
文章圖片
文章圖片

文章圖片

文章圖片

文章圖片

文章圖片

文章圖片

文章圖片

文章圖片

編輯:艾倫
【新智元導(dǎo)讀】DeepSeek V3.2的Agentic能力大增 , 離不開(kāi)這項(xiàng)關(guān)鍵機(jī)制:Interleaved Thinking(交錯(cuò)思維鏈) 。 Interleaved Thinking風(fēng)靡開(kāi)源社區(qū)背后 , 離不開(kāi)另一家中國(guó)公司的推動(dòng) 。
大模型的「健忘癥」 , 早該治治了!
當(dāng)你試圖用當(dāng)今最先進(jìn)的大模型幫你完成一個(gè)復(fù)雜的長(zhǎng)假規(guī)劃 , 比如「帶全家老小去云南玩七天」時(shí) , 往往很可能會(huì)遭遇一個(gè)令人崩潰的時(shí)刻:
起初 , 這位「導(dǎo)游」表現(xiàn)得極其靠譜 , 分析得頭頭是道 。
它記得你說(shuō)的每一句要求 , 幫你規(guī)劃了昆明到大理的路線 , 甚至貼心地避開(kāi)了游客太多的網(wǎng)紅店 。
但隨著對(duì)話進(jìn)行到第十輪 , 你們?yōu)榱诉x酒店修改了五次方案 , 又為了某頓晚餐爭(zhēng)論了半天后 , 它突然「失智」了 。
它開(kāi)始忘記你一開(kāi)始強(qiáng)調(diào)了無(wú)數(shù)遍的死命令:「帶著80歲的奶奶 , 絕對(duì)不能安排爬山和劇烈運(yùn)動(dòng)」 。
在最新的行程表里 , 它竟然興致勃勃地建議:「第四天清晨:全家早起徒步攀登玉龍雪山 , 欣賞日照金山 , 全程耗時(shí)4小時(shí)……」
圖片由Nano Banana Pro生成
在AI工程界 , 這種現(xiàn)象有一個(gè)術(shù)語(yǔ):狀態(tài)漂移(State Drift) 。
這并非模型「變笨」了 , 而是我們讓它思考的方式錯(cuò)了 。
為了治愈這種「健忘癥」 , Anthropic Claude、OpenAI GPT-OSS、MiniMax M2、Kimi K2 Thinking等國(guó)內(nèi)外各大模型都不約而同地選擇了同一項(xiàng)技術(shù):一邊思考 , 一邊用工具(Thinking in Tool-Use) 。
DeepSeek: Thinking in Tool-Use
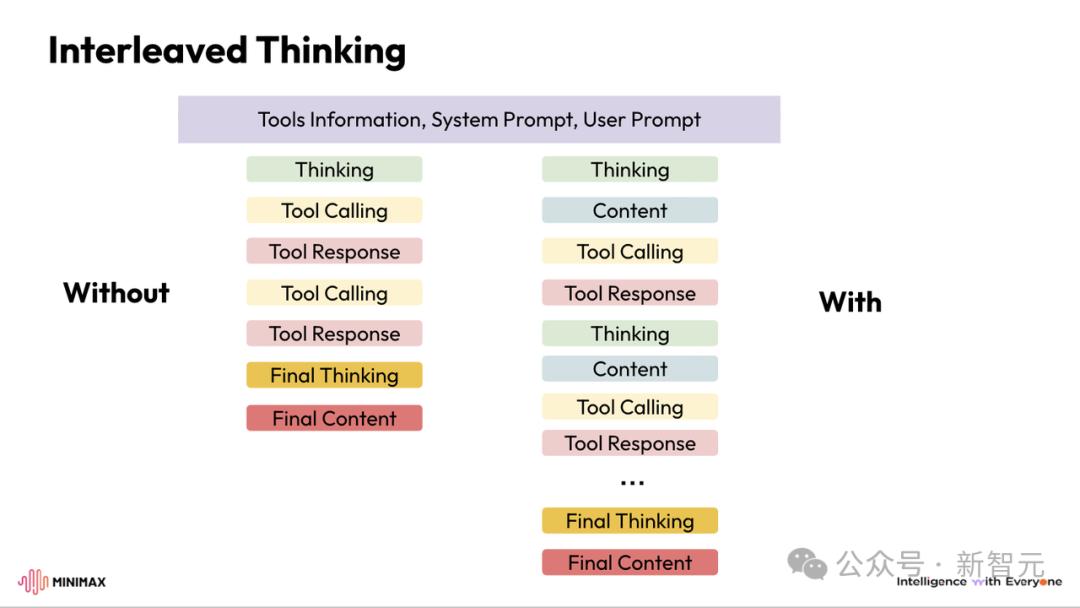
MiniMax等部分廠商也將其稱作Interleaved Thinking(交錯(cuò)思維鏈) , 從示意圖即可看出 , 二者本質(zhì)上是等價(jià)的 。 這是一個(gè)更貼近技術(shù)的稱呼 。
Minimax: Interleaved Thinking(交錯(cuò)思維鏈)
如圖所示 , 交錯(cuò)思維鏈即模型在推理(thinking)和工具調(diào)用(action)之間來(lái)回交替 , 并持續(xù)保留和復(fù)用每一輪的推理狀態(tài) , 從而實(shí)現(xiàn)穩(wěn)定、可累積的長(zhǎng)程規(guī)劃 。
崩潰的ReAct
與「隱式推理」的詛咒
要理解交錯(cuò)思維鏈為什么是「神技」 , 我們得先看看它的前任——早期的ReAct(Reasoning+Acting)范式是如何遇到瓶頸的 。
ReAct流程示意圖
在很長(zhǎng)一段時(shí)間里 , 我們構(gòu)建AI Agent的邏輯非常線性:觀察->思考->行動(dòng) 。
這看起來(lái)很符合直覺(jué) , 但在實(shí)際的工程實(shí)現(xiàn)(如OpenAI的Function Calling(函數(shù)調(diào)用))中 , 這個(gè)過(guò)程往往被簡(jiǎn)化成了「模型直接輸出工具調(diào)用指令」 。
問(wèn)題就出在這里 。
模型在輸出Action(比如「讀取文件A」)的那一刻 , 它的「腦子」是清醒的 。
但當(dāng)工具執(zhí)行完畢 , 返回了數(shù)千行的代碼或網(wǎng)頁(yè)內(nèi)容后 , 模型進(jìn)入下一輪生成時(shí) , 它面臨著巨大的環(huán)境擾動(dòng) 。
想象一下 , 你是一個(gè)程序員 , 每寫(xiě)一行代碼 , 就有人把你打暈 , 清除你的短期記憶 , 然后把剛才的運(yùn)行日志扔給你 , 讓你繼續(xù)寫(xiě) 。
由于缺乏顯式的、連續(xù)的思維記錄 , 模型很容易被復(fù)雜的工具返回結(jié)果帶偏 。
它可能會(huì)被報(bào)錯(cuò)信息吸引注意力 , 從而忘記了原本的長(zhǎng)期規(guī)劃 。
這就是「隱式推理」的詛咒 。
模型的思考過(guò)程隱藏在權(quán)重里 , 一旦被打斷(Turn-based interaction) , 這些思維火花就煙消云散了 。
交錯(cuò)思維鏈:給Agent裝上「海馬體」
MiniMax的研發(fā)團(tuán)隊(duì)在開(kāi)發(fā)M2模型時(shí) , 敏銳地捕捉到了這個(gè)痛點(diǎn) 。
Agent需要的不只是更長(zhǎng)的上下文窗口 , 更是一種顯式的、可累積的思考狀態(tài) 。
這就是交錯(cuò)思維鏈 。
它的工作流變成了:思考->行動(dòng)->觀察->思考->行動(dòng)->觀察...
【DeepSeek V3.2爆火,Agentic性能暴漲40%解密】
在這個(gè)閉環(huán)中 , 「思考」不再是可有可無(wú)的點(diǎn)綴 , 而是必須被記錄下來(lái)的狀態(tài) 。
在每一次調(diào)用工具之前 , 模型必須先輸出一段被包裹在reasoning_details(或類似的tag)中的自然語(yǔ)言 。
這段文字不只是給用戶看的 , 也是給未來(lái)的自己看的 , 讓自己知道來(lái)時(shí)路 。
為什么它能帶來(lái)40%的性能暴漲?
MiniMax M2的發(fā)布數(shù)據(jù)中 , 有一組數(shù)據(jù)有力說(shuō)明了這一機(jī)制的效果 。
在常規(guī)的SWE-Bench Verified(軟件工程)榜單上 , 開(kāi)啟交錯(cuò)思維鏈帶來(lái)了3.3%的提升(從67.2升至69.4) 。 這個(gè)提升雖然不錯(cuò) , 但還算溫和 。
然而 , 在BrowseComp(網(wǎng)頁(yè)瀏覽任務(wù))上 , 提升幅度達(dá)到了驚人的40%(從31.4飆升至44.0);在Tau2這種復(fù)雜推理任務(wù)上 , 提升了36% 。
為什么會(huì)有這種巨大的差異?這觸及了Agent技術(shù)的深層原理 。
MiniMax的后訓(xùn)練團(tuán)隊(duì)在技術(shù)復(fù)盤(pán)中指出:Agent的核心挑戰(zhàn) , 在于對(duì)抗環(huán)境的擾動(dòng) 。
- 低擾動(dòng)環(huán)境(SWE-Bench):代碼環(huán)境相對(duì)純凈 , 報(bào)錯(cuò)信息通常是確定性的 。 模型即使稍微「走神」 , 也能根據(jù)明確的Traceback找回邏輯 。
- 高擾動(dòng)環(huán)境(BrowseComp):真實(shí)的互聯(lián)網(wǎng)充滿了噪音 。 廣告、無(wú)關(guān)的側(cè)邊欄、復(fù)雜的DOM結(jié)構(gòu)、甚至是錯(cuò)誤的搜索結(jié)果 。 在傳統(tǒng)的ReAct模式下 , 模型極易被這些噪音帶偏 。
模型通過(guò)顯式的思考 , 在接收到龐雜的網(wǎng)頁(yè)信息后 , 先進(jìn)行一輪「信息清洗」和「邏輯校準(zhǔn)」:「我剛才搜索了X , 結(jié)果里有很多無(wú)關(guān)信息 , 只有第三段是我需要的 , 接下來(lái)我應(yīng)該根據(jù)這個(gè)線索去查Y 。 」
這種「走一步、停下來(lái)想一步、再走下一步」的機(jī)制 , 極大地增強(qiáng)了模型的健壯性 。
它將一個(gè)長(zhǎng)達(dá)數(shù)十步的脆弱鏈路 , 拆解成了一個(gè)個(gè)穩(wěn)固的「原子化」思考閉環(huán) 。
泛化的本質(zhì):從「工具」到「軌跡」
Agent的泛化 , 究竟是在泛化什么?
早期業(yè)界普遍認(rèn)為 , 只要讓模型學(xué)會(huì)使用更多的工具(Scaling Tools) , Agent就泛化了 。
但MiniMax團(tuán)隊(duì)發(fā)現(xiàn) , 這只是「輸入層」的泛化 。
真正的泛化 , 是對(duì)任務(wù)軌跡中所有可能擾動(dòng)的適應(yīng)能力 。
一個(gè)模型可能在Claude Code這種腳手架里表現(xiàn)完美 , 但換到Cline或者命令行里就一塌糊涂 。
因?yàn)椴煌沫h(huán)境、不同的提示詞結(jié)構(gòu)、不同的工具返回格式 , 都會(huì)對(duì)模型的推理軌跡產(chǎn)生擾動(dòng) 。
交錯(cuò)思維鏈讓模型擁有了自我修正的能力 。
通過(guò)在每一步都保留推理內(nèi)容 , 模型實(shí)際上是在不斷地與環(huán)境進(jìn)行「對(duì)齊」 。
即使換了一個(gè)陌生的IDE環(huán)境 , 只要「思考-行動(dòng)」的閉環(huán)還在 , 模型就能通過(guò)顯式的邏輯推理來(lái)適應(yīng)新環(huán)境 , 而不是依賴死記硬背的提示詞模板 。
這也是為什么MiniMax M2能夠在xBench、GAIA等多個(gè)異構(gòu)榜單上全面開(kāi)花的技術(shù)根源 。
MiniMax的「基建狂魔」之路
技術(shù)原理講清楚了 , 但落地卻是另一回事 。
在M2發(fā)布之初 , MiniMax面臨著一個(gè)尷尬的局面:行業(yè)的基礎(chǔ)設(shè)施嚴(yán)重滯后 。
雖然Anthropic最早提出了Extended Thinking的概念 , 但由于其閉源特性 , 社區(qū)并未形成統(tǒng)一標(biāo)準(zhǔn) 。
絕大多數(shù)開(kāi)源工具(如LangChain、LlamaIndex)和中間件 , 都是基于OpenAI的Chat Completion API構(gòu)建的 。
而這個(gè)標(biāo)準(zhǔn)API里 , 根本沒(méi)有地方放「思考過(guò)程」 。
這就導(dǎo)致了一個(gè)災(zāi)難性的后果:用戶在使用M2時(shí) , 習(xí)慣性地把API返回的reasoning_details字段當(dāng)成垃圾信息丟掉了 。
模型明明在思考 , 但它的記憶被無(wú)意中切除了 。 這直接導(dǎo)致了模型性能的血崩 。
面對(duì)這個(gè)問(wèn)題 , MiniMax順理成章 , 開(kāi)始自己著手修路 。
在過(guò)去的一段時(shí)間里 , MiniMax的工程師們化身開(kāi)源社區(qū)的「包工頭」 , 向全球主流的Agent開(kāi)發(fā)工具和平臺(tái)發(fā)起了密集的PR(Pull Request , 合并請(qǐng)求)攻勢(shì) 。
- Cline:這是VS Code上最火的AI編程插件之一 。 MiniMax團(tuán)隊(duì)與其緊密合作 , 修改了底層的消息處理邏輯 , 確保在IDE的對(duì)話歷史中 , 不僅保留代碼 , 還保留模型的思考過(guò)程 。 這直接讓M2在Cline里的表現(xiàn)從「不可用」變成了「絲滑」 。
- Kilo Code:針對(duì)這個(gè)新興的云端IDE , MiniMax提交了代碼 , 優(yōu)化了環(huán)境細(xì)節(jié)與工具結(jié)果的合并邏輯 , 解決了多輪對(duì)話中狀態(tài)丟失的問(wèn)題 。
- OpenRouter / Ollama:通過(guò)與這些模型托管平臺(tái)的合作 , MiniMax推動(dòng)了API協(xié)議的升級(jí) , 讓reasoning_details字段從一個(gè)「私有協(xié)議」逐漸變成了事實(shí)上的標(biāo)準(zhǔn)擴(kuò)展 。
AWS re:Invent 2025大會(huì)上 , AWS CEO宣布Amazon Bedrock模型庫(kù)迎來(lái)擴(kuò)容 , MiniMax M2作為中國(guó)模型代表在列
英雄所見(jiàn)略同
DeepSeek V3.2和Kimi K2 Thinking的入局
DeepSeek V3.2和Kimi K2 Thinking的發(fā)布 , 宣告了這條路正式成為了通往未來(lái)的主干道 。
最近引發(fā)轟動(dòng)的DeepSeek V3.2 , 其核心特性之一「Thinking in Tool-Use」(使用工具中思考) , 在本質(zhì)上與MiniMax倡導(dǎo)的交錯(cuò)思維鏈?zhǔn)峭耆恢碌?。
DeepSeek的技術(shù)文檔中明確指出:模型在調(diào)用工具時(shí) , 會(huì)保持思維鏈的連續(xù)性 , 直到收到新的用戶消息才會(huì)重置 。
這種設(shè)計(jì)邏輯與MiniMax M2強(qiáng)調(diào)的「多輪交互中保留思考狀態(tài)」如出一轍 。
Kimi K2 Thinking也支持了交錯(cuò)思維鏈 , 進(jìn)而得以Agentic能力上突飛猛進(jìn) 。
雖然兩家在具體的API字段命名上可能略有不同(MiniMax使用reasoning_details , DeepSeek使用reasoning_content , Anthropic使用thinking_blocks等) , 但在系統(tǒng)設(shè)計(jì)哲學(xué)上 , 大家已經(jīng)達(dá)成了一致:顯式的、交錯(cuò)的、持久化的思考 , 是智能體進(jìn)化的必經(jīng)之路 。
OpenAI的研究表明 , AI的性能不僅遵循參數(shù)量的Scaling Law , 也遵循Test-Time Compute(測(cè)試時(shí)計(jì)算)的Scaling Law 。
它正在從那個(gè)只會(huì)根據(jù)提示詞模板機(jī)械執(zhí)行命令的「復(fù)讀機(jī)」(Copilot) , 進(jìn)化為能夠在復(fù)雜的真實(shí)世界中 , 面對(duì)無(wú)數(shù)未知的擾動(dòng)和噪音 , 依然能夠停下來(lái)思考、自我修正、并堅(jiān)定地執(zhí)行長(zhǎng)鏈路任務(wù)的「思想者」(Autopilot) 。
而這 , 已成行業(yè)的共識(shí) 。
推薦閱讀












- DeepSeek-V3.2被找出bug了:瘋狂消耗token,答案還可能出錯(cuò)
- DeepSeek發(fā)布V3.2正式版
- 深夜,DeepSeek大消息!這個(gè)板塊迎來(lái)重磅催化,要加速?(附股)
- DeepSeek V3.2雙版本齊發(fā):推理比肩GPT-5,Speciale版奪國(guó)際奧賽金牌
- deepseek當(dāng)選網(wǎng)易有道詞典2025年度詞匯,全年搜索量超867萬(wàn)次
- 剛剛,DeepSeek開(kāi)源新模型,拿下奧數(shù)證明題冠軍
- “美國(guó)公司制造的最好開(kāi)源模型”,基模來(lái)自DeepSeek
- DeepSeek悄悄開(kāi)源LPLB:用線性規(guī)劃解決MoE負(fù)載不均
- 啊?微博7800美元訓(xùn)的大模型,數(shù)學(xué)能力超了DeepSeek-R1
- 雷軍挖來(lái)前DeepSeek大將!大模型團(tuán)隊(duì)40人合影曝光,疑進(jìn)軍具身智能