
文章圖片
文章圖片
文章圖片
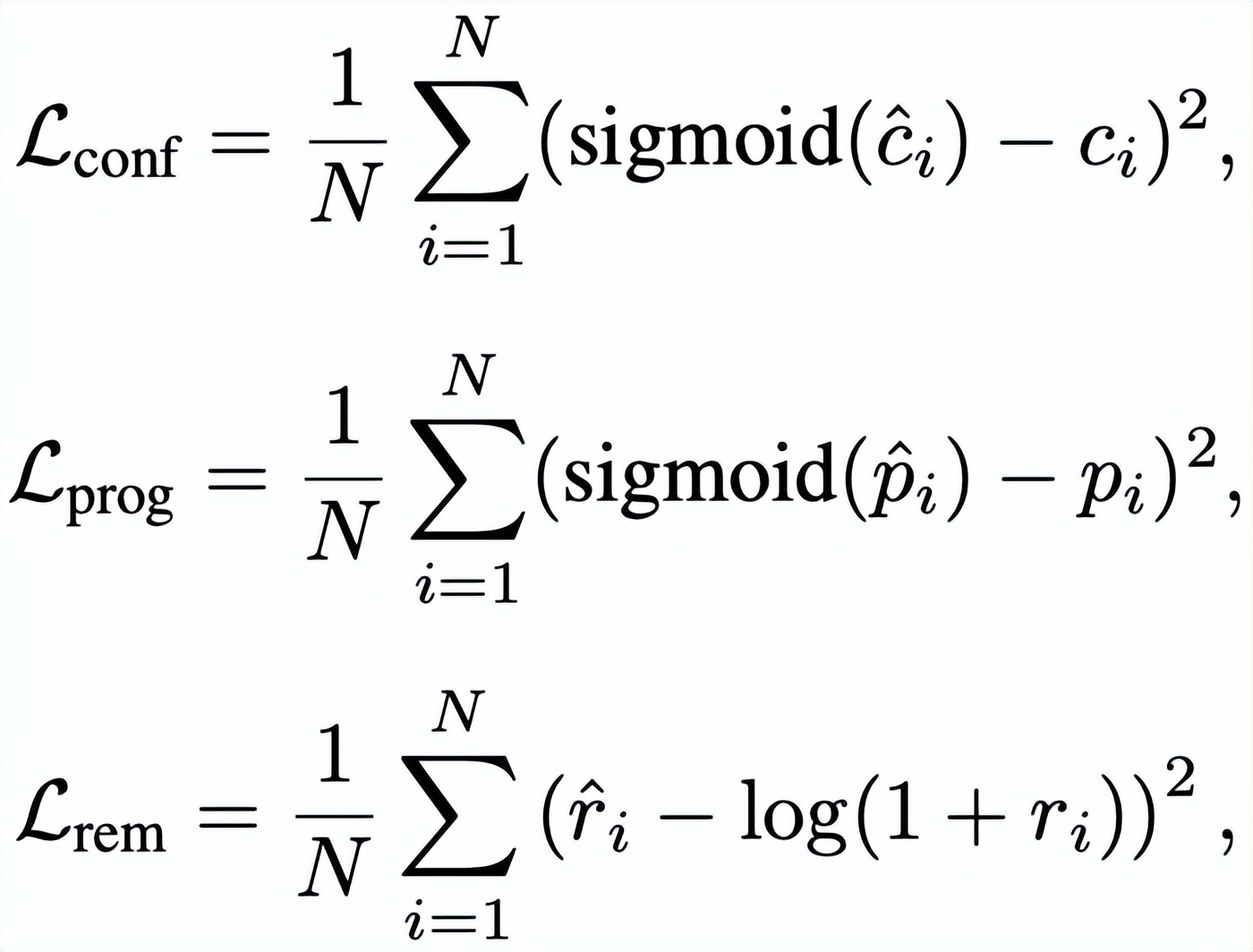
文章圖片
文章圖片
文章圖片
以 DeepSeek-R1 等為代表的推理模型(Large Reasoning Models LRMs) , 通過生成更長的思維鏈 , 在各類復雜任務中取得了更優的表現 。 但長思維鏈是推理模型的 “雙刃劍” , 雖能提升性能 , 但 “過度思考” 帶來的語義冗余會大幅推高推理成本 。
為破解大模型長思維鏈的效率難題 , 并且為了更好的端到端加速落地 , 我們將思考早停與投機采樣無縫融合 , 提出了 SpecExit 方法 , 利用輕量級草稿模型預測 “退出信號” , 在避免額外探測開銷的同時將思維鏈長度縮短 66% , vLLM 上推理端到端加速 2.5 倍 。
論文:https://arxiv.org/abs/2509.24248 開源代碼:https://github.com/Tencent/AngelSlim
1.“思考早停” 的挑戰
目前對 LRMs 思維鏈壓縮的相關研究大致可以分為兩類 , 一類是基于訓練的方法 , 另一類是 Training-Free 的方法 , 它們都有各自的局限性:
(1)基于訓練的方法 , 通過標注數據進行有監督微調 , 或通過強化學習減少思維鏈長度 。 盡管壓縮效果顯著 , 但往往伴隨高昂的訓練成本 , 并導致模型輸出分布被改變 , 引發模型可靠性及性能上的擔憂 。
(2)Training-Free 的方法 , 無需高昂的訓練開銷 , 通過介入模型的長思考過程 , 監控模型的 Logits 或其他輸出信號 , 來判斷當前思考長度下 , 能否提前終止推理 。 這類方法表明 , 通過提前停止可以在不降低準確率的前提下縮短推理長度 , 但其依賴探測機制會帶來額外計算開銷 , 并且往往更關注詞元數量的減少 , 而非真正的端到端推理時延優化 。
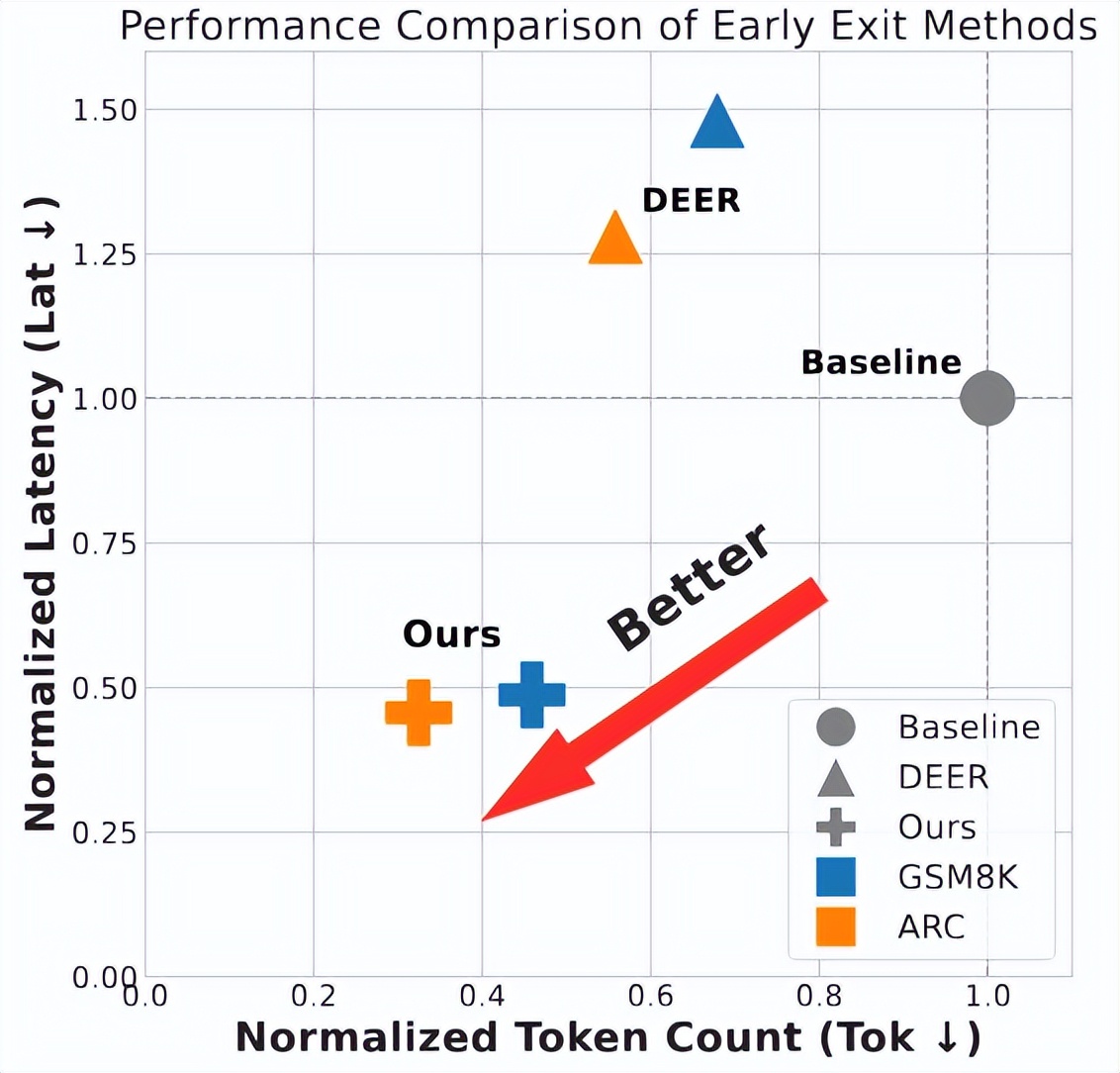
圖 1 SpecExit 實現端到端加速
圖 2 從模型隱藏狀態中學習到的推理進度信號
針對以上的問題 , 我們發現了投機采樣的天然優勢 , 既能保證模型輸出的一致性 , 又能從草稿模型隱藏狀態中提取推理進程信號 , 基于此思路我們提出了 SpecExit 框架 。 如圖 2 所示 , 模型的隱藏狀態中天然蘊含了例如置信度、推理進度和剩余推理長度等信號 , SpecExit 通過將這些信號與投機采樣結合 , 在不引入額外探測開銷的前提下 , 實現動態、可靠的思考早停 。 并且如圖 1 所示 , 相比于基線和 DEER 等方法 , SpecExit 在 vLLM 上端到端加速 2 倍以上 , 準確性和推理效率得到雙重保障 。
2.SpecExit 方法創新
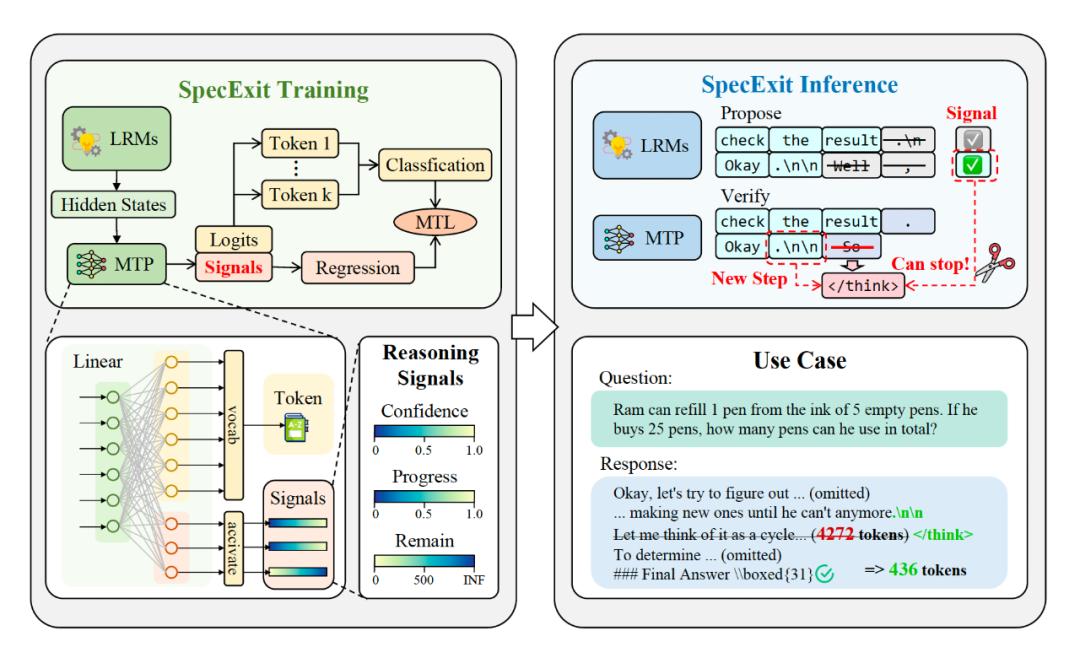
大模型中多詞元預測(Multi-Token Prediction MTP)的隱藏狀態可以預測未來 N 個位置的詞元 , 這表明隱藏狀態中蘊含了豐富的信息 。 受 MTP 的啟發 , SpecExit 的目標是:同時從隱藏狀態中學習表征推理狀態的「信號」及未來 N 個詞元 , 在保留 MTP 原有加速能力的基礎上 , 引導思考過程提前終止 , 進一步提升推理效率 。 SpecExit 整體框架如圖 3 所示 , 僅需對 MTP 的隱藏層進行低成本的擴展 , 即可高效加速并壓縮推理模型的思維鏈 。
圖 3 SpecExit 方法架構總覽
2.1 SpecExit 訓練流程
(1)數據構建:我們首先獲取基礎模型生成的完整輸出 , 并提取位于think和/think詞元之間的推理內容 。 為了識別有效的推理軌跡 , 我們迭代嘗試在段落結束位置插入推理結束詞元/think , 并驗證生成的最終答案是否與原始輸出匹配 。 如果答案保持一致 , 則后續的推理內容被視為冗余 。 因此 , 僅保留產生正確答案所需的最小推理片段作為訓練數據 。
(2)信號標注:置信度 Confidence 定義為預測步驟中概率的幾何平均數 , 反映生成的可靠性;剩余推理長度 Remain 定義為從當前詞元位置到最早有效/think插入點的剩余詞元數量 , 量化推理的剩余工作量;推理進度 Progress 表示為從 0 到 1 的歸一化值 , 捕捉思維鏈的相對進度 。
(3)信號回歸:我們提出了一種簡便高效的擴展方法 , 通過在 MTP 模塊的線性投影層中引入少量額外維度來回歸推理信號 。 這些維度與詞元分類權重正交 , 確保信號回歸不會干擾推測解碼訓練的收斂 。 多任務學習(Multi-Task Learning MTL)將詞元分類損失和信號回歸損失聯合優化 , 整體訓練目標如下:
其中 , 詞元分類預測使用標準交叉熵損失 , 置信度和推理進度使用均方誤差(Mean Squared Error MSE) , 剩余推理長度使用均方對數誤差(Mean Squared Logarithmic Error MSLE) , λc、λp、λr 表示動態權重系數 。 置信度、推理進度、剩余推理長度三個信號量的損失函數公式如下:
由于信號回歸損失的收斂速度比詞元分類損失更快 , 我們采用基于梯度的動態權重策略來平衡不同任務的貢獻 。 該機制為梯度幅度較小的任務分配更高權重 , 防止梯度較大的任務主導學習過程 , 從而確保所有任務都能得到有效優化 , 訓練損失收斂曲線如圖 4 所示 。
圖 4 訓練 Loss 收斂曲線
圖 5 信號引導的投機采樣思考早停 Inference 過程
2.2 SpecExit 在 vLLM 推理流程
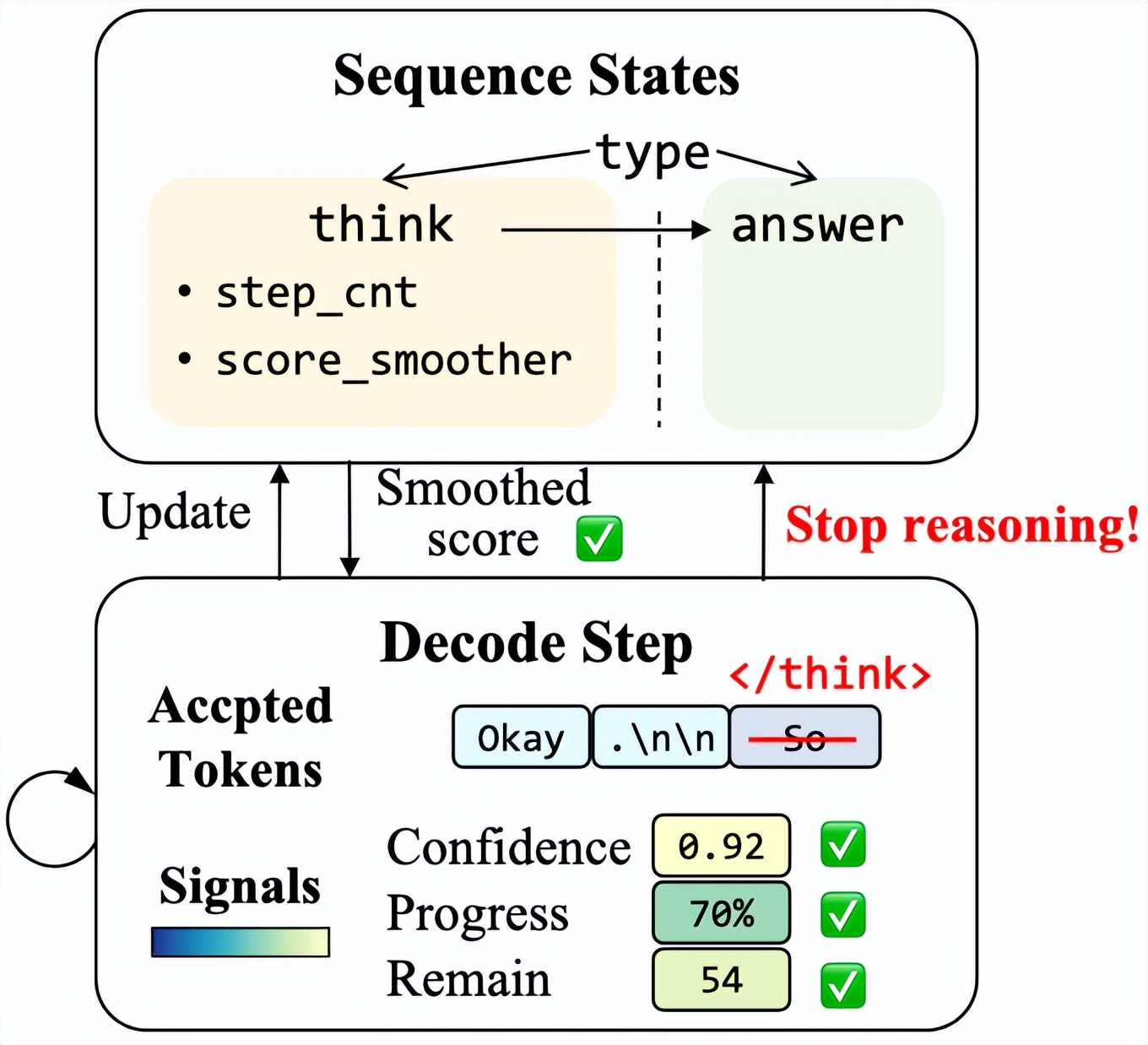
我們基于投機采樣框架構建了思考早停機制 , 其中草稿模型首先產出一系列候選詞元 , 隨后由目標模型并行驗證 。 特別的 , 在目標模型驗證流程中 , 除了計算下一個詞元的 Logits 外 , 還計算最后一個被接受詞元對應的最終隱藏狀態 。 如圖 6 所示 , 該表征通過草稿模型的輕量級線性層處理后 , 額外生成置信度分數、推理進度以及剩余推理長度三個信號的預測值 。
原始信號存在一定的波動性 , 可能導致過早或不穩定的思考早停 。 因此 SpecExit 采用指數加權移動平均(Exponentially Weighted Moving Average EWMA)方法對信號進行平滑處理 。 在每次 Decoding 中 , 平滑值更新為當前信號與先前平滑值的加權平均 , 確保了思考早停在持續解碼階段的高魯棒性 。
圖 6 SpecExit 思維鏈壓縮示例
同時 , 為確保思考早停的決策發生在語義連貫的邊界處 , 我們引入了一類稱為步驟分割詞元的特殊標識符 , 用于指示生成文本中的自然分段點 。 具體而言 , 步驟分割詞元可分為兩類:
(1)段落分隔符(如.\\) , 標記段落或推理單元的結束;
(2)語義上的句子間邏輯連接詞(如 \"But\"、\"So\" 或 \"Therefore\") , 常在推理過程中標示語義轉換或邏輯轉折 。
【騰訊發布SpecExit算法,無損壓縮端到端加速2.5倍!】
由于基于段落分隔符的分割策略更具普適性 , 我們的實驗默認采用該策略 。 當采樣到的詞元屬于上述集合時 , 且預測的信號超過預設閾值 , 則判定推理過程已充分 。 此時 , SpecExit 會在當前分割詞元位置截斷已接受的草稿詞元 , 并將目標模型的最新詞元替換為/think , 從而確保終止點位于自然邊界的同時保持生成文本的連貫性 。 并且 SpecExit 在 vLLM 框架上已端到端支持 , 在實踐應用上可以很便捷的集成 。
3. 實驗結果
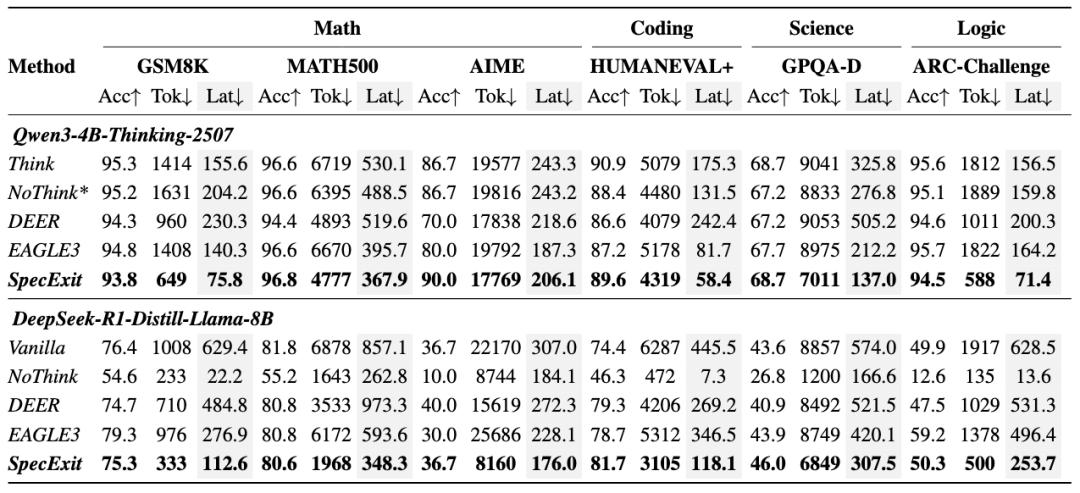
我們在數學、科學、編程和邏輯基準測試上對 SpecExit 方法進行了評估 , 如表 1 實驗結果顯示 , SpecExit 顯著縮短了推理過程 。 在 Qwen3-4B-Thinking-2507 模型上 , GSM8K 和 ARC-Challenge 的數據集推理長度分別減少了 54% 和 53%;在 DeepSeek-R1-Distill-Llama-8B 模型上 , 推理長度分別減少了 66% 和 64% 。 推理長度大幅縮短的同時 , SpecExit 基本無額外探測開銷 , 所以 vLLM 上端到端加速提升顯著 , 例如在 GSM8K 數據集上 , 與投機采用基線 EAGLE3 相比 , SpecExit 在兩個模型上分別實現了 1.9 倍和 2.5 倍的加速比 。 與此同時 , SpecExit 在各基準測試上 Acc 基本無損 。
表 1 SpecExit 評估與性能測試 , Acc 表示精度 , Tok 表示輸出詞元數量 , Lat 表示端到端時延
與此相比 , 其他思考早停方法雖然也可以減少輸出長度 , 但延遲增益很有限 , 甚至在某些數據集上 , 額外的計算開銷反而導致推理速度變慢 。 而 SpecExit 不僅縮短思考長度 , 而且推理時延加速非常明顯 , 在實際應用中更加實用 。
對于思考停止信號的選擇 , 我們進行了融合信號與分別單獨使用置信度 Confidence、推理進度 Progress、剩余推理長度 Remain 的消融實驗 。 實驗結果如圖 7 所示 , 融合多種信號的策略能夠在減少輸出長度和維持精度表現之間做到更好的平衡 。
圖 7 信號類型消融實驗
4. 總結
SpecExit 結合投機采樣 , 在不影響準確性的前提下在 vLLM 上實現最高達 2.5 倍的端到端推理速度提升 , 是 LRMs 實踐落地的非常有效的加速算法 。 正是利用了投機采樣的草稿模型 , SpecExit 能在解碼過程中同時預測未來詞元和思考早停信號 , 不會增加額外的探測開銷 , 與其他方法相比有更多的性能優勢 , 在實踐落地非常實用 。
在多樣化任務和模型上的實驗表明 , SpecExit 泛化能力非常好 , 并且該方法揭示了隱藏狀態作為高效推理信息信號的潛力 , 也將為繼續深入發掘隱藏狀態作用的后續研究工作提供很大的借鑒意義 。 歡迎關注我們的 SpecExit 方法 。
推薦閱讀











- 百度百科攜手《大學科普》、中國科學院大學科協發布科普專刊,面向全國高校發行
- HarmonyOS 6正式發布并開啟規模公測 鴻蒙生態邁入“好用”新階段
- REDMI又來掀桌子!旗下首款Mini LED電視發布:殺到4799元
- 紅米K90系列已正式發布:對比紅米K80系列,到底有多大提升?
- 紅米K90系列發布,2599元起售,Redmi沖高正式邁入4000元檔紀元!
- 復旦NLP&美團LongCat重磅發布LRMs能力邊界探測新范式
- 昨天剛發布,今天就降價,剛買紅米K90的用戶看呆了
- 騰訊ima2.0發布,一句話搜索上百萬知識庫、2億份知識文件
- REDMI K90發布:Bose加持、潛望長焦,價格比小米17還香!
- REDMI Watch 6智能手表發布:24天長續航,售價599元