文章圖片

文章圖片
文章圖片
機器之心原創
作者:冷貓
好玩好用的明星視頻生成產品再更新 , 用戶操作基礎 , 模型技術就不基礎 。
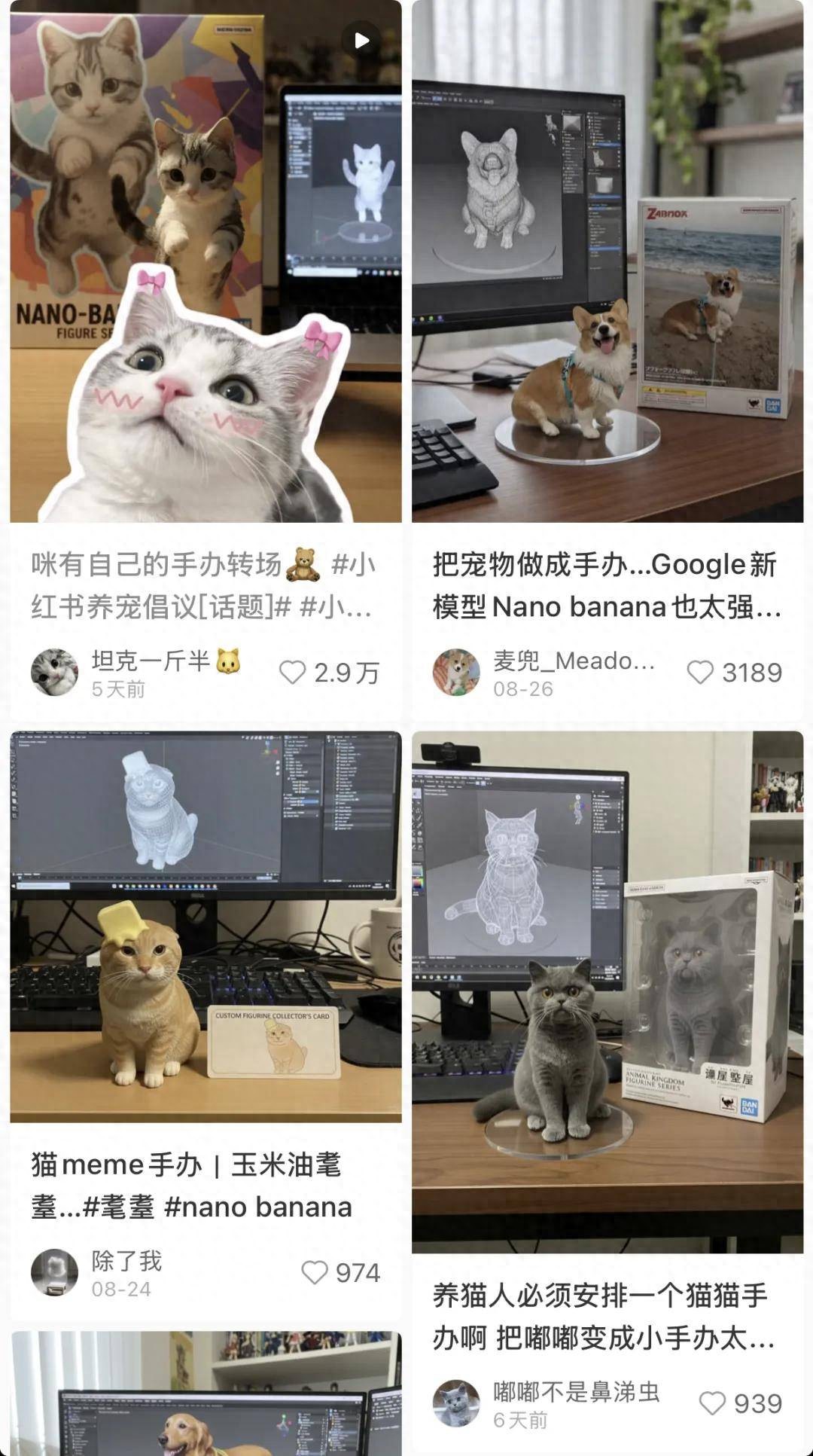
熟悉生成領域的讀者們最近都被谷歌的一只納米香蕉 nano-banana 刷了屏 。
在圖像生成領域 , 納米香蕉在短期內獲得了巨量的影響力 , 憑著「照片變手辦」的超高真實感的創意玩法橫掃整個社交媒體 , 尤其觸動了毛孩子家長們的心 。
在優秀的模型實力基本盤外 , 真正做到出圈的核心要素還得是「創意」 。
把自家寵物變成可愛手辦的創意玩法的徹底出圈 , 讓更多普通用戶意識到 AI 生成讓想象落地的能力 , 「這個好酷 , 我也想要」的心理觸發了全民 AI 創作的裂變 。
不過 , 說到在 AI 視頻中玩創意 , 老玩家 PixVerse(拍我 AI)上周五開始在國內開啟免費開放周 , 兩天內有創作者在小紅書、短視頻平臺上玩 Nano banana 3D 手辦 , 也有創作者用 Nano banana 生圖和拍我 AI 模板結合 , 玩衣柜變裝 , 獲得視頻號超 5000 點贊量 。
在兩年前 , Sora 甚至還沒有概念發布的時候 , PixVerse 就已經上線了網頁端產品 , 上線 30 天內就實現了百萬訪問量 。
如此元老級的視頻生成玩家 , 在「創意」上是認真的 。 過去那些火遍全網的神奇 AI 特效模板 , 都出自 PixVerse 之手 。
在今年 6 月 , 國內版本的產品「拍我 AI」正式上線 , 并搭載了當時最新的 PixVerse V4.5 底模 , 將長期霸榜視頻生成應用榜的工具提供給期待已久的國內用戶 。
當時 , 我們就做了一手全方位的體驗 , 非常驚艷 , 一整個六邊形戰士 。
「讓普通人感覺好玩 , 讓創作者感覺好用」是拍我 AI 最貼切的標簽 。
如果你是普通用戶 , 首頁中令人眼花繚亂的當下熱門 AI 視頻模板足夠用來整活 , 越玩越上頭;如果你是進階創作者 , 文生視頻、圖生視頻、首尾幀、多主體、視頻續寫等創作工具應有盡有 , 完美支持天馬行空的創作思路 。 更值得一提的是 , PixVerse(拍我 AI)早于 veo3 就推出了音頻音效和對口型等音頻相關的創作功能 , 實現了視頻創作的全流程閉環 。
PixVerse(拍我 AI)至 9 月 10 日期間生成任意視頻不消耗積分 , 大家可以趁機隨意嘗試爆款短視頻的創作 , 產生更多火爆的創意 , 進一步增進國內的AI視頻創作熱情 。
其發布的最新的 Agent 創作助手功能 , 不再只是提供「模板」 , 而是像一個隨身的 AI 導演:用戶只需選擇喜歡的模板并上傳一張圖片 , Agent 即可自動識別其特征 , 生成一段 5–30 秒的完整短片 。 智能體功能不僅覆蓋了目前網絡上爆火的特效和創意視頻 , 而且將用戶從繁雜的 Prompt 設計工作中解放 , 讓更多普通人加入到 AI 創作中來 。
「照片變手辦」也不再是納米香蕉的標簽 , 我們用這只網紅哈基米的圖像做了智能體創作:PixVerse(拍我 AI)不僅生成了高質量的手辦尾幀圖 , 還生成了一個炫酷的轉場動畫 。
當然 , 擁有這么多有意思的玩法的平臺早已受到海量用戶的認可 。 不久前 , PixVerse(拍我 AI)的全球用戶數已躍升至破億的規模 。
要想在全球范圍內獲得上億用戶的認可 , 能夠承接上億用戶的創作靈感 , PixVerse(拍我 AI)背后的公司 —— 愛詩科技 —— 一定在技術創新上做對了些什么 。
圖生視頻榜首 PixVerse V5 , 更全面的六邊形戰士
8 月 27 日 , 愛詩科技發布新一代自研視頻生成大模型 PixVerse V5 。
PixVerse V4.5 已經是一個六邊形戰士了 , 誰曾想 PixVerse V5 又一次把六邊形硬生生擴大了一圈 。
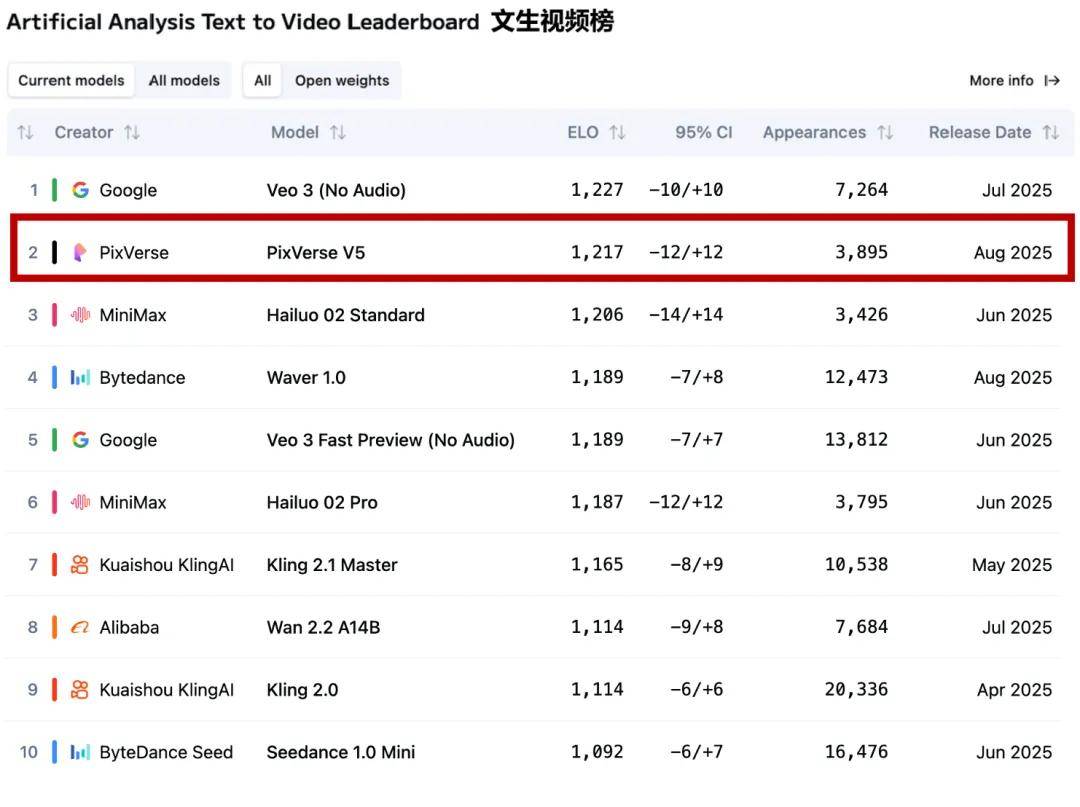
根據權威獨立測評平臺 Artificial Analysis 最新測試結果 , PixVerse V5 在圖生視頻(Image to Video)項目中排名全球第一 , 在文生視頻(Text to Video)項目中位列同樣位居第二 , 在視頻生成賽道的最前列 。
PixVerse V5 的核心優勢在三大方向:
智能理解:一句話生成精準視頻 , 指令響應更準確 , 生成一致性和穩定性大幅提升 , 創意表達更自由高效 。 極速生成:視頻生成速度保持在「分鐘級」提升至「秒級」的準實時生成 , 最快 5 秒即可生成一段高質量短片 , 1 分鐘生成 1080P 高清視頻 。 更逼真自然:通過擴大模型參數規模和高質量訓練數據 , 顯著提升審美、復雜動作、運動幅度和光影的還原能力 , 讓 AI 視頻生成更接近真實拍攝 。令人驚喜的是 PixVerse V5 的更新并沒有強調在某一個特定場景的能力提升 。 準確的說 , PixVerse V5 版本是對前一代底模的全方位進化 。 從技術革新的角度 , 我們來詳細探究一下這三大方向上 , 愛詩科技是怎么走在時代前沿的 。
統一特征空間 , 指令沒有溝通障礙
從用戶角度而言 , 一個「好用」的生成模型 , 首先得聽得懂訴求 。 當用戶和模型之間有溝通障礙時 , 生成質量再高的模型也很難實現用戶的目標 , 更難以稱得上好用 。
就比如下面這個案例:
某國內頭部產品模型生成的:「萊特兄弟的雙翼飛機進化到噴氣客機」
拍我 AI 生成的:「萊特兄弟的雙翼飛機進化到噴氣客機」
越是簡單模糊的文本指令 , 越是考驗模型對文本、圖像、視頻多模態數據的理解能力 。 愛詩科技顯然在多模態大模型領域有著深刻的積累 。
我們知道 , VLM 多模態大模型 , 能夠同時處理和理解圖像和文本數據 。 以前的模型大多是「單模態」的:比如卷積神經網絡只能看圖 , 語言模型只能看文字 。 而 VLM 能同時理解圖像和文本 , 并且把兩者關聯起來 , 處理更加復雜的任務 。 而在視頻大模型中 , 視頻相比于圖像增添了時間維度 , 語義信息更豐富 , 更復雜 。
PixVerse(拍我 AI)將不同模態數據映射到同一語義體系 , 讓不同模態的數據能夠在同一個語義體系下對齊和交流 , 在 VLM 的體系下彌合了用戶指令和生成視頻之間的語義鴻溝 。
除了語義理解外 , 目前在視頻生成領域的最大痛點在于視頻生成的速度普遍不及預期 , 并且模型要實現高質量和長序列的視頻生成 , 對訓練數據和訓練資源的需求是巨大的 。
愛詩科技在這兩大傳統痛點上持續發力 , 奠定了在視頻生成領域堅實的技術優勢 。
擴散極致蒸餾 , 幾秒完成生成的準即時魔法
用過 Sora 生成過視頻的朋友們都應該很有感觸 , 從指令輸入到成片出現至少也要以數分鐘計算 。 一個慢速的生成模型非常干擾用戶的創作思路 , 非常影響使用體驗 , 更別提連續創作了 。
而生成速度這部分 , 是 PixVerse(拍我 AI)的傳統強項 , 也是其獲得全球海量 AI 創作用戶青睞的核心競爭力 。
愛詩科技是業界第一個把視頻生成做到 5 秒之內的 AI 初創團隊 。
在 PixVerse V4.5 的時候我們就實測過 , 即使我們將各項生成指標拉滿 , 平臺輸出結果的時間也沒有超過 1 分鐘 。
對于用戶來說 , 如此短暫等待能夠成為「準即時」生成 , 完全不給使用帶來負面影響 。
為了實現超高速的視頻生成 , 愛詩科技對視頻擴散模型進行了大刀闊斧的改進 , 采用了「分數匹配蒸餾」的方式 , 將視頻擴散生成過程從幾十步壓縮至極少數步驟 , 極大的提高了模型的生成速度 。
分數匹配蒸餾是一個擴散模型體系下 , 將擴散模型轉換為一步生成 , 極大地加快了生成速度并保持質量的代表性方法 。 最初 , 該方法在圖像生成領域使用 。 在視頻生成領域 , 該方法具有很大的應用潛能 。
據愛詩科技技術團隊介紹 , PixVerse V5 不僅采用了分布匹配損失優化模型采樣軌跡提速生成 , 為了保證視頻生成的質量 , 他們還結合了特征自約束損失 , 讓模型實現自我監督 , 以此穩定畫面質量 , 實現了生成速度和生成質量之間完美的平衡 。
自研生成架構 , 突破創造力上限的驅動力
決定了 PixVerse(拍我 AI)產品能力的核心是底模 , 決定了底模能力上限的是高質量的模型架構 。
愛詩科技全面采用自研的視頻生成模型 , 采用 DiT 架構 , 在模型結構設計、訓練策略等方向上進行了充分的創新工作 , 能夠充分激發 DiT 架構模型的生成潛力 。
為了滿足讀者對領先的模型的技術細節的好奇心 , 機器之心特意向愛詩科技的技術團隊了解了一些他們在自研 DiT 模型的架構創新和技術細節 。
簡而言之 , DiT 模型將 VAE 框架之下擴散去噪中的卷積架構換成了 Transformer 架構 , 結合了視覺 transformer 和擴散模型的優點 , 利用全局注意力機制 , 具備可擴展性強 , 多模態擴展 , 生成質量高的優勢 。
DiT 基本模型架構圖 , 來自論文《Scalable Diffusion Models with Transformers》
DiT 雖然效果好 , 但是對訓練的算力要求很高 , 需要有好的模型設計以及好的模型訓練策略 , 才能實現高質量的生成 。 尤其是在視頻生成領域 , 要采用 DiT 模型進行高質量視頻生成則更為復雜 , 需要在模型架構中添加時間維度 。 正所謂牽一發而動全身 , 視頻生成 DiT 模型在算力需求、數據需求、分辨率兼容等多個問題上都面臨著不小的挑戰 。
【全球圖生視頻榜單第一,愛詩科技PixVerse V5改變一億用戶視頻創作】愛詩科技的技術團隊向我們透露 , PixVerse V5 在模型結構設計上有兩大亮點:
Tokenizer 方面:我們正在訓練專用于視頻與圖像生成的 Tokenizer , 在保持較高壓縮比的同時 , 依然能夠保證出色的重建質量與生成效果 。 自適應 Attention 結構(FullAttn + SparseAttn):通過在計算量與注意力精度之間動態平衡 , 不僅能有效降低整體計算開銷 , 還能在推理速度幾乎不受影響的前提下 , 為模型提供更大的規模擴展(ScaleUp)空間 , 并顯著提升其擬合能力 。眾所周知 , 視頻數據相比于文本和圖像數據更為復雜和龐大 , 數據包含的信息量更大且更難以提取 , 給模型訓練提出了巨大的難題 。
為了模型能夠有效學習數據集中的信息 , 快速實現模型收斂 , 實現模型性能提升 , 愛詩科技在模型訓練策略上下了很大功夫 , PixVerse V5 在多模態訓練策略上有四大創新優勢:
多模態統一表征:將文本、圖像、視頻等模態映射至同一語義空間 , 顯著提升模型的理解與生成精度 , 并加速整體收斂過程 。 自適應加噪去噪:在訓練過程中動態調整噪聲水平 , 并結合任務難度相關的損失加權機制 , 在不同信噪比條件下有效加速模型收斂 。 漸進式訓練策略:采用「由簡入繁」的訓練路徑 , 先進行圖像任務學習 , 再逐步擴展至圖像 + 視頻的聯合訓練;在聯合訓練中 , 從低時長到高時長、低分辨率到高分辨率逐步遞進 , 保證穩定收斂與性能提升 。 原生動態分辨率支持:模型能夠直接處理不同分辨率的圖像與視頻 , 無需額外的 resize 或 crop 操作;結合原生動態分辨率與絕對時間編碼機制 , 使其具備處理多尺度圖像及長時序視頻的能力 。另外 , 愛詩科技團隊透露 , 他們擁有領先的海量圖像和視頻數據 , 和高質量、高精準的精選數據 , 不僅能夠為模型預訓練提供了無限可能的數據分布 , 也在監督訓練微調(SFT)階段更上一層臺階 。
這些硬核的技術革新驅動著 PixVerse 模型的不斷進化 , 支撐著用戶生成動作自然、光影真實、物理規律準確的創意視頻 , 也是滿足廣告、電商、影視、教育、游戲等場景的高標準要求的核心基本盤 。
過去 , 在視頻生成的研究探索階段 , 我們一般都在討論一些最基本的生成邏輯 , 包括物理效果 , 光影效果 , 動作的合理性等等 。
隨著技術的不斷迭代 , 視頻生成已經進入了投入實際應用的新階段 , 而現在我們討論的更多的是生成視頻的創意和美學范疇了 。 隨著 PixVerse V4.5 對各種趣味創意、光影藝術的創作、鏡頭語言的理解方面的功能實現 , 我們自然希望 PixVerse V5 在美學上能夠有一些新的理解 。
愛詩科技在模型中利用高質量視頻數據和人類偏好標注 , 結合強化學習后訓練(RLHF) , 提升了文本 - 視頻對齊精度、動作自然度和美學評分 。
超可愛的小貓咪舔爪爪 , 毛茸茸的小窩和字體設計 , PixVerse V5 真的很懂可可愛愛的心頭好 。
將人類的審美喜好加入到大模型訓練中 , 讓 AI 更懂人心 , 更懂審美 , 為打開模型生成的上限 , 投入 AI 藝術創作奠定了堅實的基礎 。
疾速成長 , 領跑視頻生成馬拉松
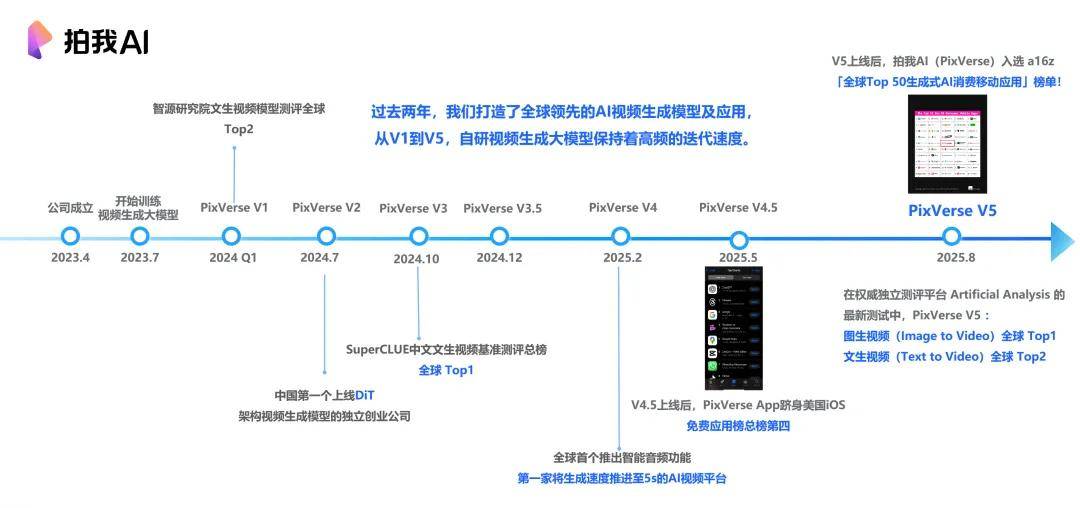
愛詩科技模型發展歷程
從 2023 年 7 月開始 , 愛詩科技訓練視頻生成大模型 , 到 2025 年 8 月底發布 PixVerse V5 模型 , 僅有短短的兩年時間 。
在這兩年期間 , 每隔數個月就能有一次模型的迭代 , 成長非常迅速 。 直到 2024 年底 , 愛詩科技發布 PixVerse App 產品 , 創下了全球最快的高質量視頻生成的模型紀錄 , 真正進入應用階段 。
從 V3 一直到 V5 , 生成速度從 10 秒進化到 5 秒準實時 , 視頻生成進入了有聲時代 , 鏡頭語言、多主體、智能體等里程碑式功能接連上線 , 這一切支撐著 PixVerse(拍我 AI)成為了全球用戶量最大的視頻生成平臺 。
AI 視頻生成是一場沒有終點的馬拉松 , 只有保持高速的技術迭代、不斷刷新模型的邊界 , 才能始終引領行業向前 。
愛詩科技創始人兼 CEO 王長虎博士在 2025 北京智源大會上表示:「視頻是最貼近用戶的內容形態 。 一旦視頻生成技術能夠落地 , 它的產品化和商業化潛力可能不亞于大語言模型 。 」
「去年 2024 年 10 月 , 我們的 PixVerse V3 上線 , 這是第一次真正讓普通用戶、普通消費者用 AI 能力創造出過去無法創造出來的視頻 。 在我心中 , 這一刻才是視頻生成的『GPT 時刻』 。 」
愛詩科技所秉持的愿景與技術理念 , 正是要在這條漫長而激烈的賽道上 , 持續釋放視頻這一最貼近用戶的內容形態的潛能 , 讓創造的能力真正走向每個普通人 。
文中視頻鏈接:https://mp.weixin.qq.com/s/Sk5lEfj-1R5zhV6tNVPI2A
推薦閱讀













- 設計完全逆華為!全球首款安卓三折疊屏亮相:配置非常兇猛!
- 中國芯崛起!只差2.2%,中芯就要超三星成全球第二了
- “奧運級”科技實力獲全球認證!TCL實業榮獲三項IFA2025大獎
- IDC報告:全球清潔機器人市場增速預估28.2%,石頭科技半場領先
- 海信攜新品閃耀 IFA ,以硬核黑科技定義全球顯示新標桿
- 聚焦IFA 2025:創維尖端電視技術凸顯中國智造全球競爭力
- 中國牢牢控制供應鏈 人形機器人有望主導全球
- 影石攜首款全景無人機亮相IFA 2025 引領全球影像技術變革
- 華為首次超越三星,2025上半年全球折疊手機出貨量排名第一
- 聯想三高管IFA2025深度對話:AI如何重構PC形態與全球化品牌矩陣