
文章圖片

文章圖片

文章圖片

文章圖片
文章圖片
文章圖片

文章圖片
文章圖片
文章圖片

文章圖片
智東西
作者 | 李水青
編輯 | 云鵬
智東西6月10日報道 , 今日 , 蘋果開發者大會WWDC25坐實了大模型版Siri跳票的消息 , 而備受期待的蘋果AI也被吐槽“拖后腿” 。
就在這兩天 , 蘋果發布的一篇關于大模型的新論文引起熱議 , 該論文試圖極力論證大型推理模型(LRMs)的徹底性崩潰 。
研發人員設計實驗測試了Claude 3.7 Sonnet、DeepSeek-R1、o3 mini等推理模型 , 得出結論:大型推理模型在處理簡單問題時存在“過度思考”問題;而當問題的復雜性上升到臨界點時 , 它們回答問題的準確性就會觸發“崩潰模式” , 甚至準確度低到接近零 。
蘋果發布論文《思維的錯覺:通過問題復雜性視角理解推理模型的優勢與局限性》
“這(論文)對大語言模型來說是相當具有毀滅性的 。 ”美國人工智能領域知名意見領袖Gary Marcus說 。
投資公司Bootstrapped創始人Ruben Hassid將論文轉發至社交平臺X上稱:“蘋果剛剛證明 , 像Claude、DeepSeek-R1和o3-mini這樣的AI‘推理’模型實際上根本不具備推理能力 。 它們只是能很好地記住模式而已 。 ”這條推文預覽了超1000萬 , 評論達到2600多條 。 知名風投Lux Capital聯合創始人兼合伙人Josh Wolfe也推薦分享了這篇論文 。
但這篇論文同時也引起了大量質疑 。 蘋果論文試圖證明 , AI推理模型是假的 , 只是模式匹配機器 。 但不少用戶提到:“我們只能等著看論文來證明人類的推理不僅僅是記憶模式了 。 ”用外網爆火的梗圖來說就是 , 就算蘋果證明了模型無法做推理和原始思考 , 但人類就能了嗎?
一些人甚至稱這篇論文是“爛文” , 并拿“用錘子敲螺絲”來形容蘋果團隊實驗的荒謬 。 有用戶通過復現蘋果團隊的實驗以證明蘋果的論證存在邏輯漏洞 , 比如游戲的規劃次數不能代表復雜度 , 大模型崩潰只是因為輸出太長等 。
另外有網友扒出論文作者的背景 , 論文聯合一作還是一名實習生 , 是弗吉尼亞理工大學計算機科學專業三年級博士生 , 這也成為質疑者的發難點 。
【蘋果AI“暴論”震動AI圈!DeepSeek、Claude等熱門大模型只是死記的模式機器?】還有不少用戶認為 , 蘋果之所以否定大模型進程是因為其自己錯過了這波AI機遇 。
論文地址:https://machinelearning.apple.com/research/illusion-of-thinking?utm_source=perplexity
一、蘋果新論文質疑DeepSeek、o3-mini推理能力首先來看實驗設計 , 蘋果團隊的大多數實驗在推理模型及對應非推理模型上進行 , 例如Claude 3.7 Sonnet(帶/不帶深度思考)和DeepSeek-R1/V3 。 團隊允許最大token預算為64k 。
測試不是基于當下主流基準測試進行的 , 因為蘋果認為這些測試受數據污染影響嚴重 , 并無法深入了解推理軌跡的結構和質量 , 因此其通過25個謎題實例進行了測試 。
1、DeepSeek、Claude在高復雜度任務上完全崩潰
謎題環境允許在保持一致邏輯結構的同時 , 精確控制組合復雜性 。 蘋果認為 , 這種設置不僅能夠分析最終答案 , 還能分析內部推理軌跡 , 從而深入了解大型推理模型的“深度思考”方式 。
對于每個謎題實例 , 團隊生成25個樣本 , 并報告每個模型在這些樣本上的平均性能 。 團隊通過調整問題規模N(表示圓盤數、棋子數、塊數或過河元素數)來改變復雜性 , 從而研究復雜性對推理行為的影響 。
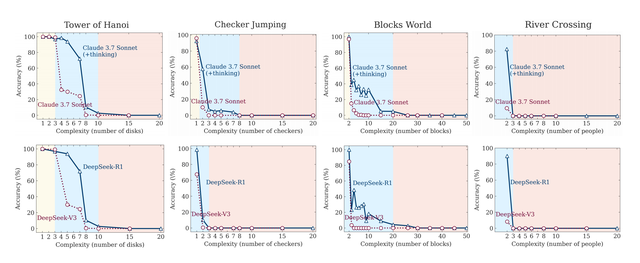
下圖展示了兩種模型類型在所有謎題環境中作為問題復雜性函數的準確性 。
下圖顯示了這些模型對在等效推理token計算下的上限性能能力 , 也就是跨所有謎題的平均值 , 將早期從數學基準的分析擴展到可控的謎題環境 。
這兩個圖的結果表明 , 與基準測試中的觀察不同 , 這些模型的行為在復雜性不同的問題中存在三種情況:
(1)在低復雜度任務上 , 標準模型的表現出人意料地優于大型推理模型;
(2)在中等復雜度任務上 , 大型推理模型的額外深度思考表現出優勢;
(3)在高復雜度任務上 , 兩種模型的表現都完全崩潰 。
2、接近復雜度臨界值 , 推理模型開始“偷懶”
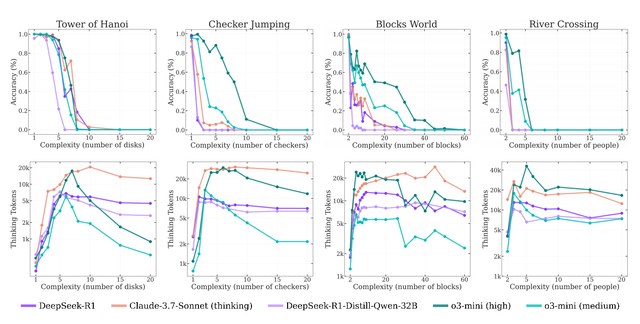
接下來 , 蘋果團隊研究了配備推理token的不同專門推理模型如何應對不斷增加的問題復雜性 。 其實驗評估了五種最先進的推理模型:o3-mini(中等和高配置)、DeepSeek-R1、DeepSeek-R1-Qwen-32B和Claude-3.7 Sonnet(深度思考版) 。
下圖展示了這些模型在不同復雜性級別上的準確性和推理token使用情況(底部) 。 結果表明 , 所有推理模型在復雜性方面都表現出類似的模式:隨著問題復雜性的增加 , 準確性逐漸下降 , 直到超過特定于模型的復雜性閾值后完全崩潰 , 準確度為零 。
團隊還觀察到 , 推理模型最初隨著問題復雜性的增加按比例增加其推理token 。 然而 , 在接近一個與它們的準確性崩潰點密切對應的臨界閾值時 , 模型違反直覺地開始減少推理努力 。
這種現象在o3-mini變體中最為明顯 , 在Claude-3.7-Sonnet(深度思考版)模型中則不那么嚴重 。 值得注意的是 , 盡管在深度思考階段運行遠低于其生成長度限制 , 并有充足的推理預算可用 , 但隨著問題變得更加復雜 , 這些模型未能利用額外的推理計算 。
這種行為表明 , 當前推理模型的思考能力相對于問題復雜性存在基本的擴展限制 。
3、推理模型內部推理拆解 , “過度思考”和“崩潰模式”
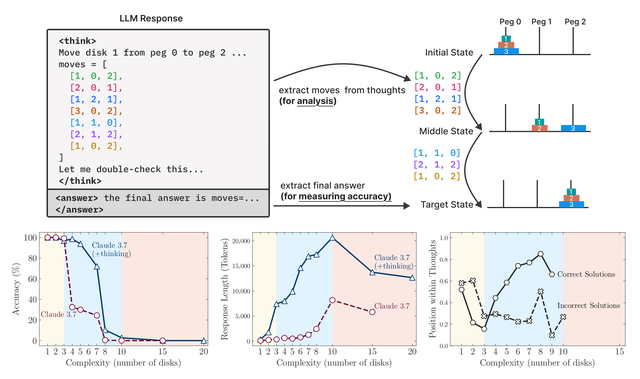
為了更深入地了解推理模型的思考過程 , 蘋果團隊對其推理軌跡進行了細粒度分析 。 他們借助謎題模擬器提取并分析模型推理中探索的中間解決方案 。
下圖中的(a)展示了所有謎題環境中中間解決方案在深度思考中的位置、正確性和問題復雜性之間的關系 。 團隊從推理軌跡中進行的分析進一步驗證了上述三種復雜性機制 。
對于較簡單的問題 , 推理模型通常在其思考的早期找到正確的解決方案 , 但隨后繼續探索不正確的解決方案 。 請注意 , 與正確解決方案(綠色)相比 , 不正確解決方案(紅色)的分布更向上方(朝向思考的末尾)移動 。 這種在文獻中被稱為“過度思考”的現象導致了計算的浪費 。
隨著問題變得中等復雜 , 這種趨勢發生了逆轉:模型首先探索不正確的解決方案 , 并且大多在思考的后期得出正確的解決方案 。 此時 , 與正確解決方案(綠色)相比 , 不正確解決方案(紅色)的分布更向下移動 。
最后 , 對于復雜性較高的問題 , 崩潰出現 , 這意味著模型無法在思考中生成任何正確的解決方案 。
上圖中的(b)對河內塔(Tower of Hanoi)環境中思考的順序段(bin)內的解決方案準確性進行了補充分析 。 河內塔游戲是一種經典的游戲 , 它有三個柱子和多個圓盤 , 玩家需要將左側柱子上的所有圓盤移動到右側柱子上 , 并且不能將較大的圓盤堆疊在較小的圓盤上 。
可以觀察到 , 對于較簡單的問題(較小的N) , 解決方案的準確性隨著思考的進行而趨于下降或波動 , 進一步證明了過度思考現象 。 然而 , 對于更復雜的問題 , 這種趨勢發生了變化 , 解決方案的準確性隨著思考的進行而增加 , 直到達到某個閾值 。 超過這個復雜性閾值 , 在“崩潰模式”下 , 準確性為零 。
4、精確計算執行面臨局限性 , “能力”忽高忽低
最后 , 蘋果團隊展示了關于推理模型在執行精確問題解決步驟方面的局限性 。
如下圖(a)和(b)所示 , 在河內塔環境中 , 即使團隊在提示中提供了算法 , 以便模型只需執行規定的步驟 , 性能也沒有提高 , 并且觀察到的崩潰仍然發生在大致相同的點 。
只要練習 , 一個聰明且有耐心的七歲小孩都能完成河內塔游戲 。 而對于計算機來說 , 這更是小菜一碟 。 但Claude幾乎不能完成7個圓盤 , 準確率不到80% , 如下圖的左下面板所示 , 而且幾乎根本無法正確完成8個圓盤 。
蘋果公司發現廣受好評的o3-min(高版本)并沒有更好 , 并且如下圖所示 , 他們在多個任務中發現了類似的結果 。 比如 , 大語言模型無法可靠地解決河內塔問題 , 但網上有很多可以免費獲取的源代碼庫 。
這值得注意 , 因為尋找和設計解決方案應該需要比僅僅執行給定算法多得多的計算 , 例如用于搜索和驗證 。 這進一步凸顯了推理模型在驗證和遵循邏輯步驟解決問題方面的局限性 , 表明需要進一步研究以了解此類模型的符號操作能力 。
此外 , 在下圖(c)和(d)中 , 團隊觀察到Claude 3.7 Sonnet推理模型的行為非常不同 。 在河內塔環境中 , 該模型在提議的解決方案中的第一個錯誤通常發生得晚得多 , 例如 , 對于 N=10 , 大約在第100步 , 而在過河環境中 , 該模型只能生成直到第4步的有效解決方案 。
值得注意的是 , 該模型在解決N=5的河內塔問題時實現了近乎完美的準確性 , 這需要31步 , 而在解決N=3的過河謎題時卻失敗了 , 該謎題有11步的解決方案 。
這可能表明 , N2的過河示例在網絡上很少見 , 這意味著大型推理模型在訓練期間可能沒有頻繁遇到或記憶此類實例 。
二、蘋果研究引起爭議:設計有邏輯漏洞 , 忽視token限制致結論失真蘋果這篇論文一經發布 , 引起了產業較多關注 , 支持和反對聲并存 。
知名風投Lux Capital聯合創始人兼合伙人Josh Wolfe轉發了這篇論文并分享了文章的主要觀點:“Claude+DeepSeek看起來很聰明 , 但當復雜性上升時它們就會……徹底崩潰” , “蘋果的看法是這些模型沒有推理能力 , 只是超級昂貴的模式匹配器 , 一旦我們超出它們的訓練分布范圍 , 它們就會崩潰”……
美國人工智能領域知名意見領袖Gary Marcus也發文稱:“它(蘋果新論文)對大語言模型來說是相當具有毀滅性的……大語言模型的擁護者已經一定程度上承認了這一打擊 。 ”
他說:“蘋果的論文最根本地表明 , 無論你如何定義通用人工智能(AGI) , 大語言模型都無法取代優秀的、規范明確的傳統算法 。 ”Gary Marcus的文章獲得了大量點贊轉發和超160條評論 。 高贊評論提到:“這篇論文是一項精妙的科學研究 , 但不幸的是 , 計算機科學界已經失去了它的精髓 。 ”
另一邊是對這篇論文猛烈的批評聲 。
一位X平臺用戶截取論文關鍵內容并稱:“所有這些都是胡說八道 , 但他們甚至懶得看輸出結果 。 這些模型實際上是在思維鏈中背誦算法 , 無論是純文本還是代碼 。 正如我在另一篇文章中解釋的那樣 , 不同游戲的步驟并不相同 。 ”
他還認為 , 蘋果團隊對游戲復雜性的定義也令人困惑 , 因為河內塔游戲只是比其他游戲多出指數級的步驟 , 這并不意味著河內塔更難 。
他復現了河內塔游戲 , 由此發現 , 所有模型在圓盤數量超過13個時的準確率都會為 0 , 因為它們無法輸出那么多(tokens) 。
“你至少需要2^N-1步 , 并且輸出格式要求每步10個token+一些常量 。 此外 , Sonnet 3.7的輸出限制為128k , DeepSeek R1為 64k , o3-mini為100k 。 這包括它們在輸出最終答案之前使用的推理token 。 ”
一旦超過7個圓盤 , 這些推理模型就不會再去嘗試推理問題 。 它會說明問題是什么以及解決它的算法 , 然后輸出其解決方案 , 甚至不會考慮各個步驟 。
他指出 , 即使對于n=9(9個圓盤)和n=10(10個圓盤) , Claude 3.7 Thinking也會提前停止推理 , 因為它認為輸出太長了 。 準確率的下降至少有一部分僅僅是因為模型認為這是浪費時間而決定提前停止 。
還有一位X平臺用戶稱:“這篇論文太爛了” , 并以比喻“他們試圖用錘子敲入螺絲 , 然后寫了一篇論文 , 講述錘子實際上是如何成為固定物品的非常有限的工具”來質疑實驗設計的效度 。
還一些觀點認為 , 蘋果完全錯過了AI的列車 , 才會來否定當下的大模型前景 。
結語:對推理模型提出質疑 , 但實驗具有局限性通過這篇論文 , 蘋果團隊對大型推理模型在已建立的數學基準上的當前評估范式提出了質疑 。
團隊利用算法謎題環境設計了一個可控的實驗測試平臺 , 由此論述當下先進的推理模型仍無法開發出可泛化的問題解決能力 , 在不同環境中 , 準確性最終會在超過特定復雜性后崩潰為零 。
與此同時 , 產業人士對論文實驗設計邏輯、論述過程、示例選擇提出了較多質疑 。 蘋果團隊也承認了研究的局限性:那就是謎題環境只代表了推理任務的一小部分 , 可能無法捕捉到現實世界或知識密集型推理問題的多樣性 。 同時 , 團隊的大多數實驗依賴于對封閉前沿大型推理模型的黑盒API訪問 , 這限制了其分析內部狀態或架構組件的能力 。
此外 , 確定性謎題模擬器的使用假設推理可以一步一步地完美驗證 。 然而 , 在結構較少的領域中 , 這種精確的驗證可能不可行 , 從而限制了這種分析對其他更可泛化推理的可移植性 。
來源:Apple、X平臺
推薦閱讀














- 從“通用智能”到“領域專家”:Gartner揭示企業AI落地的必由之路
- 微軟之后,蘋果備忘錄也支持導出MD格式了
- 蘋果實力雄厚 但為何升級版Siri卻延遲發布?
- 618驚喜再升級 三星存儲品牌日“全家桶”一站式搬回家
- 負責人開啟“微博辦公”模式,小米可穿戴業務終于要翻身了?
- 蘋果Vision Pro將支持高性能iPad游戲,但未透露具體細節
- iPhone 17系列大分裂!這次買機真的要做“選擇題”了
- iOS 26翻車實錄:液態玻璃美顏變“電老虎”,舊iPhone慎升!
- vivo S30系列火熱開售!帶你解鎖 “甜酷” 新體驗!
- 爆料Xbox掌機帶來的“手持界面”,明年有望登錄所有Windows PC