
文章圖片

文章圖片

文章圖片
文章圖片
文章圖片

文章圖片
文章圖片

文章圖片
物理學正在走向人工智能——
Meta開源發布V-JEPA 2世界模型:一個能像人類一樣理解物理世界的AI模型 。
圖靈獎得主、Meta首席AI科學家Yann LeCun親自出鏡宣傳 , 并稱:
我們相信世界模型將為機器人技術帶來一個新時代 , 使現實世界中的AI智能體能夠在不需要大量機器人訓練數據的情況下幫助完成家務和體力任務 。
那什么是世界模型呢?
簡單說 , 就是能夠對真實物理世界做出反應的AI模型 。
它應該具備以下幾種能力:
理解:世界模型應該能夠理解世界的觀察 , 包括識別視頻中物體、動作和運動等事物 。
預測:一個世界模型應該能夠預測世界將如何演變 , 以及如果智能體采取行動 , 世界將如何變化 。
規劃:基于預測能力 , 世界模型應能用于規劃實現給定目標的行動序列 。
V-JEPA 2(Meta Video Joint Embedding Predictive Architecture 2 )是首個基于視頻訓練的世界模型(視頻是關于世界信息豐富且易于獲取的來源) 。
它提升了動作預測和物理世界建模能力 , 能夠用于在新環境中進行零樣本規劃和機器人控制 。
V-JEPA 2一發布就引起了一片好評 , 甚至有網友表示:這是機器人領域的革命性突破!
62小時訓練即可生成規劃控制模型V-JEPA 2采用自監督學習框架 , 利用超過100萬小時的互聯網視頻和圖像數據進行預訓練 , 不依賴語言監督 , 證明純視覺自監督學習可以達到頂尖表現 。
上圖清晰地展示了如何從大規模視頻數據預訓練到多樣化下游任務的全過程:
輸入數據:利用100萬小時互聯網視頻和100萬圖片進行預訓練 。
訓練過程:使用視覺掩碼去噪目標進行視頻預訓練 。
下游應用分為三類:
理解與預測:行為分類、物體識別、行為預測;
語言對齊:通過與LLM對齊實現視頻問答能力;
規劃:通過后訓練行動條件模型(V-JEPA 2-AC)實現機器人操作 。
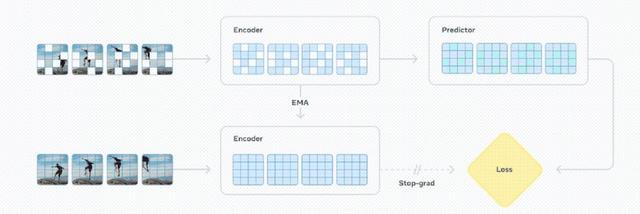
V-JEPA 2采用聯合嵌入預測架構(JEPA) , 主要包含兩個組件:編碼器和預測器 。
編碼器接收原始視頻并輸出能夠捕捉有關觀察世界狀態的語義信息的嵌入 。
預測器接收視頻嵌入以及關于要預測的額外上下文 , 并輸出預測的嵌入 。
研究團隊用視頻進行自監督學習來訓練V-JEPA 2 , 這就能夠在無需額外人工標注的情況下進行視頻訓練 。
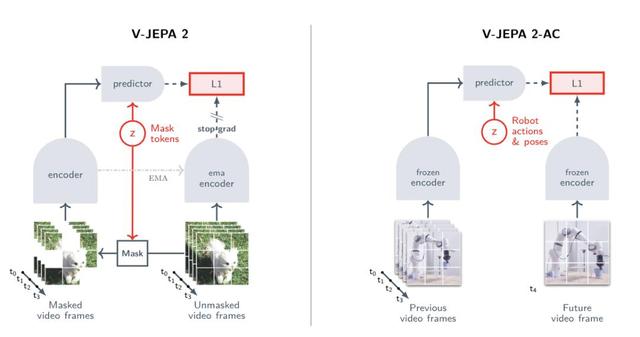
V-JEPA 2的訓練涉及兩個階段:先是無動作預訓練(下圖左側) , 然后是額外的動作條件訓練(下圖右側) 。
經過訓練后 , V-JEPA 2在運動理解方面取得了優異性能(在Something-Something v2上達到77.3的 top-1準確率) , 并在人類動作預測方面達到了當前最佳水平(在Epic-Kitchens-100上達到39.7的recall-at-5) , 超越了以往的任務特定模型 。
此外 , 在將V-JEPA 2與大型語言模型對齊后 , 團隊在8B參數規模下多個視頻問答任務中展示了當前最佳性能(例如 , 在PerceptionTest上達到84.0 , 在TempCompass上達到76.9) 。
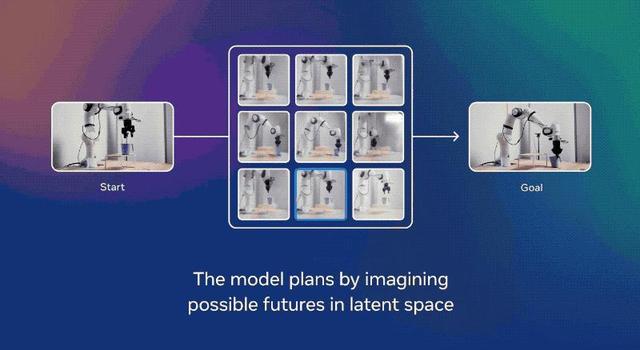
對于短期任務 , 例如拾取或放置物體 , 團隊以圖像的形式指定目標 。
使用V-JEPA 2編碼器獲取當前狀態和目標狀態的嵌入 。
從其觀察到的當前狀態開始 , 機器人通過使用預測器來想象采取一系列候選動作的后果 , 并根據它們接近目標的速度對候選動作進行評分 。
在每個時間步 , 機器人通過模型預測控制重新規劃并執行朝向該目標的最高評分的下一個動作 。
對于更長期的任務 , 例如拾取物體并將其放置在正確的位置 , 指定一系列機器人試圖按順序實現的視覺子目標 , 類似于人類觀察到的視覺模仿學習 。
通過這些視覺子目標 , V-JEPA 2在新的和未見過的環境中拾取并放置新物體時 , 成功率達到65%–80% 。
物理理解新基準Meta還發布了三個新的基準測試 , 用于評估現有模型從視頻中理解和推理物理世界的能力 。
雖然人類在所有三個基準測試中表現良好(準確率85%–95%) , 但人類表現與包括V-JEPA 2在內的頂級模型之間存在明顯差距 , 這表明模型需要改進的重要方向 。
IntPhys 2是專門設計用來衡量模型區分物理上可能和不可能場景的能力 , 并在早期的IntPhys基準測試基礎上進行構建和擴展 。
團隊通過一個游戲引擎生成視頻對 , 其中兩個視頻在某個點之前完全相同 , 然后其中一個視頻發生物理破壞事件 。
模型必須識別出哪個視頻發生了物理破壞事件 。
雖然人類在這一任務上在多種場景和條件下幾乎達到完美準確率 , 但當前的視頻模型處于或接近隨機水平 。
Minimal Video Pairs (MVPBench)通過多項選擇題測量視頻語言模型的物理理解能力 。
旨在減輕視頻語言模型中常見的捷徑解決方案 , 例如依賴表面視覺或文本線索以及偏見 。
MVPBench中的每個示例都有一個最小變化對:一個視覺上相似的視頻 , 以及相同的問題但答案相反 。
為了獲得一個示例的分數 , 模型必須正確回答其最小變化對 。
CausalVQA測量視頻語言模型回答與物理因果關系相關問題的能力 。
該基準旨在專注于物理世界視頻中的因果關系理解 , 包括反事實(如果……會發生什么)、預期(接下來可能發生什么)和計劃(為了實現目標下一步應該采取什么行動)相關的問題 。
雖然大型多模態模型在回答視頻中“發生了什么”的問題方面能力越來越強 , 但在回答“可能發生了什么”和“接下來可能發生什么”的問題時仍然存在困難 。
這表明在給定行動和事件空間的情況下 , 預測物理世界可能如何演變方面 , 與人類表現存在巨大差距 。
One More ThingMeta還透露了公司在通往高級機器智能之路上的下一步計劃 。
目前 , V-JEPA 2只能在單一時間尺度上學習和進行預測 。
然而 , 許多任務需要跨多個時間尺度的規劃 。
所以一個重要的方向是發展專注于訓練能夠在多個時間和空間尺度上學習、推理和規劃的分層次JEPA模型 。
【LeCun世界模型出2代了,62小時搞定機器人訓練,開啟物理推理新時代】另一個重要的方向是多模態JEPA模型 , 這些模型能夠使用多種感官(包括視覺、音頻和觸覺)進行預測 。
項目地址:GitHub:https://github.com/facebookresearch/vjepa2Hugging Face:https://huggingface.co/collections/facebook/v-jepa-2-6841bad8413014e185b497a6
參考鏈接:
[1
https://ai.meta.com/blog/v-jepa-2-world-model-benchmarks/
[2
https://x.com/AIatMeta/status/1932808881627148450
[3
https://ai.meta.com/research/publications/v-jepa-2-self-supervised-video-models-enable-understanding-prediction-and-planning/
推薦閱讀












- 堅持免費!夸克發布行業首個“高考志愿大模型” 還有張雪峰專欄
- 楊立昆親自發布:Meta最強世界模型開源
- 全球每賣2臺100吋就有1臺是海信!Omdia揭曉世界第一統治力
- 淘寶跑步進入三維世界
- 硅谷AI圈變天,OpenAI棄微軟轉投谷歌,LeCun被邊緣小扎組隊血戰復仇
- Mistral的首個強推理模型:擁抱開源,推理速度快10倍
- OpenAI發布新推理模型o3-pro,并下調o3價格
- 端側模型向開發者開放,AI在iPhone上無處不在
- OpenAI推理大模型再度上新 o3-pro已經上線
- 字節跳動推出豆包大模型1.6和視頻模型Seedance 1.0