文章圖片
文章圖片

文章圖片

文章圖片

文章圖片
智東西
作者 | 李水青
編輯 | 心緣
智東西11月27 日?qǐng)?bào)道 , 今日 , DeepSeek開(kāi)源了“奧數(shù)金牌級(jí)”模型DeepSeekMath-V2 , 該模型具備強(qiáng)大的定理證明能力 。
DeepSeekMath-V2在2025年國(guó)際數(shù)學(xué)奧林匹克競(jìng)賽(IMO 2025)和2024年中國(guó)數(shù)學(xué)奧林匹克競(jìng)賽(CMO 2024)上取得了金牌水平的成績(jī);并在2024年普特南大學(xué)生數(shù)學(xué)競(jìng)賽(Putnam 2024)上取得了接近滿分(118/120分)的成績(jī) , 超過(guò)人類最高的90分成績(jī) 。
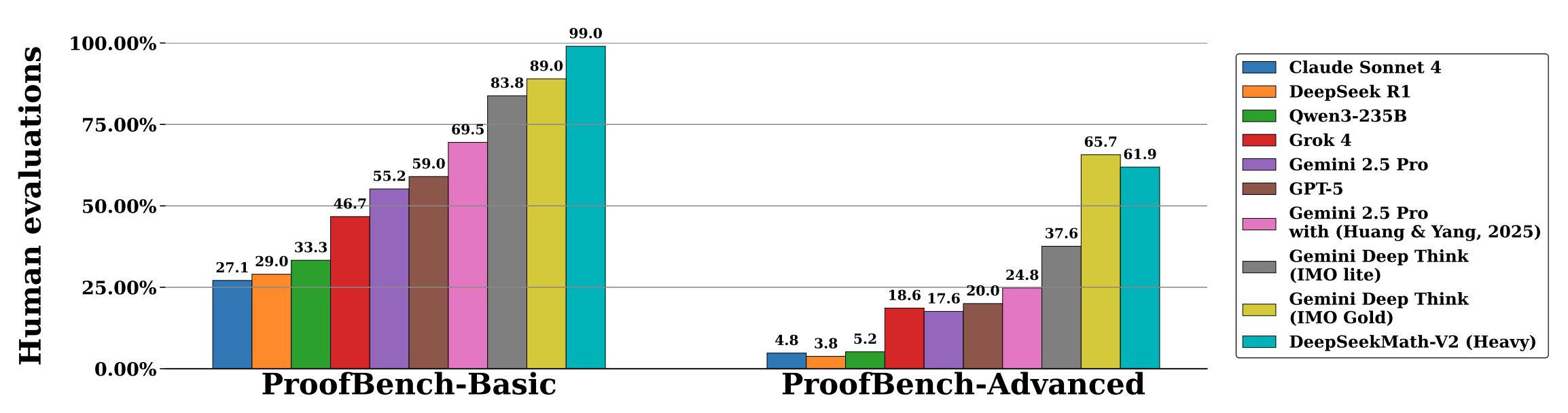
如下圖所示 , DeepSeekMath-V2以10%的優(yōu)勢(shì)擊敗谷歌的IMO金獎(jiǎng)得主DeepThink模型 。
DeepSeekMath-V2在數(shù)學(xué)競(jìng)賽中的成績(jī)表現(xiàn)
DeepSeekMath-V2在IMO-ProofBench的測(cè)評(píng)結(jié)果
上述結(jié)果表明 , 自驗(yàn)證數(shù)學(xué)推理是一個(gè)可行的研究方向 , 可能有助于開(kāi)發(fā)更強(qiáng)大的數(shù)學(xué)AI系統(tǒng) 。
Hugging Face地址:
https://huggingface.co/deepseek-ai/DeepSeek-Math-V2
論文地址:
https://github.com/deepseek-ai/DeepSeek-Math-V2/blob/main/DeepSeekMath_V2.pdf
按慣例 , DeepSeek往往會(huì)將新開(kāi)源的模型直接上線DeepSeek , 我們第一時(shí)間嘗試進(jìn)行了體驗(yàn) 。
首先讓DeepSeek證明一道較簡(jiǎn)單的題目“證明根號(hào)2為無(wú)理數(shù)” , DeepSeek快速給出了正確答案 。
當(dāng)智東西輸入“證明奇數(shù)和整數(shù)哪個(gè)多?”這一證明題 , DeepSeek也給出了正確證明過(guò)程和答案 , 這一證明過(guò)程大部分人應(yīng)該可以看懂 。 當(dāng)然 , 奧數(shù)級(jí)證明題會(huì)更加復(fù)雜 , 如果有能夠看懂理解這類題目的讀者 , 可以再進(jìn)一步進(jìn)行體驗(yàn)測(cè)試 。
回到模型背后的研發(fā)問(wèn)題 , 我們來(lái)具體看看論文內(nèi)容 , 從已有的研究來(lái)看 , 在數(shù)學(xué)推理領(lǐng)域 , 強(qiáng)化學(xué)習(xí)(RL)傳統(tǒng)方法足以讓大模型在主要評(píng)估最終答案的數(shù)學(xué)競(jìng)賽(如AIME和HMMT)中達(dá)到很高的水平 。 然而這種獎(jiǎng)勵(lì)機(jī)制存在兩個(gè)根本性的局限性:
首先 , 傳統(tǒng)方法不能可靠地代表推理的正確性 , 模型可能通過(guò)有缺陷的邏輯或僥幸的錯(cuò)誤得出正確答案 。
其次 , 它不適用于定理證明任務(wù) , 在這類任務(wù)中 , 問(wèn)題可能不需要生成數(shù)值形式的最終答案 , 而嚴(yán)謹(jǐn)?shù)耐茖?dǎo)才是主要目標(biāo) 。
為此 , DeepSeek建議在大型語(yǔ)言模型中開(kāi)發(fā)證明驗(yàn)證能力 , 基于DeepSeek-V3.2-Exp-Base開(kāi)發(fā)了DeepSeekMath-V2 。 他們讓模型明確了解其獎(jiǎng)勵(lì)函數(shù) , 并使其能夠通過(guò)有意識(shí)的推理而非盲目的試錯(cuò)來(lái)最大化這一獎(jiǎng)勵(lì) 。
DeepSeek制定了用于證明評(píng)估的高級(jí)評(píng)分標(biāo)準(zhǔn) , 目的是訓(xùn)練一個(gè)驗(yàn)證器 , 使其能根據(jù)這些評(píng)分標(biāo)準(zhǔn)對(duì)證明進(jìn)行評(píng)估 , 模擬數(shù)學(xué)專家的評(píng)估過(guò)程 。 以DeepSeek-V3.2-Exp-SFT的一個(gè)版本為基礎(chǔ) , 通過(guò)強(qiáng)化學(xué)習(xí)訓(xùn)練模型生成證明分析 , 訓(xùn)練過(guò)程使用了兩個(gè)獎(jiǎng)勵(lì)組件 。
然后是構(gòu)建強(qiáng)化學(xué)習(xí)數(shù)據(jù)集 。 DeepSeek基于17503道競(jìng)賽題目、DeepSeek-V3.2-Exp-Thinking生成的候選證明、帶專家評(píng)分的隨機(jī)抽取的證明樣本 , 構(gòu)建了初始強(qiáng)化學(xué)習(xí)訓(xùn)練數(shù)據(jù)集 。
其設(shè)置了強(qiáng)化學(xué)習(xí)目標(biāo)和訓(xùn)練驗(yàn)證器的強(qiáng)化學(xué)習(xí)目標(biāo) 。 具體是以DeepSeek-V3.2-Exp-SFT的一個(gè)版本為基礎(chǔ) , 通過(guò)強(qiáng)化學(xué)習(xí)訓(xùn)練模型生成證明分析 , 訓(xùn)練過(guò)程使用了兩個(gè)獎(jiǎng)勵(lì)組件:格式獎(jiǎng)勵(lì)和分?jǐn)?shù)獎(jiǎng)勵(lì) 。 而后通過(guò)下列函數(shù)完成訓(xùn)練驗(yàn)證器的強(qiáng)化學(xué)習(xí)目標(biāo) 。
為了解決訓(xùn)練過(guò)程中“驗(yàn)證器可能通過(guò)預(yù)測(cè)正確分?jǐn)?shù)同時(shí)虛構(gòu)不存在的問(wèn)題來(lái)獲得全部獎(jiǎng)勵(lì)”這一漏洞 , DeepSeek引入了一個(gè)二次評(píng)估過(guò)程——元驗(yàn)證(meta-verification) , 從而提高驗(yàn)證器識(shí)別問(wèn)題的忠實(shí)度 。
在證明生成階段 , DeepSeek進(jìn)行了證明生成器的訓(xùn)練 , 并通過(guò)自我驗(yàn)證增強(qiáng)推理能力 , 解決模型被要求一次性生成并分析自己的證明時(shí)“生成器不顧外部驗(yàn)證器判錯(cuò)而宣稱證明是正確的” 。
最后 , DeepSeek證明驗(yàn)證器和生成器形成了一個(gè)協(xié)同循環(huán):驗(yàn)證器改進(jìn)生成器 , 而隨著生成器的改進(jìn) , 它會(huì)生成新的證明 , 這些證明對(duì)驗(yàn)證器當(dāng)前的能力構(gòu)成挑戰(zhàn) , 這些挑戰(zhàn)也成為增強(qiáng)驗(yàn)證器自身的寶貴訓(xùn)練數(shù)據(jù) 。
簡(jiǎn)單來(lái)說(shuō) , DeepSeekMath-V2模型中的驗(yàn)證器能完成逐步檢查證明過(guò)程 , 而生成器則會(huì)修正自身的錯(cuò)誤 。
從實(shí)驗(yàn)結(jié)果來(lái)看 , 在單步生成結(jié)果評(píng)估中 , 如圖1所示 , 在CNML級(jí)別的所有問(wèn)題類別(代數(shù)、幾何、數(shù)論、組合數(shù)學(xué)和不等式)中 , DeepSeekMath-V2始終優(yōu)于GPT-5-Thinking-High和Gemini 2.5-Pro , 展現(xiàn)出在各領(lǐng)域更卓越的定理證明能力 。
在帶自我驗(yàn)證的順序優(yōu)化中 , 其對(duì)2024 IMO備選題進(jìn)行連續(xù)優(yōu)化后 , 證明質(zhì)量提升 。 自選的最佳證明比線程平均值獲得了顯著更高的驗(yàn)證分?jǐn)?shù) , 這表明生成器能夠準(zhǔn)確評(píng)估證明質(zhì)量 。 這些結(jié)果證實(shí) , 其生成器能夠可靠地區(qū)分高質(zhì)量證明和有缺陷的證明 , 并利用這種自我認(rèn)知系統(tǒng)地改進(jìn)其數(shù)學(xué)推理能力 。
在高計(jì)算量探索中 , DeepSeek擴(kuò)大了驗(yàn)證和生成計(jì)算的規(guī)模 , 他們的方法解決了2025 IMO的6道題中的5道 , 以及2024 CMO的4道題 , 另外1道題獲得部分分?jǐn)?shù) , 在這兩項(xiàng)頂尖高中競(jìng)賽中均達(dá)到金牌水平 , 在基礎(chǔ)集上優(yōu)于DeepMind的DeepThink(IMO金牌水平) , 在高級(jí)集上保持競(jìng)爭(zhēng)力 , 同時(shí)大幅優(yōu)于所有其他基線模型 。
但DeepSeek發(fā)現(xiàn) , 最困難的IMO級(jí)別問(wèn)題對(duì)其模型來(lái)說(shuō)仍然具有挑戰(zhàn)性 。
值得注意的是 , 對(duì)于未完全解決的問(wèn)題 , DeepSeek的生成器通常能在其證明過(guò)程中識(shí)別出真正的問(wèn)題 , 而完全解決的問(wèn)題則能通過(guò)所有64次驗(yàn)證嘗試 。 這表明 , 我們能夠成功訓(xùn)練基于大語(yǔ)言模型的驗(yàn)證器 , 以評(píng)估那些此前被認(rèn)為難以自動(dòng)驗(yàn)證的證明 。 通過(guò)在驗(yàn)證器的指導(dǎo)下增加測(cè)試時(shí)的計(jì)算量 , DeepSeek的模型能夠解決那些需要人類競(jìng)爭(zhēng)者花費(fèi)數(shù)小時(shí)才能解決的問(wèn)題 。
結(jié)語(yǔ):可自我驗(yàn)證的AI系統(tǒng) , 離解決研究級(jí)數(shù)學(xué)問(wèn)題更進(jìn)一步總的來(lái)說(shuō) , DeepSeek提出了一個(gè)既能生成又能驗(yàn)證數(shù)學(xué)證明的模型 。 團(tuán)隊(duì)突破了基于最終答案的獎(jiǎng)勵(lì)機(jī)制的局限性 , 邁向了可自我驗(yàn)證的數(shù)學(xué)推理 。
【剛剛,DeepSeek開(kāi)源新模型,拿下奧數(shù)證明題冠軍】這項(xiàng)工作證實(shí) , 大語(yǔ)言模型能夠培養(yǎng)出針對(duì)復(fù)雜推理任務(wù)的有意義的自我評(píng)估能力 。 盡管仍存在重大挑戰(zhàn) , 這一研究方向有望為創(chuàng)建可自我驗(yàn)證的AI系統(tǒng)解決研究級(jí)數(shù)學(xué)問(wèn)題這一目標(biāo)做出貢獻(xiàn) 。
推薦閱讀











- Adam的穩(wěn)+Muon的快?華為諾亞開(kāi)源ROOT破解大模型訓(xùn)練的兩難困境
- 小米開(kāi)源首個(gè)跨域具身基座模型MiMo-Embodied,29個(gè)榜單SOTA
- FLUX.2開(kāi)源了,但是我好像也看到了小公司的無(wú)力。
- Scaling時(shí)代終結(jié)了,Ilya Sutskever剛剛宣布
- 從零到千萬(wàn):一個(gè)中國(guó)開(kāi)源操作系統(tǒng)的全球崛起之路
- 剛剛,智能體&編程新王Claude Opus 4.5震撼登場(chǎng),定價(jià)大降2/3
- 奧特曼的焦慮:谷歌用了兩年追上OpenAI,真正的威脅才剛剛開(kāi)始
- 睿爾曼開(kāi)源全球首個(gè)高質(zhì)量、模態(tài)數(shù)量最多的真機(jī)數(shù)據(jù)集
- 剛剛,IC CHINA 2025!長(zhǎng)鑫首發(fā)DDR5
- 魔搭社區(qū)成中國(guó)最大AI開(kāi)源社區(qū) 已服務(wù)全球超2000萬(wàn)開(kāi)發(fā)者