
文章圖片

文章圖片
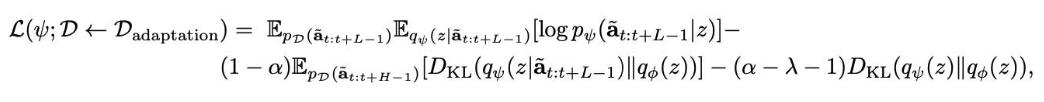
文章圖片

文章圖片
文章圖片

在多模態(tài)大模型的基座上 , 視覺 - 語言 - 動作(Visual-Language-Action VLA)模型使用大量機(jī)器人操作數(shù)據(jù)進(jìn)行預(yù)訓(xùn)練 , 有望實現(xiàn)通用的具身操作能力 。 然而 , 現(xiàn)有 VLA 基座模型的能力仍存在很大不足 , 在進(jìn)行目標(biāo)場景應(yīng)用時需要采集數(shù)十乃至數(shù)百小時目標(biāo)本體數(shù)據(jù)完成后訓(xùn)練(Post-Training) , 特別是當(dāng)目標(biāo)場景本體和預(yù)訓(xùn)練本體存在差異時 , 預(yù)訓(xùn)練和后訓(xùn)練階段的動作分布出現(xiàn)嚴(yán)重失配 , 從而引發(fā)了 VLA 模型跨本體適配(Cross-Embodiment Adaption)挑戰(zhàn) 。 在后訓(xùn)練階段通過堆疊目標(biāo)本體數(shù)據(jù)對抗這種失配的邊際收益迅速遞減 , 也難以有效擬合目標(biāo)場景動作分布 。
為了解決該問題 , 中國電信人工智能研究院(TeleAl)具身智能團(tuán)隊提出了一種 “對齊 - 引導(dǎo) - 泛化”(Align then Steer ATE)的 VLA 跨本體泛化框架 , 破解了 VLA 后訓(xùn)練難題 。 其核心思想是在潛空間中對齊跨本體動作分布 , 從而在后訓(xùn)練利用統(tǒng)一潛空間梯度引導(dǎo) VLA 策略的更新方向 。 無需改動現(xiàn)有 VLA 主干架構(gòu) , 實現(xiàn)了 VLA 模型后訓(xùn)練從調(diào)架構(gòu)向調(diào)分布的范式轉(zhuǎn)移 , 適配 Diffusion 和 Flow-Matching 等主流的 VLA 模型 , 極大減少 VLA 跨本體適配的數(shù)據(jù)需求 。
論文題目:Align-Then-Steer: Adapting the Vision-Language Action Models through Unified Latent Guidance 論文地址:https://arxiv.org/abs/2509.02055 項目地址:https://align-then-steer.github.io/ 開源代碼:https://github.com/TeleHuman/Align-Then-Steer研究動機(jī):從分布一致性突破 VLA 的跨本體泛化訓(xùn)練瓶頸
在面向特定具身場景的操作大模型應(yīng)用中 , 決定 VLA 能否進(jìn)行跨本體遷移的關(guān)鍵并非參數(shù)規(guī)模或主干架構(gòu)的復(fù)雜度 , 而是預(yù)訓(xùn)練階段與后訓(xùn)練階段的目標(biāo)本體和任務(wù)的動作分布的一致性 。 特別地 , 當(dāng)目標(biāo)本體的機(jī)械臂構(gòu)型、執(zhí)行器形態(tài)、關(guān)節(jié)自由度與本體物理約束等發(fā)生變化時 , 目標(biāo)動作分布不可避免地偏離預(yù)訓(xùn)練階段 VLA 學(xué)得的動作分布域 。 單純地通過采集大量真機(jī)數(shù)據(jù)在后訓(xùn)練階段彌補(bǔ)這一鴻溝 , 面臨迅速遞減的邊際收益 , 即單純數(shù)據(jù)堆疊難以有效地引導(dǎo)策略抵達(dá)目標(biāo)域 。
為了解決 VLA 的跨本體泛化適配問題 , 目前學(xué)界采用的方法主要從以下兩個角度開展 , 構(gòu)建統(tǒng)一的、語義級別的潛在動作表示 , 或通過運(yùn)動學(xué)重定向(Retargeting)手動將跨本體數(shù)據(jù)構(gòu)建到統(tǒng)一的動作空間 。 然而 , 這些路徑普遍存在兩類局限:一方面 , 目標(biāo)動作分布與原分布相差過大時(如預(yù)訓(xùn)練采用單臂數(shù)據(jù) , 目標(biāo)場景在雙臂) , 上述的方法難以準(zhǔn)確刻畫目標(biāo)本體的可行子分布;另一方面 , 現(xiàn)有方式依然面向自回歸范式 , 并沒有考慮擴(kuò)散 / 流匹配類策略的條件生成結(jié)構(gòu) 。 為了解決該問題 , TeleAI 具身智能團(tuán)隊提出了 “對齊 - 引導(dǎo) - 泛化”(ATE)框架 , 在統(tǒng)一的潛空間中先對齊動作統(tǒng)計 , 并在后訓(xùn)練階段引入可微的引導(dǎo)項牽引策略更新 , 僅利用少量樣本便可以將模型適配到目標(biāo)本體 。
研究方法
ATE 框架
ATE 框架的核心思想是先在潛空間中對齊動作分布 , 再利用潛空間的分類器引導(dǎo)去牽引后訓(xùn)練策略更新方向 。 ATE 框架如上圖所示 , 共分為兩個階段 。
第一階段先構(gòu)建一個與跨本體的統(tǒng)一動作潛空間 , 將預(yù)訓(xùn)練數(shù)據(jù)所蘊(yùn)含的跨任務(wù)、跨環(huán)境結(jié)構(gòu)性信息編碼到潛空間 , 再利用目標(biāo)域的有限樣本將目標(biāo)潛空間嵌入到預(yù)訓(xùn)練潛空間 。 在完成潛空間的對齊后 , 第二階段在統(tǒng)一的潛空間上設(shè)計引導(dǎo)函數(shù) , 并利用由此得到擴(kuò)散 / 流匹配 VLA 模型的分類引導(dǎo) , 在后訓(xùn)練階段顯式地將微調(diào)過程牽引至期望的目標(biāo)分布 , 而無需更改 VLA 模型主干模型結(jié)構(gòu) 。
在 ATE 框架中 , “對齊 — 引導(dǎo)” 都從分布的角度出發(fā):先把目標(biāo)域的動作潛分布嵌入到預(yù)訓(xùn)練動作潛分布的某個模態(tài)中 , 隨后用一個可微的分類器引導(dǎo)項把策略輸出的生成分布朝目標(biāo)分布持續(xù)推近 。 第一步等價于在潛空間上完成一次分布投影;第二步等價于在生成過程中為分布流添加一個外部力場 , 沿著統(tǒng)一潛空間定義的能量梯度推進(jìn)去噪 , 使最終的邊緣分布更接近適配數(shù)據(jù)分布 。
這種 “從調(diào)模型到調(diào)分布” 的范式遷移具有如下優(yōu)勢 。 第一 , 樣本效率提升:潛空間對齊將策略搜索范圍約束在包含目標(biāo)分布域的流形上 , 顯著降低了擬合到可行動作分布所需的數(shù)據(jù)量 。 第二 , 訓(xùn)練效率提升:分布引導(dǎo)避免模型全參數(shù)重訓(xùn)練 , 能夠在既定訓(xùn)練預(yù)算內(nèi)獲得更快的有效收斂 。 第三 , 工程可復(fù)用性增強(qiáng):潛空間引導(dǎo)只作用于動作專家模型后訓(xùn)練 , 與頂層模型解耦 , 具備即插即用的特性 , 可適配目前主流分層 VLA 。
第一階段:動作潛分布對齊
第二階段:動作潛分布引導(dǎo)
引導(dǎo)機(jī)制充分利用了統(tǒng)一潛空間的優(yōu)勢 , 既解決了跨實體和跨任務(wù)的適應(yīng)性問題 , 又保留了預(yù)訓(xùn)練階段習(xí)得的通用視覺 - 運(yùn)動先驗知識 , 顯著提升了模型在新環(huán)境下的適應(yīng)效率和性能 。
實驗結(jié)果
ATE 算法在 ManiSkill 與 RoboTwin 1.0 等多任務(wù)仿真評測中 , 相較于直接后訓(xùn)練 , 平均多任務(wù)成功率最高提升 9.8% 。 而在真實機(jī)器人跨本體現(xiàn)實場景中 , ATE 帶來最高 32% 的成功率增益 , 且表現(xiàn)出更穩(wěn)健的收斂行為與對光照、干擾的魯棒性 。 這些結(jié)果表明:ATE 框架在統(tǒng)一潛空間中引導(dǎo)學(xué)習(xí) , 使得 VLA 跨本體與跨任務(wù)泛化在有限數(shù)據(jù)下得到提升 , 而無需額外的數(shù)據(jù)與大規(guī)模重訓(xùn)練 。
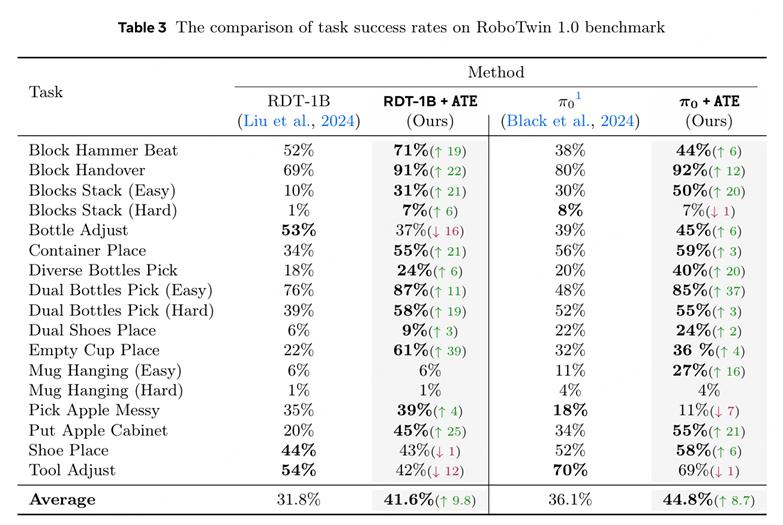
上表匯總了 17 個機(jī)器人操作任務(wù)上 , ATE 框架下 RDT 和 PI-0 在 RoboTwin 1.0 上的性能對比 。 ATE 框架對 RDT 與 PI-0 的平均提升分別約為 + 9.8 與 + 8.7 個百分點 , 顯示出跨任務(wù)的一致增益與較好的可遷移性 。 尤其在基線困難的長程任務(wù)中 , 單項增益明顯:例如 , RDT 在 Empty Cup Place 任務(wù)成功率由 22% 提升到 61%(+39) , Pi 0 在 Dual Bottles Pick (Easy) 任務(wù)上成功率由 48% 提升到 85%(+37) , 反映了潛空間對齊與引導(dǎo)在動作空間分布失配較大的場景中效果更顯著 。 與此同時 , 個別任務(wù)出現(xiàn)了小幅下降 , 如 RDT 在 Bottle Adjust(-16)、Tool Adjust(-12)、Shoe Place(-1) , Pi 0 在 Pick Apple Messy(-7)、Blocks Stack (Hard)(-1)、Tool Adjust(-1) 。 這類現(xiàn)象通常表現(xiàn)為目標(biāo)域動作分布較窄 。 從樣本效率與收斂速度角度 , ATE 在 70k 步即可超過傳統(tǒng) RDT 的 90k 步效果 , 說明 ATE 框架的對齊 — 引導(dǎo)機(jī)制 , 不僅提高任務(wù)成功率 , 也顯著提升了任務(wù)成功率 。
為了驗證模型的跨本體泛化能力 , 我們自行搭建了雙臂睿爾曼實驗環(huán)境 , 該實驗平臺從未在預(yù)訓(xùn)練數(shù)據(jù)中出現(xiàn)過 , 且雙臂的動作空間和預(yù)訓(xùn)練數(shù)據(jù)有明顯不同 。 進(jìn)而 , 構(gòu)建了多個分鐘級長序雙臂協(xié)同操作任務(wù) , 包括制作三明治、蒸包子等復(fù)雜協(xié)作任務(wù) , 以及制作酸奶、烤面包等工具使用類任務(wù) 。 通過采集少量真機(jī)數(shù)據(jù)進(jìn)行后訓(xùn)練 , ATE 算法能夠?qū)⒒?RDT 和 Pi-0 等 VLA 模型快速適配到目標(biāo)本體上 。 上圖呈現(xiàn)了四個真機(jī)任務(wù)在不同訓(xùn)練步數(shù)的成功率與整體平均 , 展示了在有限數(shù)據(jù)與分鐘級長程任務(wù)下 ATE 框架的性能 。 可見在需要雙臂協(xié)同、時序規(guī)劃與多階段配合的任務(wù)上 , 在統(tǒng)一的潛空間引導(dǎo)下 ATE 框架能使模型更快地收斂到目標(biāo)域動作分布 。
上圖可視化了空間泛化(初始位姿隨機(jī)偏移)、視覺干擾(放置未見過的雜物 , 如水果)、人為擾動(在關(guān)鍵點迫使策略重試) 。 ATE 框架在未見的光照、雜物干擾、空間偏移與外部干預(yù)下仍能維持任務(wù)相關(guān)注意與恢復(fù)能力 。
研究總結(jié)
在 VLA 基座模型尚不具備直接泛化能力的情況下 , TeleAI 提出的跨本體 ATE 后訓(xùn)練框架為數(shù)據(jù)稀缺與跨本體泛化后訓(xùn)練難題提供了可行答案 。 面對數(shù)據(jù)預(yù)算、訓(xùn)練窗口與算力上限的三重約束 , 無需寄望于數(shù)據(jù)堆疊或昂貴的全參重訓(xùn) , 而是以最小工程代價引入潛空間對齊與分布引導(dǎo) , 實現(xiàn)快速、穩(wěn)健的跨本體泛化適配 。 換言之 , ATE 框架可以作為一個即插即用的模塊 , 成為兼容各種主流 VLA 模型的后訓(xùn)練階段的對齊引導(dǎo)方案 , 用于提升后訓(xùn)練的跨本體泛化能力 , 成為破解數(shù)據(jù)與訓(xùn)練瓶頸的實踐路徑 。
【具身VLA后訓(xùn)練:TeleAI提出潛空間引導(dǎo)的VLA跨本體泛化方法】作者簡介:本文由 TeleAI 三名研究實習(xí)生:清華大學(xué)博士生張揚(yáng)、港中文碩士生王陳煒、西工大碩士生陸歐陽作為共同第一作者 , 成果由 TeleAI 聯(lián)合清華大學(xué)、港中文、西工大合作完成 , 本文通訊作者為 TeleAI 具身智能團(tuán)隊負(fù)責(zé)人白辰甲博士和 TeleAI 院長 。
推薦閱讀















- 既要性能又要影像?2025國補(bǔ)后這3款旗艦,能穩(wěn)用五年
- 開放全棧!超越π0,具身智能基礎(chǔ)大模型迎來真·開源,開發(fā)者狂喜
- 對話聯(lián)想德國業(yè)務(wù)負(fù)責(zé)人:一年月200億營收背后的生意經(jīng)
- 奧特曼一席話,劍橋小哥當(dāng)場撕毀合約轉(zhuǎn)AI!附00后44萬AI崗面經(jīng)
- 國補(bǔ)后1699元,驍龍8Gen3+8T直屏+6400mAh,一加旗艦更親民了
- Nano Banana爆火之后,一個神秘的「胡蘿卜」代碼模型又上線了
- 00后1.1億美金掀桌!硅谷AI將書寫影視新傳奇,終結(jié)制片舊時代
- 華為Mate80震撼亮相:設(shè)計拉滿,看完后我很欣慰
- 全球芯片格局正在分裂,兩種模式背后是一場生死競速,誰更適應(yīng)未來?
- 國外投行最新報告:中國光刻機(jī)落后20年,西方依然遙遙領(lǐng)先!