
文章圖片
文章圖片
文章圖片
文章圖片
文章圖片
我們都知道 LLM 中存在結構化稀疏性 , 但其底層機制一直缺乏統一的理論解釋 。 為什么模型越深 , 稀疏性越明顯?為什么會出現所謂的「檢索頭」和「檢索層」?
我們非常榮幸地宣布 , 我們試圖回答這些問題的論文 UNCOMP 已被 EMNLP 2025 主會接收!我們不僅提出了一個高效的推理框架 , 更重要的是 , 我們提供了一個全新的理論視角來理解 LLM 內部的信息動態 。
【跨層壓縮隱藏狀態同時加速TTFT和壓縮KV cache!】
論文標題:UNComp: Can Matrix Entropy Uncover Sparsity? -- A Compressor Design from an Uncertainty-Aware Perspective 論文地址:https://arxiv.org/abs/2410.03090 GitHub:https://github.com/menik1126/UNComp
核心洞察:
一個關于熵的悖論與新解
傳統的矩陣熵 (Matrix Entropy) 分析存在一個悖論:它顯示信息熵隨著層數加深是逐層增加的 。 這與我們觀察到的「模型越深越稀疏」的現象相矛盾 。 如果信息在不斷累積 , 又何來稀疏一說?
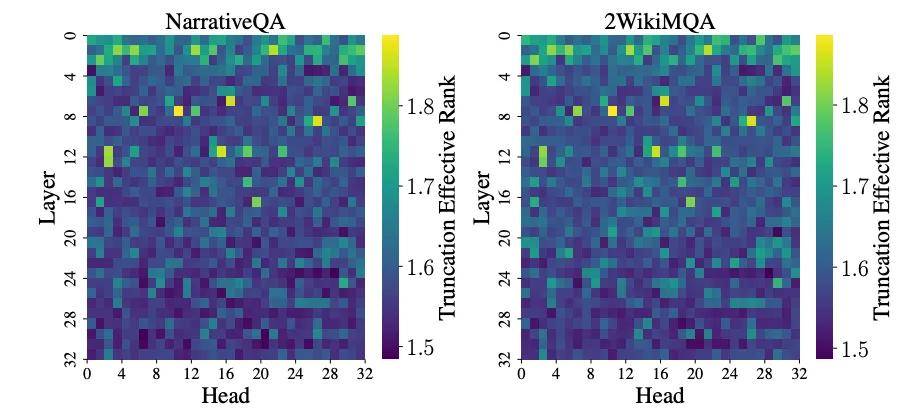
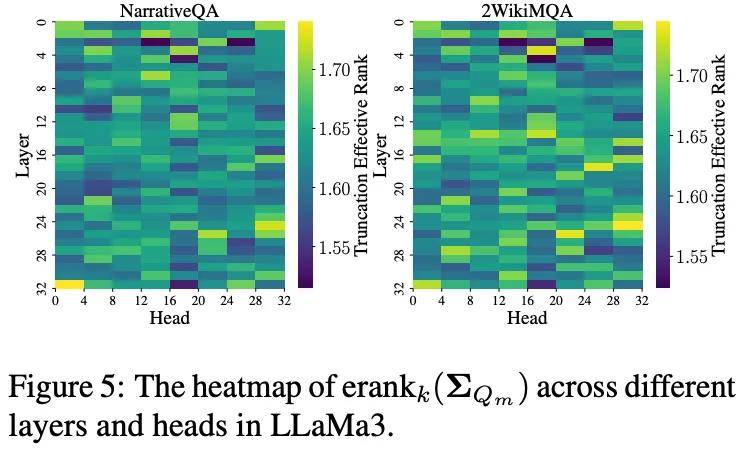
我們的關鍵突破在于引入了截斷矩陣熵 (Truncated Matrix Entropy) 。 通過分析 Token 矩陣協方差奇異值分布的「拐點」 , 我們只關注最重要的主成分 。 驚人的發現是:
? 截斷矩陣熵隨著層數加深 , 呈現出明顯的逐層遞減趨勢!
這不僅完美解釋了深層網絡的稀疏化現象 , 也為我們的壓縮策略提供了堅實的理論基礎 。 熵的減少意味著信息變得更加集中和稀疏 , 為壓縮創造了空間 。
從理論到實踐:
信息流的指引
這個理論工具讓我們能「看透」模型的內部運作:
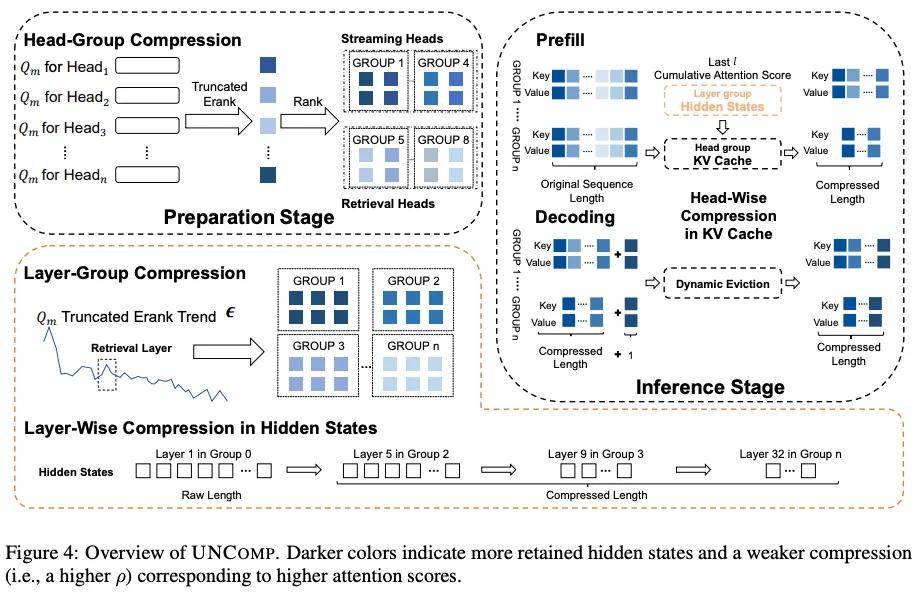
識別關鍵結構:中間層信息熵的異常波動點 , 精準地對應了負責信息聚合的檢索層 (Retrieval Layers)和負責長程記憶的檢索頭 (Retrieval Heads) 。 我們不再是盲目壓縮 , 而是有理論指導的結構化剪枝 。
最優壓縮的奧秘:我們進一步分析發現 , 最佳的壓縮性能和最終的準確率的權衡并非來自于尋找最優的累計注意力分布 , 而是來自于對「信息流模式」的模仿 。 我們用皮爾遜相關系數證明:當壓縮后 KV Cache 的逐層熵變趨勢 , 與原始全尺寸 Cache 的趨勢高度相似時 , 模型性能最好 。這意味著 , 我們的壓縮策略成功地保留了模型原有的信息壓縮模式 。
Group Query Attention 結構中呈現出明顯的頭共享的稀疏模式 。首創:
從隱藏狀態壓縮到 KV Cache 優化
基于以上理論 , 我們設計了 UNCOMP 框架 , 并首次通過直接壓縮 Prefill 階段的隱藏狀態 , 來間接優化 KV Cache , 實現了計算與內存的聯合優化 。
層級壓縮 (Layer-wise): 在 Prefill 階段壓縮隱藏狀態 , 加速計算 。 頭級壓縮 (Head-wise): 在 Decoding 階段壓縮流式頭的 KV Cache , 保留檢索頭節省內存 。
實驗結果亮點
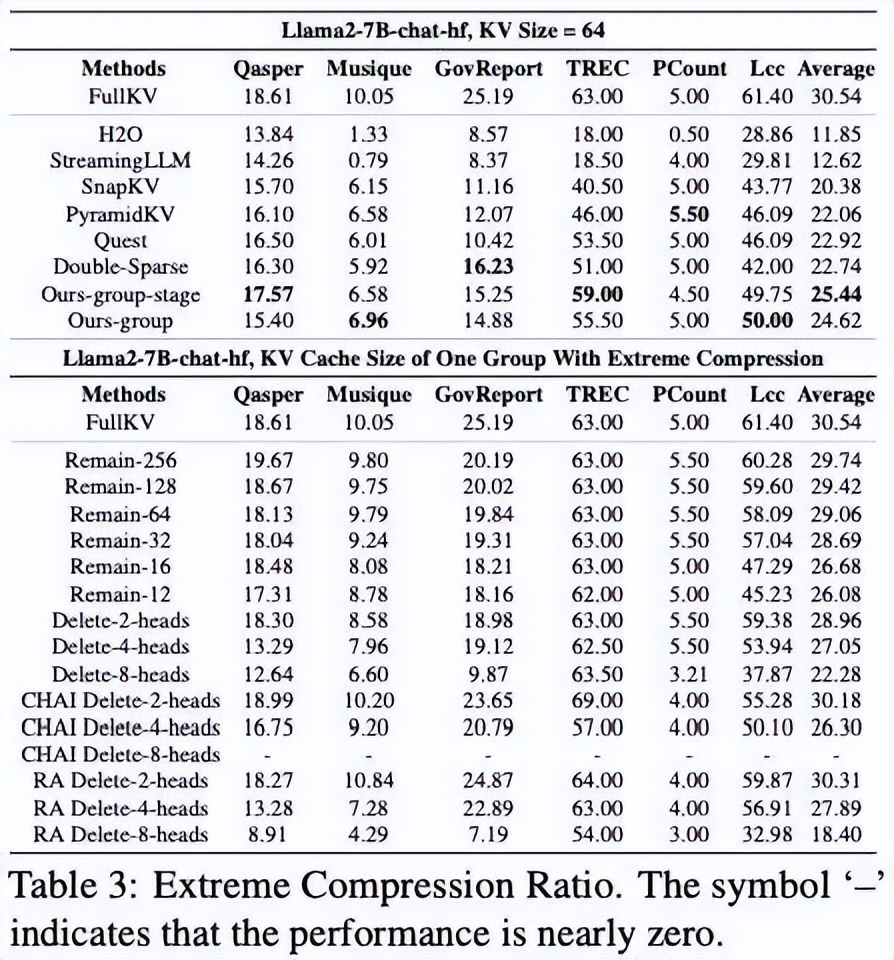
Prefill 階段加速60% 吞吐量提升6.4倍 KV Cache 壓縮至4.74%
極端壓縮率下依舊保證模型的性能
通過合并檢索層和最后的層大海撈針性能幾乎無損 , 在特定任務上超越全尺寸基線 。我們相信 , UNCOMP 不僅是一個工具 , 更是一扇窗口 , 幫助我們理解 LLM 內部復雜的信息壓縮行為 。
歡迎大家深入探討、引用和 star!
推薦閱讀













- 微信公布視頻通話3個隱藏功能,或許你也不知道
- iPhone有望2027年實現真正全面屏,隱藏Face ID與前置鏡頭
- 誰在偷偷隱藏手機信息?主流手機廠商官網詳細參數情況大調查
- 重磅!DeepSeek再開源:視覺即壓縮,100個token干翻7000個
- 解鎖 iPhone 17 系列隱藏技巧,16 個必會功能提升使用體驗!
- Intel新一代桌面CPU首次現身!開放隱藏核心+緩存、提速10%
- 騰訊發布SpecExit算法,無損壓縮端到端加速2.5倍!
- 重磅,DeepSeek再開源:視覺即壓縮,100個token干翻7000個
- 超越ZIP的無損壓縮來了,華盛頓大學讓大模型成為無損文本壓縮器
- GPT-5攻克量子NP難題,首篇論文引爆學界!人類2周壓縮至30分鐘