
文章圖片
2025 年末 , 一份來自斯坦福大學人本人工智能研究院(Stanford Institute for Human-Centered Artificial Intelligence , 簡稱 HAI)與 DigiChina 項目聯合發布了一項政策簡報 , 對中國開放權重 AI 模型的全球崛起這一在硅谷引發熱議卻鮮少被系統分析的話題進行了深入解讀 。
這份題為《超越 DeepSeek:中國多元化的開放權重 AI 生態系統及其政策影響》的報告 , 發布于 12 月初 , 由 Caroline Meinhardt、Sabina Nong、Graham Webster 等五位研究者聯合撰寫 。
圖丨相關報告(來源:HAI)
報告試圖厘清一個現實:當 DeepSeek 在今年 1 月以一款推理模型震驚全球投資者、讓英偉達市值單日蒸發近千億美元時 , 這家杭州初創公司并非中國 AI 領域的唯一選手 。 它只是一個更龐大、更多元生態系統的冰山一角 。
從追趕到領跑
報告援引的多項數據指向一個明確結論:在開源大模型領域 , 中國已從追趕者變為領跑者 。 所謂開放權重 , 指的是模型的參數權重可供下載、使用和修改 , 開發者能夠在官方應用或 API 之外獨立運行這些模型 , 并根據自身需求進行調整 。
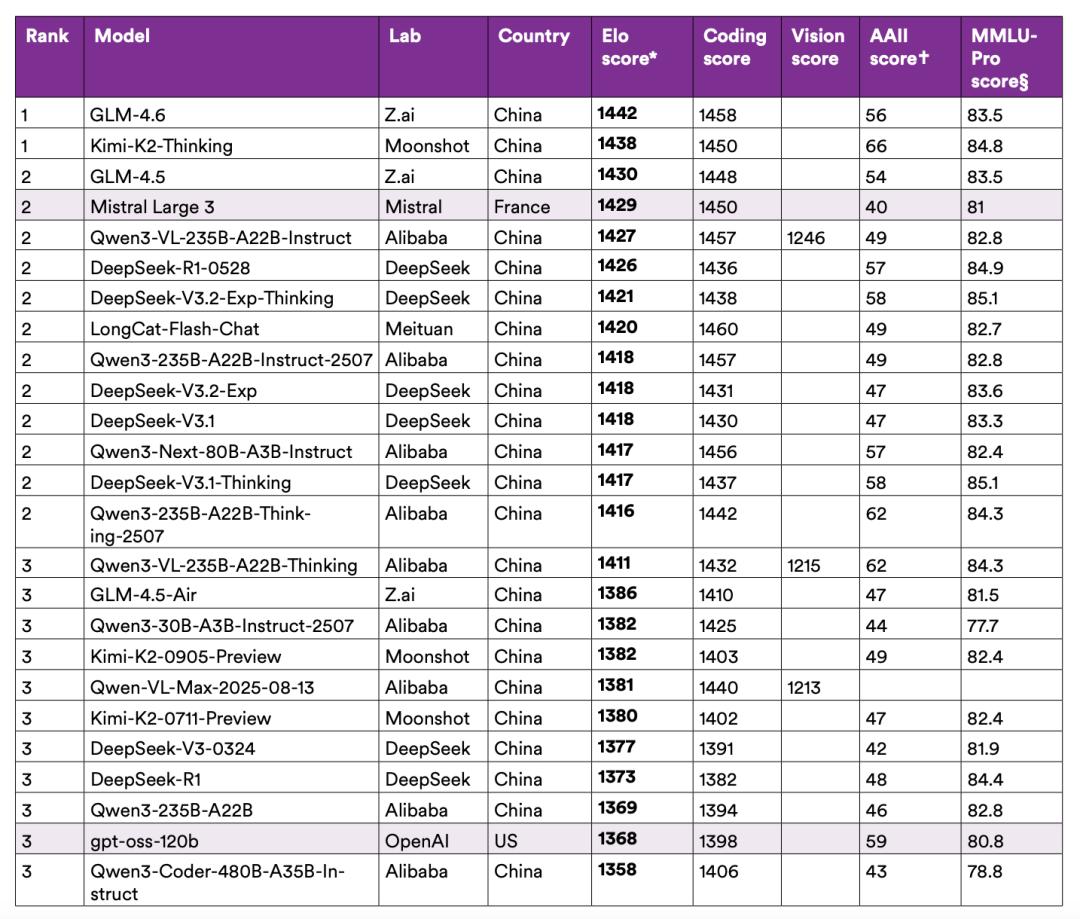
根據 Hugging Face 平臺的下載統計 , 阿里巴巴旗下的 Qwen(通義千問)模型系列在 2025 年 9 月正式超越 Meta 的 Llama , 成為該平臺下載量最高的大語言模型家族 。 截至 12 月中旬 , Qwen 累計下載量已達約 3.85 億次 , 而 Llama 約為 3.46 億次 。 另一組數據同樣值得關注:2024 年 8 月至 2025 年 8 月間 , 中國開發者的模型下載量占 Hugging Face 總下載量的 17.1% , 首次超過美國的 15.8% 。 這組數據由麻省理工學院與 Hugging Face 聯合追蹤 , 經 ATOM 項目分析后公布 。
圖丨開源模型的累積下載量(來源:HAI)
衍生模型的增長曲線更能說明問題 。 自 2025 年 1 月起 , 基于 Qwen 和 DeepSeek 的衍生模型上傳數量持續攀升 , 到 9 月份時 , 中國模型的衍生版本已占 Hugging Face 當月新增衍生模型的 63% 。 這意味著全球開發者社區正在以前所未有的速度圍繞中國模型構建應用生態 。
報告重點剖析了四個具有代表性的中國模型家族 。
Qwen 由阿里云開發 , 定位于多語言和多模態能力最強的通用模型 , 支持 119 種語言 , 采用 Apache 2.0 許可證開源;DeepSeek-R1 以推理能力見長 , 在數學和復雜問題求解方面表現突出 , 同時也提供了多個蒸餾版本供資源受限的開發者使用;月之暗面(Moonshot AI)的 Kimi K2 聚焦于代碼生成和智能體任務 , 強調快速推理;智譜 AI(現更名為 Z.ai)的 GLM-4.5 則走均衡路線 , 通過多專家訓練整合推理、編程和視覺能力 。
圖丨中國開源模型在 Chatbot Arena 上的得分(來源:HAI)
芯片受限下的效率優先策略
從技術架構看 , 這些模型普遍采用了混合專家(Mixture of Experts , MoE)架構 。 MoE 的核心優勢在于效率 , 它能讓模型在有限的計算資源下獲得更好的性能 , 訓練和推理速度都更快 。 這并非巧合 。
由于美國自 2022 年起對先進 AI 芯片實施出口管制 , 中國開發者被迫在算力受限的條件下尋找替代方案 。 DeepSeek 在 2024 年底和 2025 年初發布的模型 , 正是 MoE 架構的標桿應用 。 以 DeepSeek-V3 為例 , 雖然總參數量高達 6710 億 , 但單次推理僅激活 370 億參數 , 既保證了性能 , 又大幅降低了運行成本 。
另一個值得關注的轉變是許可證條款的自由化 。
【中國AI模型是否已超越全球同行?斯坦福報告繪制中國開源AI全景圖】2024 年發布的 Qwen 2.5 曾對最小和最大規格的模型施加了研究用途限制 , 同期的 DeepSeek V3 也限制了商業使用和再分發 。 但到了 2025 年 , Qwen3 和 DeepSeek R1 全部采用了最寬松的開源許可證 , 前者是 Apache 2.0 , 后者是 MIT License 。 這種轉變的背后 , 既有吸引全球開發者社區的商業考量 , 也有中國開發者希望借開放姿態在國際 AI 圈建立學術信譽的訴求 。
有意思的是 , 這場開放潮流甚至影響了此前堅持閉源路線的玩家 。 百度 CEO 李彥宏曾是中國科技圈里最堅定的閉源擁躉 , 他多次公開強調私有模型的商業優勢 。 然而到了 2025 年 6 月 , 百度還是向市場妥協 , 將旗艦產品文心一言(ERNIE)4.5 以開放權重形式發布 。 用李彥宏自己的話說:“當模型開源時 , 人們出于好奇自然想嘗試一下 。 ”
政策支持與商業模式
報告作者們特別指出 , 中國官方在開放權重 AI 發展中扮演的角色復雜而微妙 。 頂層設計的支持確實存在:早在 2017 年的《新一代人工智能發展規劃》中 , “開源”和“開放”就被明確列為推動國家創新戰略的關鍵詞匯 。
2023 年 10 月發布的《全球人工智能治理倡議》和 2025 年 7 月發布的《全球人工智能治理行動計劃》 , 則將開源 AI 提升至國際話語權爭奪的高度 , 強調“平等的 AI 發展和使用權” , 與美國的出口管制形成對比 。
但報告同時也提醒讀者警惕過度簡化 。 DeepSeek 的成功似乎與政府扶持關系不大 , 這家公司脫胎于私募量化基金幻方 , 直到 V3 發布引發廣泛關注后 , 其創始人梁文鋒才進入更廣泛的公眾視野 。
換句話說 , 中國開放權重 AI 的繁榮更多是市場競爭、人才積累和工程文化共同作用的結果 , 而非自上而下的規劃產物 。
當然 , 政府的角色也并非完全缺席 。 地方政府正在為參與開源社區的 AI 組織和項目提供定向財政支持;學術機構被鼓勵將開源貢獻納入科研績效考核;算力基礎設施的建設也得到了國家層面的資源傾斜 。 據不完全統計 , 已有不少地方公共服務部門將 DeepSeek 模型的本地化版本集成到相關系統中 , 這些系統通常由數據管理部門與技術伙伴負責部署和微調 。
從商業模式角度看 , 中國開放權重模型開發者正在探索多元化的變現路徑 , 但長期的規模化兌現與可持續性仍有待市場檢驗 。
阿里巴巴作為云服務提供商 , 將 Qwen 定位為“AI 操作系統” , 試圖通過企業和政府客戶對模型的采用帶動云計算業務增長 , HP、阿斯利康據稱已成為其客戶 。 新加坡國家 AI 計劃選擇基于 Qwen3 構建旗艦模型 , 可能為阿里云帶來東南亞市場的商業流量 。
DeepSeek 和智譜則走輕資產路線 , 沒有自建大規模云基礎設施 , 而是采取協作部署策略 , 為不同云和算力提供商的客戶提供本地化服務 。 總體而言 , 與西方同行類似 , 中國開發者目前仍依賴間接變現:通過廣泛采用的開放模型培育用戶基礎 , 再將其引導至付費產品和服務 。
老調子還沒唱完
報告最后用相當篇幅討論了政策影響 , 歸納為四個維度:全球獲取與依賴性、AI 治理、AI 安全、地緣政治競爭 , 毫無疑問的又是美國智庫討論中國技術議題時的標準模板 。
關于技術獲取 , 報告指出高性能中國模型的廣泛可用 , 為資源有限的低收入和中等收入國家提供了獲取先進 AI 能力的新路徑 。 當模型性能趨同于前沿水平時 , 這些國家的采用者可能更看重負擔得起、穩定可靠的服務 , 而非追逐最高基準分數 。
中國模型“夠好用”、許可證寬松、使用成本低 , 恰好契合這一需求 。 這一邏輯在發達國家同樣適用:Airbnb CEO Brian Chesky 在 11 月透露 , 公司傾向于使用 Qwen 而非 ChatGPT 為客服聊天機器人供電 , 原因很簡單:“又快又便宜” 。
治理和安全維度則再次搬出了那些熟悉的論調 。 報告聲稱使用中國模型可能“繼承內置的內容審查邏輯” , 數據“可能物理傳輸至中國” , 面臨“被政府或商業競爭對手獲取的風險” 。 在安全層面 , 報告引用美國政府 AI 測試中心 CAISI 的評估稱 DeepSeek 模型被越獄攻擊突破的概率是美國同類模型的 12 倍 。
最后一個維度依舊是地緣政治競爭 。 DeepSeek R1 的發布直接改變了美國對開放權重 AI 的政策態度 。 特朗普總統稱其為“警醒時刻” , 白宮 AI 事務負責人 David Sacks 則將其作為推行聯邦層面 AI 去監管政策的依據 。
2025 年 7 月 , 白宮發布《美國 AI 行動計劃》 , 將開放權重模型提升為戰略資產 , 同時強調加強對中國等對手的出口管制 。 一個月后 , OpenAI 時隔近六年首次發布開放權重模型 , 采用 Apache 2.0 許可證——Sam Altman 在與記者的晚餐中坦承 , 中國開源模型的競爭是促使他們做出這一決定的重要因素:“如果我們不這么做 , 世界將主要建立在中國開源模型之上 。 這確實是我們決策中的一個重要考量 。 ”
當然 , 盡管這份報告離不開這些模板化的框架 , 但其價值仍在于它提供了一個相對完整的圖景:中國開放權重 AI 生態系統的參與者多元 , 包括 DeepSeek、阿里巴巴這樣的明星 , 也包括智譜、月之暗面、百川、零一萬物等一眾“小巨頭” , 以及北京智源人工智能研究院這樣的非營利機構;它們的技術路線各有側重 , 許可證策略趨向寬松 , 商業模式仍在摸索;政府支持確實存在 , 但并非唯一驅動力;全球擴散已成事實 , 政策影響正在顯現 。
對于那些仍將 DeepSeek 視為“中國 AI 的全部故事”的觀察者而言 , 這份報告是一次必要的校準 。 而對于那些試圖以簡單的“趕超”或“落后”敘事框定中美 AI 競爭的人來說 , 它提供了更多需要消化的復雜性:當模型能力差距縮小 , 真正的競爭會越來越像生態競爭、工程競爭、成本競爭與合規競爭疊加的系統戰 。 把這些變量看清楚 , 才更接近“中文模型是否超越全球同行”這個問題在產業層面的真實答案 。
參考資料:
1.https://hai.stanford.edu/policy/beyond-deepseek-chinas-diverse-open-weight-ai-ecosystem-and-its-policy-implications
運營/排版:何晨龍
推薦閱讀
















- 國產AI芯片看兩個指標:模型覆蓋+集群規模能力 | 百度智能云王雁鵬
- 火山引擎發布豆包大模型1.8,多模態Agent能力進入全球第一梯隊
- 掃地機器人鼻祖iRobot破產落幕 CEO自曝:創新滯后中國四年
- 7年輪回,中企再遭美黑手?35項卡脖技術突破,中國科技霸氣反擊
- OpenAI發布新旗艦圖像生成AI模型GPT Image 1.5
- 大模型的進化方向:Words to Worlds | 對話商湯林達華
- 大模型真懂你嗎?楊立昆最新論辯:它連貓的智能都還不如
- 智能化與全球化并進,IBM中國下一個40年思考
- 人車家全生態持續破圈,小米宣布對開發者開放小米MiMo大模型
- 文生3D來了,騰訊混元發布并開源世界模型1.5