
文章圖片
文章圖片
大語(yǔ)言模型可以從互聯(lián)網(wǎng)上海量的文本中學(xué)習(xí) , 但當(dāng)這些模型需要進(jìn)化成能夠自主行動(dòng)的智能體(Agent)時(shí) , 數(shù)據(jù)問(wèn)題變得完全不同 。 Agent 需要的不是簡(jiǎn)單的文本序列 , 而是包含“觀察-行動(dòng)-反饋”完整循環(huán)的交互軌跡(trajectory)數(shù)據(jù) 。
相關(guān)研究顯示 , 這類數(shù)據(jù)的收集正成為 Agent 開發(fā)的最大瓶頸:人工標(biāo)注成本高昂 , 合成數(shù)據(jù)質(zhì)量難以保證 , 而記錄現(xiàn)有 Agent 的軌跡又受限于其能力上限 。
雖然已有一些自我進(jìn)化(self-evolution)方法試圖讓模型自己生成訓(xùn)練數(shù)據(jù) , 但這些方法普遍面臨兩個(gè)困境:模型只能生成不超出自身知識(shí)范圍的任務(wù) , 以及僅支持單輪交互而無(wú)法處理復(fù)雜的多步推理 。
面對(duì)這個(gè)困境 , 近期 , 由北卡羅來(lái)納大學(xué)教堂山分校(UNC)助理教授姚驊修領(lǐng)導(dǎo)的聯(lián)合團(tuán)隊(duì)提出了 Agent0 框架 , 試圖通過(guò)引入外部工具和多輪交互來(lái)打破這些局限 。
圖丨相關(guān)論文(來(lái)源:arXiv)
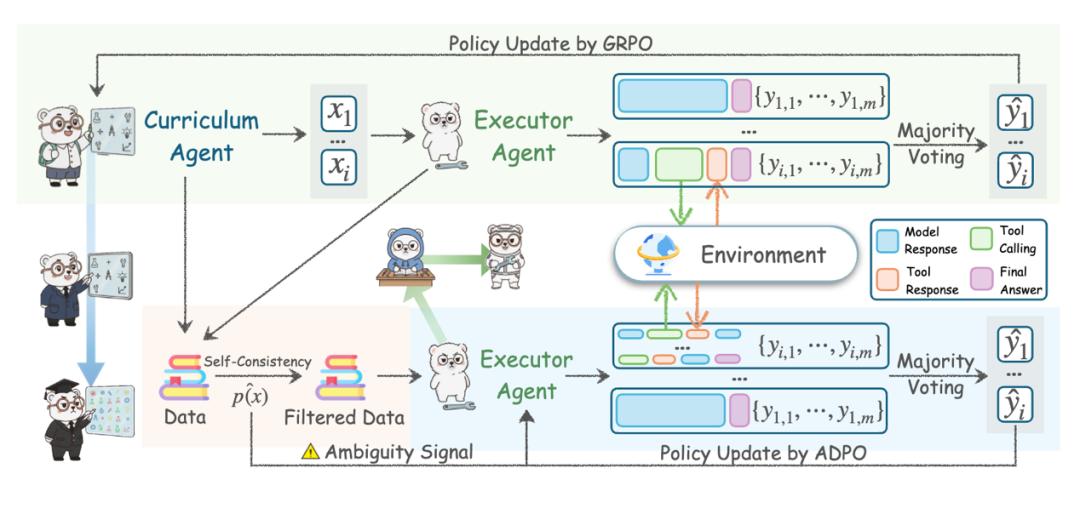
Agent0 的核心是一個(gè)雙智能體協(xié)同進(jìn)化系統(tǒng) 。 系統(tǒng)包含兩個(gè)從同一基礎(chǔ)模型初始化的 Agent:課程智能體(Curriculum Agent)負(fù)責(zé)生成問(wèn)題 , 執(zhí)行智能體(Executor Agent)則嘗試解決這些問(wèn)題 。
但課程智能體不是隨意出題 , 而是通過(guò)強(qiáng)化學(xué)習(xí)(Reinforcement Learning , RL)優(yōu)化 , 專門生成那些恰好處于執(zhí)行智能體能力邊界的任務(wù) 。
這個(gè)邊界如何界定?研究團(tuán)隊(duì)用了一個(gè)巧妙的方法:讓執(zhí)行智能體對(duì)同一問(wèn)題生成多個(gè)答案 , 如果答案不一致 , 說(shuō)明這個(gè)問(wèn)題正好在它能力的邊緣 。
他們將這種不確定性量化為一個(gè)獎(jiǎng)勵(lì)函數(shù) , 當(dāng)執(zhí)行智能體的答案分布接近 50% 一致時(shí) , 也就是最糾結(jié)的時(shí)候 , 獎(jiǎng)勵(lì)最高 。 這種設(shè)計(jì)確保了生成的任務(wù)既不會(huì)太簡(jiǎn)單讓模型學(xué)不到東西 , 也不會(huì)難到完全無(wú)法入手 。
圖丨Agent0 自主共演化框架 。 (來(lái)源:arXiv)
但這樣還不夠 。 如果只靠模型自己的知識(shí)生成和解決問(wèn)題 , 很快就會(huì)陷入停滯 , 模型不可能憑空創(chuàng)造出超出自己理解范圍的任務(wù) 。 研究團(tuán)隊(duì)的方法是引入外部工具 , 具體來(lái)說(shuō)是一個(gè) Python 代碼解釋器 。
這個(gè)工具可以執(zhí)行代碼、進(jìn)行復(fù)雜計(jì)算、驗(yàn)證數(shù)學(xué)結(jié)果 。 不僅執(zhí)行智能體可以使用這個(gè)工具 , 課程智能體也配備了同樣的能力 。
這就形成了一個(gè)獨(dú)特的協(xié)同進(jìn)化機(jī)制 。 執(zhí)行智能體有了代碼解釋器后 , 可以解決需要復(fù)雜計(jì)算的問(wèn)題 , 能力邊界向外擴(kuò)展 。 這時(shí)課程智能體發(fā)現(xiàn) , 原來(lái)能難倒執(zhí)行智能體的問(wèn)題現(xiàn)在變簡(jiǎn)單了 , 不確定性獎(jiǎng)勵(lì)下降 。
為了維持獎(jiǎng)勵(lì)水平 , 課程智能體被迫生成更復(fù)雜的、需要更多工具調(diào)用的問(wèn)題 。 研究團(tuán)隊(duì)在獎(jiǎng)勵(lì)函數(shù)中特意加入了工具使用頻率的獎(jiǎng)勵(lì)項(xiàng) , 進(jìn)一步推動(dòng)這個(gè)螺旋上升的過(guò)程 。
圖丨Agent0 的協(xié)同進(jìn)化循環(huán)(來(lái)源:arXiv)
實(shí)驗(yàn)數(shù)據(jù)驗(yàn)證了這個(gè)機(jī)制的有效性 。 在三輪迭代中 , 課程智能體生成的任務(wù)里平均工具調(diào)用次數(shù)從 1.65 次增加到 2.60 次 , 任務(wù)難度也確實(shí)在上升 , 用第一輪的執(zhí)行智能體去測(cè)試后續(xù)生成的任務(wù) , 通過(guò)率從 64% 持續(xù)下降到 51% 。
研究團(tuán)隊(duì)手工檢查了生成的問(wèn)題樣本:第一輪的問(wèn)題相對(duì)直接 , 比如“正方形內(nèi)至少需要多少個(gè)點(diǎn)才能保證有兩個(gè)點(diǎn)距離不超過(guò) 0.25 單位”;到了第三輪 , 問(wèn)題演化為“一個(gè)滿足特定遞推關(guān)系的正整數(shù)序列 , 求第 2024 項(xiàng)除以 1000 的余數(shù)” , 這需要設(shè)計(jì)算法、編寫代碼、處理大數(shù)運(yùn)算 。
執(zhí)行智能體的訓(xùn)練面臨另一個(gè)挑戰(zhàn):沒有人工標(biāo)注 , 怎么知道答案對(duì)不對(duì)?系統(tǒng)采用的是多數(shù)投票機(jī)制 , 讓執(zhí)行智能體對(duì)每個(gè)問(wèn)題生成 10 個(gè)答案 , 把得票最多的答案當(dāng)作“正確答案” 。
但研究團(tuán)隊(duì)意識(shí)到這種偽標(biāo)簽(pseudo-label)的可靠性參差不齊 。 對(duì)于執(zhí)行智能體回答高度一致的簡(jiǎn)單任務(wù) , 多數(shù)投票結(jié)果可信;對(duì)于回答分散的困難任務(wù) , 偽標(biāo)簽可能就是錯(cuò)的 。
他們?yōu)榇碎_發(fā)了 ADPO(Ambiguity-Dynamic Policy Optimization , 歧義動(dòng)態(tài)策略優(yōu)化)算法 。 這個(gè)算法的核心思路是“看菜下碟” , 根據(jù)任務(wù)的歧義程度動(dòng)態(tài)調(diào)整訓(xùn)練策略 。 對(duì)于高歧義任務(wù) , 降低訓(xùn)練信號(hào)的權(quán)重 , 避免模型在可能錯(cuò)誤的標(biāo)簽上過(guò)度學(xué)習(xí) 。
同時(shí)還放寬策略更新的約束 , 給模型更大的探索空間 。 標(biāo)準(zhǔn)的強(qiáng)化學(xué)習(xí)算法為了穩(wěn)定性會(huì)嚴(yán)格限制每步更新的幅度 , 但分析顯示這種限制主要壓制的是那些概率低但可能正確的答案路徑 , 對(duì)困難任務(wù)反而不利 。
執(zhí)行智能體的訓(xùn)練還包含一個(gè)關(guān)鍵設(shè)計(jì):多輪交互 。 不同于傳統(tǒng)的單次輸入-輸出 , 執(zhí)行代理會(huì)進(jìn)行多步推理:先生成自然語(yǔ)言推理 , 識(shí)別需要計(jì)算的部分 , 生成 Python 代碼 , 執(zhí)行代碼獲得結(jié)果 , 將結(jié)果融入推理過(guò)程 , 必要時(shí)進(jìn)行多輪代碼調(diào)用 , 最終給出答案 。 這模擬了人類解決復(fù)雜問(wèn)題時(shí)“嘗試-反饋-修正”的過(guò)程 。
當(dāng)然 , 不是課程智能體生成的所有任務(wù)都適合拿來(lái)訓(xùn)練 。 系統(tǒng)會(huì)根據(jù)自洽性分?jǐn)?shù)篩選 , 只保留那些執(zhí)行智能體自洽性在 0.3 到 0.8 之間的任務(wù)——太簡(jiǎn)單(接近 1)學(xué)不到東西 , 太難(接近 0)偽標(biāo)簽不可靠 。
在 Qwen3-8B 基礎(chǔ)模型上的測(cè)試結(jié)果相當(dāng)可觀 。 經(jīng)過(guò)三輪迭代 , 數(shù)學(xué)推理能力從 49.2% 提升到 58.2% , 漲幅約為 18% 。 在 MATH(高中競(jìng)賽數(shù)學(xué))、GSM8K(小學(xué)應(yīng)用題)、2024 和 2025 年美國(guó)數(shù)學(xué)邀請(qǐng)賽等多個(gè)基準(zhǔn)上 , 模型表現(xiàn)也都有穩(wěn)定提升 。
【華人團(tuán)隊(duì)提出智能體自我進(jìn)化框架,大幅提升通用推理能力】圖丨數(shù)學(xué)推理基準(zhǔn)的綜合結(jié)果(來(lái)源:arXiv)
更重要的是這種方法所表現(xiàn)出的泛化能力 。 雖然訓(xùn)練聚焦在數(shù)學(xué)問(wèn)題上 , 但模型在通用推理任務(wù)上的表現(xiàn)也提升了約 24% 。 SuperGPQA(研究生水平的跨學(xué)科問(wèn)題)從 28.3% 提升到 33.0% , MMLU-Pro(多任務(wù)語(yǔ)言理解)從 51.8% 提升到 63.4% , BBEH(Big-Bench 困難子集)從 8.6% 提升到 13.7% 。 這說(shuō)明通過(guò)工具輔助培養(yǎng)的多步推理能力確實(shí)可以遷移到其他領(lǐng)域 。
對(duì)比其他無(wú)需外部數(shù)據(jù)的方法 , Agent0 比 R-Zero 方法提升了 6.4% , 相比同樣使用代碼執(zhí)行器的 Absolute Zero 提升了 10.6% , 甚至比依賴 OpenAI API 的 Socratic-Zero 還高出 3.7% 。
消融實(shí)驗(yàn)進(jìn)一步證明去掉任何一個(gè)核心組件都會(huì)導(dǎo)致性能下降:如果移除課程智能體的訓(xùn)練 , 性能將大幅下跌 9.3%;若不給予工具使用獎(jiǎng)勵(lì) , 則下降 7.2% 。
不過(guò) , 團(tuán)隊(duì)表示這一方法更適合有明確驗(yàn)證標(biāo)準(zhǔn)的任務(wù) , 比如數(shù)學(xué)、編程、邏輯推理 。 對(duì)于創(chuàng)意寫作、風(fēng)格設(shè)計(jì)這類主觀性強(qiáng)的任務(wù) , 多數(shù)投票機(jī)制就不太管用了 。
而且雖然省去了人工標(biāo)注 , 但同時(shí)訓(xùn)練兩個(gè) Agent、每個(gè)任務(wù)生成 10 個(gè)候選答案 , 計(jì)算開銷也不小 。 框架目前依賴能提供客觀反饋的工具 , 對(duì)純語(yǔ)言推理或需要人類主觀判斷的任務(wù)適用性有限 。
但 Agent0 展示的方向值得關(guān)注 。 隨著 Agent 應(yīng)用越來(lái)越廣 , 軌跡數(shù)據(jù)需求會(huì)持續(xù)增長(zhǎng) , 完全依賴人工標(biāo)注顯然不可持續(xù) 。 Agent0 證明了 AI 系統(tǒng)可以在沒有人類直接監(jiān)督的情況下 , 通過(guò)精心設(shè)計(jì)的自我博弈和工具輔助實(shí)現(xiàn)能力的螺旋式上升 。
目前 , 研究團(tuán)隊(duì)已經(jīng)將相關(guān)代碼開源 。
參考資料:
相關(guān)論文:https://arxiv.org/pdf/2511.16043
項(xiàng)目地址:https://github.com/aiming-lab/Agent0
運(yùn)營(yíng)/排版:何晨龍
推薦閱讀











- 消息稱蘋果再次裁減銷售團(tuán)隊(duì)部分員工 兩年前曾有過(guò)精簡(jiǎn)
- 挖走多名AI工程師后 OpenAI又在從蘋果硬件團(tuán)隊(duì)大量挖人
- 大模型瘦身術(shù):上交大團(tuán)隊(duì)創(chuàng)新異構(gòu)計(jì)算,實(shí)現(xiàn)GPU計(jì)算零等待
- 14萬(wàn),家務(wù)機(jī)器人帶回家!斯坦福華人博士具身創(chuàng)業(yè)首款產(chǎn)品亮相
- 剛剛!美半?yún)f(xié)首位華人主席當(dāng)選!
- 火山引擎多媒體實(shí)驗(yàn)室提出VQ-Insight,AIGC視頻畫質(zhì)理解大模型
- 何愷明團(tuán)隊(duì)新作:擴(kuò)散模型可能被用錯(cuò)了
- MIT英偉達(dá)團(tuán)隊(duì)革新注意力機(jī)制,破解LLM性能難題
- Google Play 2025年度榜單:大中華開發(fā)者團(tuán)隊(duì)斬獲16項(xiàng)大獎(jiǎng)
- AWS推出Kiro正式版,支持團(tuán)隊(duì)協(xié)作和CLI功能