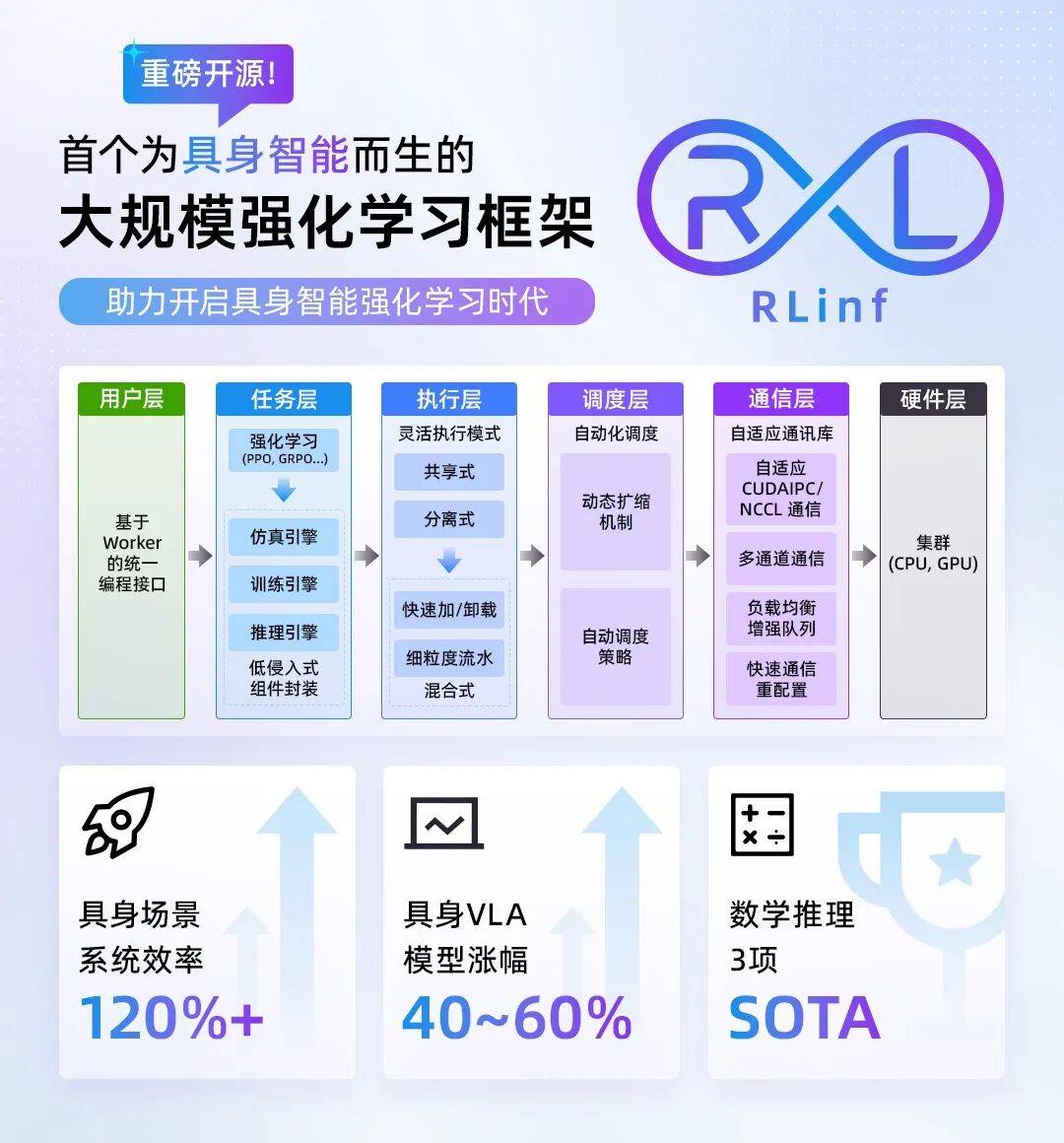
RLinf 的系統可以抽象為用戶層(統一編程接口)、任務層(多后端集成方案)、執行層(靈活執行模式)、調度層(自動化調度)、通信層(自適應通信)和硬件層(異構硬件)6 大層級 。 相比其他框架的分離式執行模式 , RLinf 提出的混合式執行模式 , 在具身智能訓練場景下實現了超 120% 的系統提速 , VLA 模型漲幅 40%-60% 。 同時 , RLinf 高度靈活、可擴展的設計使其可快速應用于其他任務 , 所訓練的 1.5B 和 7B 數學推理大模型在 AIME24、AIME25 和 GPQA-diamond 數據集上取得 SOTA 。
圖 3:RLinf 系統及亮點介紹
設計 1:采用基于 Worker 的統一編程接口 ,
利用微執行流實現宏工作流 , 實現一套代碼驅動多種執行模式
當前已有強化學習框架通常采用兩種執行模式:共享式(所有卡跑同一個組件) 和 分離式(不同的卡分配不同的組件) 。 然而 , 這兩種模式在具身智能 “渲訓推一體” 的特點下都存在局限性 。 主要是:由于具身智能體多步決策的屬性 , 模型(Actor)要和仿真器(Simulator)頻繁交互 , 而當前框架一方面不支持仿真器狀態快速卸載和加載 , 另一方面若用共享式需要頻繁加載卸載組件 , 切換開銷大 , 嚴重降低系統效率 。
因此 , 目前已有的框架在這個場景下僅支持分離式訓練 , 但分離式采用 on-policy 算法訓練時資源閑置率高 , 系統氣泡比較大 。 RLinf 針對這一問題 , 提出了混合式執行模式 , 如圖 4 所示 , 這種模式兼具分離式和共享式的優勢 , 再配合上細粒度流水設計 , 使得系統幾乎無氣泡 , 顯著提升了系統運行效率 。
圖 4 : 共享式、分離式和混合式執行模式對比
然而 , 要想實現一套代碼驅動多種執行模式(即無需更改代碼 , 通過配置參數即可實現分離、共享或混合)是不容易的 , 一種標準的解決方案是構建計算流圖 , 但會導致編程靈活性降低 , debug 難度直線上升 , 所以當前已有框架通常只支持一種模式(分離或者共享) , 引入新的執行模式需要大量的系統開發 。
為此 , RLinf 提出了創新的宏工作流到微執行流的映射機制(Macro-to-Micro Flow , M2Flow) , 實現從組件級而非任務級進行調度 。 M2Flow 允許用戶使用過程式編程方式靈活構建復雜訓練流程 , 解決傳統計算流圖構建編程靈活性低的問題 , 同時能夠將過程式的訓練流程靈活映射到底層不同的執行模式上 , 為不同的訓練流程(如 RLHF、RLVR 等)選擇最優執行模式(配合自動調度模塊) 。
因此 , 該映射機制兼具過程式編程(Imperative Programming)的靈活性、易用性、易調試性和聲明式編程(Declarative Programming)的編譯優化能力 。 具體而言 , RLinf 采用基于 Worker 的統一編程接口 , 允許用戶將訓練流程中的不同組件 , 如模擬器、訓練推理引擎 , 封裝成不同 Worker , 然后通過過程式編程將這些 Worker 串起來形成完整的訓練流程 。 M2Flow 通過細粒度控制微執行流 , 即控制每個 Worker 的運行 GPU、執行的批大小、執行時機等 , 實現極度靈活的執行模式 。
總結來說 , RLinf 使用戶能夠以高度可適配的方式編排組件(Actor、Critic、Reward、Simulator 等) , 組件可以放置在任意 GPU 上 , 并自動配置不同的執行模式 , 目前支持 3 種執行模式:
共享式(Collocated Mode):用戶可以配置組件是否同時常駐于 GPU 內存 , 或通過卸載 / 重新加載機制交替使用 GPU 。 分離式(Disaggregated Mode):組件既可以順序運行(可能導致 GPU 空閑) , 也可以以流水線方式執行 , 從而確保所有 GPU 都處于忙碌狀態 。 混合式(Hybrid Mode):進一步擴展了靈活性 , 支持自定義組合不同的放置形式 。 典型案例是 Generator 和 GPU-based Simulator 執行分離式細粒度流水 , 二者與 Inference 和 Trainer 執行共享式 。設計 2: 面向具身智能大小腦不同訓練需求 ,
采用全新的低侵入式多后端集成方案 , 兼顧高效性和易用性
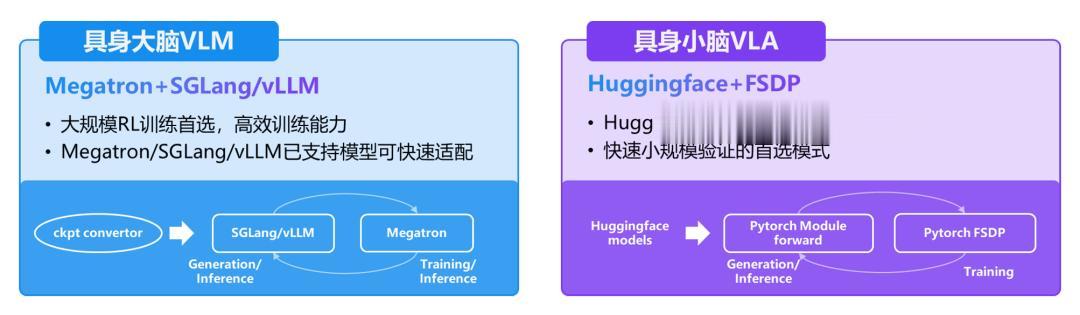
如前文提到 , 具身智能領域的特點是:大小腦同時存在 , 且該領域仍處在蓬勃發展期 , 技術路線尚未收斂 。 因此為了更好地支持具身智能不同用戶(如具身大小腦研究人員)的需求 , RLinf 集成了兩套后端:
Megatron + SGLang/vLLM:針對已收斂的模型架構(如具身大腦 VLM) , 支持已適配模型的快速接入 , 是大規模集群訓練的首選模式 。 在這一模式下 , RLinf 也采用了全新的低侵入式訓推引擎集成方式 , 有助于快速集成訓推引擎的更新版本(用戶可嘗試切換 SGLang 版本 , 方法見說明文檔 Advanced Feature 章節) , 進而能夠啟用 Megatron 和 SGLang/vLLM 的所有優化能力 , 如 5D 并行等 。 FSDP + Hugging Face:針對未收斂的模型架構(如具身小腦 VLA) , 支持 Hugging Face 模型開箱即用無需適配 , 是快速小規模驗證的首選模式 。 這一模式對于算力受限及新手用戶比較友好 , 特別為具身智能從業者打造 。
圖 5:RLinf 集成兩套后端
同時 RLinf 也支持多項來自一線從業者的剛需 , 包括 LoRA 訓練 , 斷點續訓 , 以及適應不同網速用戶的訓練可視化(Tensorboard、WB、SwanLab)等 。 此外 , RLinf 也正在集成 SFT 模塊 , 致力于提供一站式的服務 , 通過一套代碼滿足多樣化的訓練需求 。
設計 3: 設計面向強化學習的自適應通信庫和自動化調度模塊 ,
提升訓練穩定性和系統效率 。
自適應通信機制:
強化學習存在多個組件 , 且這些組件之間存在大量的數據交互 。 靈活、高效的互通信是支撐強化學習框架高效運行的關鍵 , 也是框架可擴展性的重要保證 。 因此 , RLinf 特別設計了一套面向強化學習的通信庫 , 其中主要包含四項優化技術:自適應 CUDAIPC/NCCL 通信、負載均衡傳輸隊列、多通道并發通信機制、快速通信重配置 。
自適應 CUDAIPC/NCCL 通信:無需用戶配置 , 根據兩個互通信組件所在 GPU 自動選擇使用 CUDAIPC 通信還是使用 NCCL 通信 , 即兩個組件位于同一個 GPU 上時使用 CUDAIPC , 位于不同 GPU 上時使用 NCCL 。 負載均衡傳輸隊列:可以根據上一個組件在不同 GPU 上所產生數據量的大小 , 在發送給下一個組件的不同 GPU 時做數據量負載均衡 , 使得下一個組件不同 GPU 的計算量接近 , 提升系統運行效率 。
圖 6:負載均衡傳輸隊列
多通道并發通信:使用多 CUDA stream 以及多網絡流并發的通信 , 避免隊頭阻塞(Head-of-Line Blocking) , 降低通信延遲 。 快速通信重配置:該功能主要面向大規模集群訓練 , 是實現下文秒級動態擴縮的支撐技術之一 , 可有效解決通信容錯和通信調整的問題 。自動化調度模塊:
大規模強化學習框架的優化目標是盡量減少系統資源閑置 。 已有框架通常采用人為指定資源配置的方案 , 依賴于人工經驗 , 容易造成系統資源浪費 , RLinf 設計了一套自動調度策略 , 可以針對用戶的訓練流以及用戶所使用的計算資源 , 選擇最優的執行模式 。
具體而言 , RLinf 會對各組件做自動化性能分析 , 獲得各組件對資源的使用效率和特征 。 然后 , 構建執行模式的搜索空間 , 該搜索空間描述了強化學習算法各組件對計算資源的分配復用關系 , 包括 “時分復用”、“空分復用” 以及二者結合的資源分配方案;在這樣的建模下 , RLinf 的自動化調度不僅支持已有強化學習框架中 “共享式” 和 “分離式” 的典型資源分配方式 , 還支持二者結合的混合分配方案的建模分析 。
最后 , 基于上述性能分析數據 , 在該空間中搜索出最優的執行模式 。 除此之外 , 該自動調度策略還集成 “秒級在線擴縮容(Online Scaling)” 能力 , 70B 模型只需 1 秒即可完成 5D 并行動態擴縮 , 而傳統方案需十幾秒甚至更久 。 該功能及相關論文將于 10 月上線開源版本 。 基于該技術可進一步實現運行時組件間計算資源的動態調度 , 配合細粒度流水設計 , 可以在保證算法 on-policy 屬性的前提下進一步壓縮系統氣泡率 , 且顯著提升訓練穩定性 。
RLinf 性能快覽
具身性能(采用 FSDP+HuggingFace 后端測試):
在應用上 , 與其他框架相比 , RLinf 的特色在于 Vision-Language-Action Models (VLAs)+RL 的支持 , 為研究人員探索 VLAs+RL 領域提供了良好的基礎算法性能及測試平臺 。 RLinf 支持了主流的 CPU-based 和 GPU-based 仿真器(具體平臺見說明文檔) , 支持了百余類具身智能任務 , 集成了主流的具身大模型 OpenVLA、OpenVLA-OFT、Pi 0 。
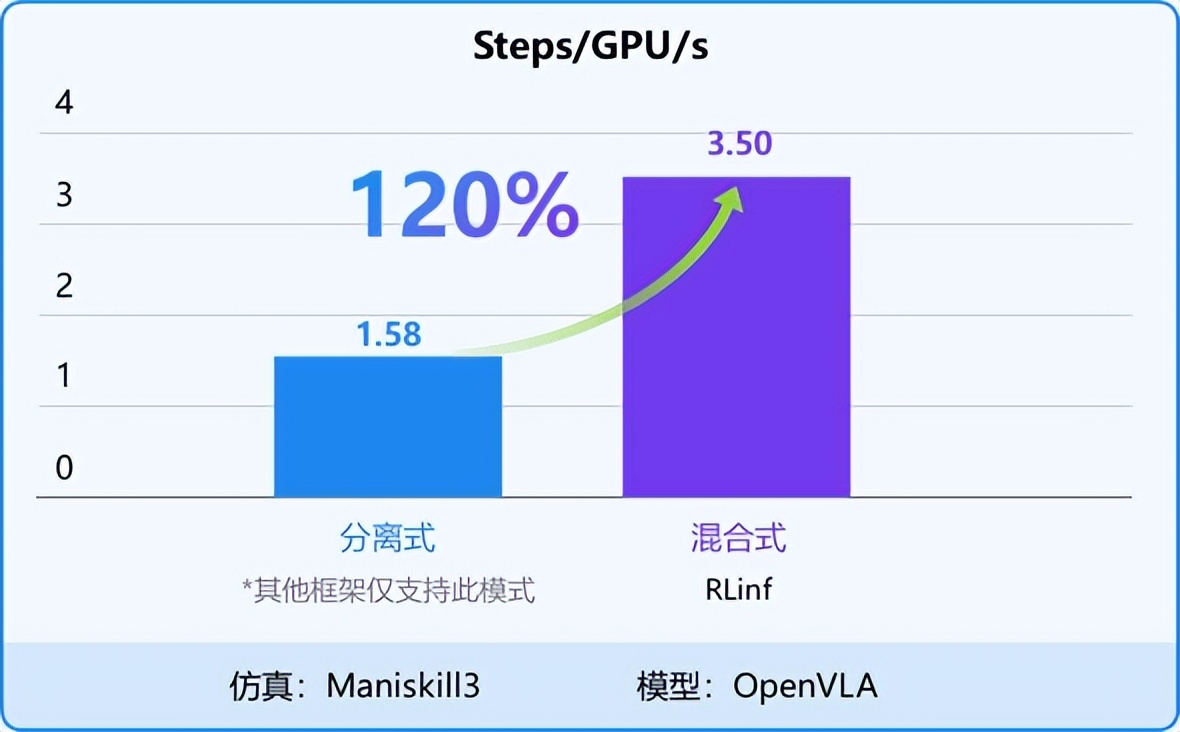
特別地 , 團隊率先實現了對 Pi 0 的大規模強化學習微調 , 相關算法及論文將在 9 月底發布 。 在量化指標上 , 以 Maniskill3(典型的 GPU-based Simulator )為例進行測試 , RLinf 采用混合式結合細粒度流水的執行模式 。 相比其他框架的分離式執行模式 , 系統效率顯著提速 120% 以上(圖 7) 。
OpenVLA 及 OpenVLA-OFT 在 Maniskill3 自建 25 個任務 [1
中采用 PPO 算法和適配具身的 GRPO 算法訓練后 , 成功率曲線如圖 8 所示 , 可以看到模型成功率可以從 SFT 后的 30%-50% 提升至 80%-90% , 漲幅 40%-50% 以上 。
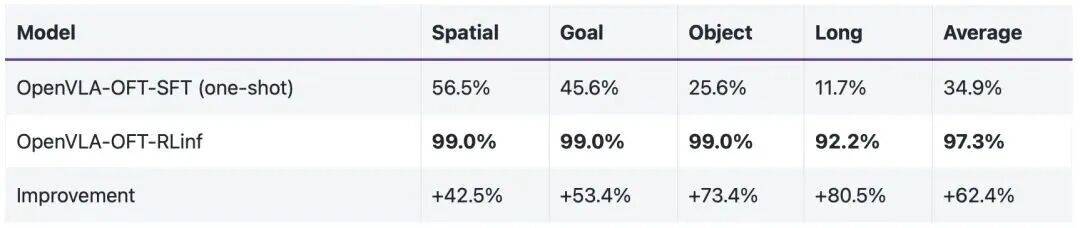
在公開測試平臺 LIBERO 的 4 個場景中 , OpenVLA-OFT 采用 RLinf 適配具身的 GRPO 算法訓練后 , 平均成功率達到 97.3% , 相比 SFT 模型漲幅 62.4% 。
團隊前序工作曾探討 RL 和 SFT 對 VLA 泛化性提升的不同之處 [1
, RLinf 將研究進一步拓展至大規模場景下 , 助力探索具身智能領域的 RL Scaling Law 。 相關模型已開源在 https://huggingface.co/RLinf , 歡迎下載測試 。
圖 7:RLinf 在 “渲訓推一體化” 任務訓練中顯著提速 120%+
圖 8:OpenVLA、OpenVLA-OFT 在 Maniskill3 自建 25 個任務中采用 PPO 算法及具身版 GRPO 算法的訓練曲線
表 1:OpenVLA-OFT 在 LIBERO 中采用具身版 GRPO 算法的測評結果
推理性能(采用 Megtatron+SGLang 后端測試):
面向具身智能是 RLinf 的應用特色 , 但 RLinf 的系統設計思想不僅限于具身智能 , 靈活、可擴展的設計理念使得其可以快速支持其他應用 , 體現了其通用性 。
以 RLinf 支持的推理大模型訓練為例 , 團隊集成優化后的 GRPO 算法 [2
進行了數學推理大模型的訓練 , 數據集為 AReal-boba 數據集 [3
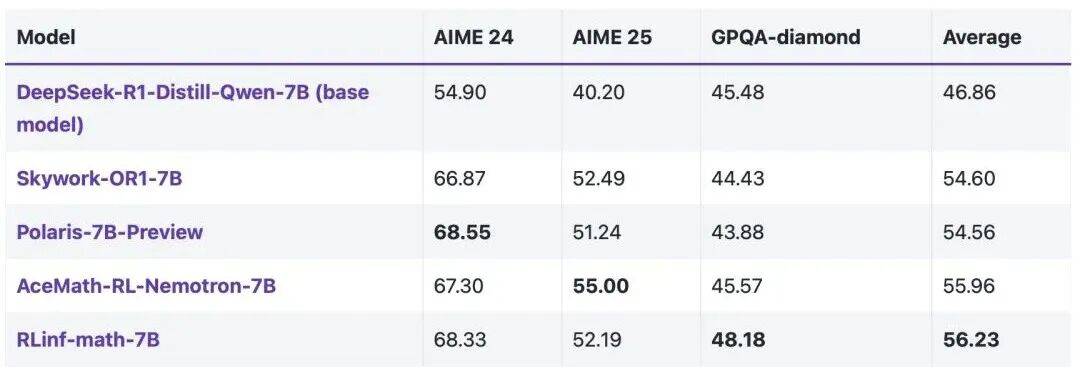
, 基座模型為 DeepSeek-R1-Distill-Qwen 。 在三個測試集(AIME24、AIME25、GPQA-diamond)中進行測評 , 32 個樣本取平均 , Pass@1 測試結果如表 2 和 3 所示 , RLinf-math-1.5B 和 RLinf-math-7B 在三個測試集上均取得 SOTA 性能 。
(注:表格中的模型均來自 HuggingFace 開源模型 , 統一測試腳本 https://github.com/RLinf/LLMEvalKit)
相關模型已開源在 https://huggingface.co/RLinf , 歡迎下載測試 。
表 2:1.5B 數學推理大模型在多個數據集的測評結果
表 3:7B 數學推理大模型在多個數據集的測評結果
Last but not least
考慮到框架的易用性 , RLinf 提供了全面且系統化的使用文檔 。 RLinf 在開發之初的目標就是開源 , 因此讓每一個用戶能夠理解、使用和修改是設計原則之一 , 也是一個優秀開源框架必備的屬性 。 團隊采用公司級代碼開發流程 , 確保文檔內容覆蓋從入門到深度開發的各層次需求 。 此外 , RLinf 還提供完整的 API 文檔與集成 AI 問答機器人支持 , 以進一步提升開發體驗與支持效率 。
圖 9:RLinf 文檔鏈接 https://rlinf.readthedocs.io/en/latest/
RLinf 團隊的開發成員具有交叉研究背景 , 包含從系統到算法到應用的技術全棧 , 例如系統架構設計、分布式系統、大模型訓練推理加速、強化學習、具身智能、智能體等 。 正是由于這樣的交叉背景 , 使得團隊能夠從應用需求驅動算法設計 , 算法指導系統設計 , 高效系統加速算法迭代 , 體現了大模型時代下新型科研形態 。 未來 RLinf 團隊也將持續開發和維護 , 具體 Roadmap 見 Github 網站 。
RLinf 項目地址 https://github.com/RLinf/RLinf
最后 , 誠摯地邀請大家體驗 RLinf 框架 , 并且與我們交流技術觀點與潛在合作機會 。 同時 , RLinf 團隊持續招聘博士后、博士、碩士、研究員、工程師及實習生 , 歡迎投遞簡歷 , 與我們共同推進下一代強化學習基礎設施的建設與發展 。
聯系方式:zoeyuchao@gmail.com yu-wang@mail.tsinghua.edu.cn
參考資料:
[1
Liu Jijia et al. \"What can rl bring to vla generalization? an empirical study.\" arXiv preprint arXiv:2505.19789 (2025).
[2
https://github.com/inclusionAI/AReaL
【大規模強化學習框架RLinf!清華、北京中關村學院、無問芯穹等開源】[3
https://huggingface.co/datasets/inclusionAI/AReaL-boba-Data
推薦閱讀















- OpenAI大神:人工智能導論課程停在15年前,本科首選機器學習導論
- 當蘇超遇上AI學習 京東電教超級品類日線下快閃邀你邊玩邊學
- 影像旗艦回歸2億主攝!vivoX300系列,向三星學習
- 宿舍生活全能手冊:學習、休息、娛樂統統搞定
- 從學習到娛樂全拿捏!6款AMD銳龍筆記本亮相京東開學季
- 迎接新學期,華碩無畏Pro16 2025高刷大屏全能本助力高效學習創作
- 夸克啟動最大規模教育計劃 惠及2000萬教師和5000萬大學生
- 蘋果急了?或破例大規模收購,瞄準AI創企Mistral和Perplexity
- Meta萬引強化學習大佬跑路,用小扎原話作為離別寄語,扎心了
- 小米首款PM旗艦!小米16系列繼續向蘋果學習,上代Pro變成ProMax