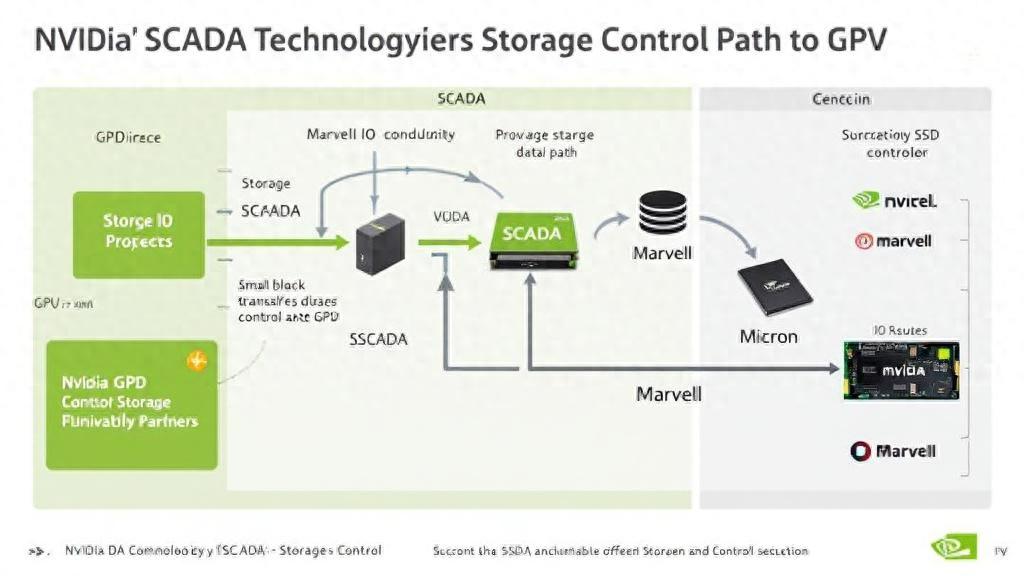
【Nvidia SCADA技術(shù)將存儲(chǔ)控制路徑轉(zhuǎn)移至GPU】Nvidia SCADA方案正在為AI推理工作負(fù)載引入GPU控制的存儲(chǔ)IO , 相比GPUDirect , 它在小塊傳輸方面將更加快速 。
什么是SCADA技術(shù)
SCADA是Nvidia在\"Storage-Next\"架構(gòu)中提出的術(shù)語 , 全稱為Scaled Accelerated Data Access(規(guī)模化加速數(shù)據(jù)訪問) 。 這是一種存儲(chǔ)數(shù)據(jù)IO方案 , GPU服務(wù)器中的GPU可以直接啟動(dòng)和控制存儲(chǔ)IO 。 這與Nvidia現(xiàn)有的GPUDirect協(xié)議形成對(duì)比 , 后者用于加速存儲(chǔ)IO 。
在最初的設(shè)計(jì)中 , GPU被x86服務(wù)器視為輔助加速器 , 服務(wù)器控制著數(shù)據(jù)的流入和流出 , 同時(shí)擁有IO的控制路徑和數(shù)據(jù)路徑 。 GPUDirect將數(shù)據(jù)路徑從x86 CPU中分離出來 , 通過RDMA技術(shù)實(shí)現(xiàn)GPU內(nèi)存與NVMe驅(qū)動(dòng)器之間的直接數(shù)據(jù)傳輸 , 但CPU仍然控制著控制路徑 。 而SCADA更進(jìn)一步 , 將控制路徑也從CPU中分離出來 。
AI訓(xùn)練與推理的不同需求
AI訓(xùn)練通常需要大批量數(shù)據(jù)傳輸 , 傳輸?shù)目刂坡窂綍r(shí)間相對(duì)較小 。 而AI推理需要小塊IO(小于4KB) , 每次傳輸?shù)目刂坡窂綍r(shí)間相對(duì)較大 。 Nvidia的研究發(fā)現(xiàn) , 讓GPU啟動(dòng)這類傳輸將減少時(shí)間并加速推理過程 。 SCADA正是這一發(fā)現(xiàn)的產(chǎn)物 , Nvidia在2025年FMS論文中對(duì)此進(jìn)行了詳細(xì)討論 。
生態(tài)系統(tǒng)合作伙伴的支持
Nvidia正與存儲(chǔ)生態(tài)系統(tǒng)合作伙伴合作 , 將使用SCADA的SSD和控制器產(chǎn)品化 。 SSD控制器制造商Marvell的閃存存儲(chǔ)產(chǎn)品營銷總監(jiān)Chander Chadha表示:\"AI基礎(chǔ)設(shè)施的需求促使存儲(chǔ)公司開發(fā)專門支持GPU的SSD、控制器、NAND等技術(shù) , 重點(diǎn)是為AI推理提供更高的IOPS(每秒輸入/輸出操作次數(shù)) , 這將與CPU連接驅(qū)動(dòng)器有根本不同 , 后者更關(guān)注延遲和容量 。 \"
Chadha解釋說:\"GPU在SCADA框架內(nèi)啟動(dòng)存儲(chǔ)事務(wù) , 該框架圍繞內(nèi)存語義構(gòu)建\" , 這意味著SSD控制器必須響應(yīng)加載和存儲(chǔ)請(qǐng)求 。
他指出 , 當(dāng)前的SSD在IOPS方面響應(yīng)速度不夠快 , \"對(duì)于小于4KB的數(shù)據(jù)集 , 導(dǎo)致PCIe總線利用率不足 , 使GPU缺乏數(shù)據(jù)并浪費(fèi)周期 。 \"GPU在推理工作負(fù)載中可能需要此類數(shù)據(jù)來維持超過1000個(gè)并行線程 。 相比之下 , 采用CPU啟動(dòng)傳輸?shù)腁I訓(xùn)練需要的并行線程較少 。 Chadha說:\"GPU并行線程的數(shù)量要低得多——幾十個(gè)對(duì)幾千個(gè)——而且數(shù)據(jù)集規(guī)模更大 。 \"
技術(shù)發(fā)展方向
更快的PCIe總線(如PCIe 6和7)將有所幫助 , 但SSD控制器也需要更新SCADA加速器功能和\"針對(duì)較小負(fù)載的最佳糾錯(cuò)方案 。 \"
Chadha預(yù)計(jì)將出現(xiàn)能夠處理兩種類型工作負(fù)載的SSD控制器 , \"能夠同時(shí)處理PCIe和以太網(wǎng)流量 。 \"他還表示 , \"預(yù)計(jì)未來將看到與高帶寬閃存或CXL網(wǎng)絡(luò)接口相關(guān)的工作 。 \"
美光的SCADA實(shí)踐
NAND和SSD供應(yīng)商美光也積極參與SCADA開發(fā) 。 該公司推出了PCIe Gen 6 SSD——9650 , 具有\(zhòng)"小塊操作優(yōu)化\"功能 。 7.68TB型號(hào)可提供高達(dá)540萬隨機(jī)讀取IOPS 。 美光在SC25展會(huì)上演示了44個(gè)這樣的SSD , 使用SCADA編程模型實(shí)現(xiàn)了2.3億IOPS 。
該設(shè)置使用連接到Broadcom PEX90000 PCIe Gen 6交換機(jī)的SSD , 安裝在H3 Platform Falcon 6048 PCIe Gen 6服務(wù)器中 。 該服務(wù)器包含三個(gè)Nvidia H100 PCIe Gen 5 GPU 。
美光表示 , 該系統(tǒng)\"展示了從1到44個(gè)SSD的線性擴(kuò)展 。 \"演示的2.3億最大IOPS數(shù)字非常接近44個(gè)驅(qū)動(dòng)器聚合的540萬隨機(jī)讀取IOPS的理論最大值2.376億 。
美光總結(jié)道:\"結(jié)合PCIe Gen6高性能SSD , 這種SCADA架構(gòu)實(shí)現(xiàn)了向量數(shù)據(jù)庫、圖神經(jīng)網(wǎng)絡(luò)和大規(guī)模推理流水線等工作負(fù)載的實(shí)時(shí)數(shù)據(jù)訪問 。 \"
補(bǔ)充說明
SCADA縮寫傳統(tǒng)上用于監(jiān)督控制和數(shù)據(jù)采集 , 指的是遙測領(lǐng)域 。 Nvidia的用法雖然不同 , 但具有相似性 。
Q&A
Q1:Nvidia SCADA技術(shù)相比GPUDirect有什么優(yōu)勢?
A:SCADA技術(shù)將存儲(chǔ)控制路徑也轉(zhuǎn)移到GPU , 而GPUDirect只轉(zhuǎn)移了數(shù)據(jù)路徑 。 對(duì)于AI推理中常見的小于4KB的小塊數(shù)據(jù)傳輸 , SCADA能夠顯著減少傳輸時(shí)間 , 提高推理速度 , 因?yàn)镚PU可以直接啟動(dòng)和控制存儲(chǔ)操作 。
Q2:為什么AI推理和AI訓(xùn)練對(duì)存儲(chǔ)IO的需求不同?
A:AI訓(xùn)練通常需要大批量數(shù)據(jù)傳輸 , 控制路徑時(shí)間相對(duì)較小 , 并行線程數(shù)量較少(幾十個(gè)) 。 而AI推理需要小塊IO處理(小于4KB) , 每次傳輸?shù)目刂坡窂綍r(shí)間相對(duì)較大 , 需要維持超過1000個(gè)并行線程 , 因此對(duì)IOPS性能要求更高 。
Q3:美光在SCADA技術(shù)演示中取得了什么成果?
A:美光使用44個(gè)PCIe Gen 6 SSD 9650 , 在H3 Platform Falcon 6048服務(wù)器上演示了2.3億IOPS的性能 , 接近理論最大值2.376億 。 這證明了SCADA架構(gòu)能夠?qū)崿F(xiàn)從1到44個(gè)SSD的線性擴(kuò)展 , 為向量數(shù)據(jù)庫和大規(guī)模推理流水線提供實(shí)時(shí)數(shù)據(jù)訪問 。
推薦閱讀













- NVIDIA中國特供RTX 6000D現(xiàn)身:核心、顯存、頻率全部大砍
- 英偉達(dá)緊急發(fā)聲:技術(shù)領(lǐng)先行業(yè)一代,主導(dǎo)地位無可替代
- iPhone Fold首發(fā)蘋果屏下前攝技術(shù):首款真全面屏iPhone
- 測試技術(shù)為何能成為存儲(chǔ)產(chǎn)業(yè)高質(zhì)量發(fā)展的“隱形推手”?
- AI催生超大封裝需求,Intel EMIB與TSMC CoWos技術(shù)對(duì)比
- PC顯卡涼了 打游戲的被拋棄!NVIDIA:我們不再是顯卡公司
- 三星高管大調(diào)整:全面提拔技術(shù)人才,重振存儲(chǔ)及代工業(yè)務(wù)
- 顯存漲價(jià)太嚴(yán)重:NVIDIA與AMD計(jì)劃砍掉入門顯卡
- 虛實(shí)共振:模型×終端技術(shù)沙龍圓滿舉辦
- Keepit利用AI技術(shù)加速SaaS應(yīng)用連接器開發(fā)進(jìn)程