
文章圖片

文章圖片

文章圖片

文章圖片
文章圖片
【何愷明改進了謝賽寧的REPA:極大簡化但性能依舊強悍】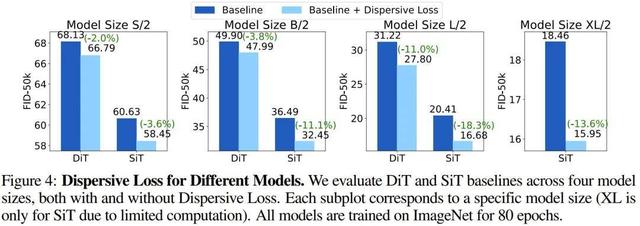
文章圖片

文章圖片
機器之心報道
編輯:Panda
在建模復雜的數據分布方面 , 擴散生成模型表現出色 , 不過它的成果大體上與表征學習(representation learning)領域關聯不大 。
通常來說 , 擴散模型的訓練目標包含一個專注于重構(例如去噪)的回歸項 , 但缺乏為生成學習到的表征的顯式正則化項 。 這種圖像生成范式與圖像識別范式差異明顯 —— 過去十年來 , 圖像識別領域的核心主題和驅動力一直是表征學習 。
在表征學習領域 , 自監督學習常被用于學習適用于各種下游任務的通用表征 。 在這些方法中 , 對比學習提供了一個概念簡單但有效的框架 , 可從樣本對中學習表征 。
直觀地講 , 這些方法會鼓勵相似的樣本對(正例對)之間相互吸引 , 而相異的樣本對(負例對)之間相互排斥 。 研究已經證明 , 通過對比學習進行表征學習 , 可以有效地解決多種識別任務 , 包括分類、檢測和分割 。 然而 , 還沒有人探索過這些學習范式在生成模型中的有效性 。
鑒于表征學習在生成模型中的潛力 , 謝賽寧團隊提出了表征對齊 (REPA)。 該方法可以利用預訓練得到的現成表征模型的能力 。 在訓練生成模型的同時 , 該方法會鼓勵其內部表征與外部預訓練表征之間對齊 。 有關 REPA 的更多介紹可閱讀我們之前的報道《擴散模型訓練方法一直錯了!謝賽寧:Representation matters》 。
REPA 這項開創性的成果揭示了表征學習在生成模型中的重要性;然而 , 它的已有實例依賴于額外的預訓練、額外的模型參數以及對外部數據的訪問 。
簡而言之 , REPA 比較麻煩 , 要真正讓基于表征的生成模型實用 , 必需一種獨立且極簡的方法 。
這一次 , MIT 本科生 Runqian Wang 與超 70 萬引用的何愷明出手了 。 他們共同提出了 Dispersive Loss , 可譯為「分散損失」 。 這是一種靈活且通用的即插即用正則化器 , 可將自監督學習集成到基于擴散的生成模型中 。
- 論文標題:Diffuse and Disperse: Image Generation with Representation Regularization
- 論文鏈接:https://arxiv.org/abs/2506.09027v1
直覺上看 , 分散損失會鼓勵內部表征在隱藏空間中散開 , 類似于對比學習中的排斥效應 。 同時 , 原始的回歸損失(去噪)則自然地充當了對齊機制 , 從而無需像對比學習那樣手動定義正例對 。
一言以蔽之:分散損失的行為類似于「沒有正例對的對比損失」 。
因此 , 與對比學習不同 , 它既不需要雙視圖采樣、專門的數據增強 , 也不需要額外的編碼器 。 訓練流程完全可以遵循基于擴散的模型(及基于流的對應模型)中使用的標準做法 , 唯一的區別在于增加了一個開銷可忽略不計的正則化損失 。
與 REPA 機制相比 , 這種新方法無需預訓練、無需額外的模型參數 , 也無需外部數據 。 憑借其獨立且極簡的設計 , 該方法清晰地證明:表征學習無需依賴外部信息源也可助益生成式建模 。
帶點數學的方法詳解
分散損失
新方法的核心是通過鼓勵生成模型的內部表征在隱藏空間中的分散來對其進行正則化 。 這里 , 將基于擴散的模型中的原始回歸損失稱為擴散損失(diffusion loss) , 將新引入的正則化項稱為分散損失(Dispersive Loss) 。
如果令 X = {x_i 為有噪聲圖像 x_i 構成的一批數據 , 則該數據批次的目標函數為:
等式 (6) 中定義的基于 InfoNCE 的分散損失類似于前述先前關于自監督學習的論文中的均勻性損失(盡管這里沒有對表示進行 ?? 正則化) 。 在那篇論文中的對比表示學習 , 均勻性損失被應用于輸出表示 , 并且必須與對齊損失(即正則項)配對 。 而這里的新公式則更進一步 , 移除了中間表示上的對齊項 , 從而僅關注正則化視角 。
該團隊注意到 , 當 j = i 時 , 就不需要明確排除項 D (z_iz_j) 。 由于不會在一個批次中使用同一圖像的多個視圖 , 因此該項始終對應于一個恒定且最小的差異度 , 例如在?? 的情況下為 0 , 在余弦情況下為 -1 。 因此 , 當批次大小足夠大時 , 這個項在那個對數中的作用是充當一個常數偏差 , 其貢獻會變小 。 在實踐中 , 無需排除該項 , 這也簡化了實現 。
分散損失的其他變體
分散損失的概念可以自然延伸到 InfoNCE 之外的一類對比損失函數 。
任何鼓勵排斥負例的目標都可以被視為分散目標 , 并實例化為分散損失的一種變體 。 基于其他類型的對比損失函數 , 該團隊構建了另外兩種變體 。 表 1 總結了所有三種變體 , 并比較了對比損失函數和分散損失函數 。
鉸鏈損失(Hinge Loss)
使用分散損失的擴散模型
如表 1 所示 , 所有分散損失的變體都比其對應的分散損失更簡潔 。 更重要的是 , 所有分散損失函數都適用于單視圖批次 , 這樣就無需進行多視圖數據增強 。 因此 , 分散損失可以在現有的生成模型中充當即插即用的正則化器 , 而無需修改回歸損失的實現 。
在實踐中 , 引入分散損失只需進行少量調整:
- 指定應用正則化器的中間層;
- 計算該層的分散損失并將其添加到原始擴散損失中 。
該團隊表示:「我們相信 , 這種簡化可極大地促進我們方法的實際應用 , 使其能夠應用于各種生成模型 。 」
分散損失的實際表現如何?
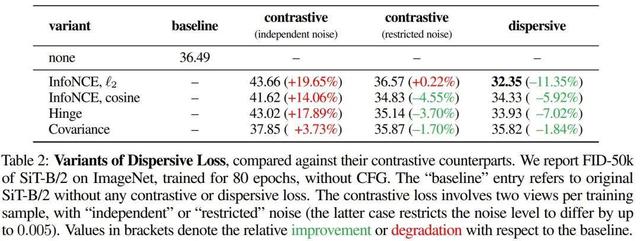
表 2 比較了分散損失的不同變體及相應的對比損失 。
可以看到 , 在使用獨立噪聲時 , 對比損失在所有研究案例中均未能提高生成質量 。 該團隊猜想對齊兩個噪聲水平差異很大的視圖會損害學習效果 。
而分散損失的表現總是比相應的對比損失好 , 而前者還避免了雙視圖采樣帶來的復雜性 。
另外 , 該團隊還研究了不同模塊選擇以及不同 λ(控制正則化強度)和 τ(InfoNCE 中的溫度)值的影響 。 詳見原論文 。
另外 , 不管是在 DiT(Diffusion Transformer)還是 SiT(Scalable Interpolant Transformers)上 , 分散損失在所有場景下都比基線方法更好 。 有趣的是 , 他們還觀察到 , 當基線性能更強時 , 相對改進甚至絕對改進往往還會更大 。
總體而言 , 這種趨勢有力地證明了分散損失的主要作用在于正則化 。 由于規模更大、性能更強的模型更容易過擬合 , 因此有效的正則化往往會使它們受益更多 。
圖 5 展示了 SiT-XL/2 模型生成的一些示例圖像 。
當然 , 該團隊也將新方法與 REPA 進行了比較 。 新方法的正則化器直接作用于模型的內部表示 , 而 REPA 會將其與外部模型的表示對齊 。 因此 , 為了公平起見 , 應同時考慮額外的計算開銷和外部信息源 , 如表 6 所示 。
REPA 依賴于一個預訓練的 DINOv2 模型 , 該模型本身是從已在 1.42 億張精選圖像上訓練過的 11B 參數主干網絡中蒸餾出來的 。
相比之下 , 新提出的方法完全不需要這些:無需預訓練、外部數據和額外的模型參數 。 新方法在將訓練擴展到更大的模型和數據集時非常適用 , 并且該團隊預計在這種情況下正則化效果會非常好 。
最后 , 新提出的方法可以直接泛化用于基于一步式擴散的生成模型 。
在表 7(左)中 , 該團隊將分散損失應用于最新的 MeanFlow 模型 , 然后觀察到了穩定持續的改進 。 表 7(右)將這些結果與最新的一步擴散 / 基于流的模型進行了比較 , 表明新方法可增強 MeanFlow 的性能并達到了新的 SOTA 。
推薦閱讀















- 如何把微信撤回時間,2分鐘改為3小時,方法簡單實用,一看就會
- 5G發牌六周年:5G-A從啟航到躍升,譜寫科技改變社會新篇
- WWDC25匯總:iOS 26外觀大改,沒有AI版Siri
- 「Next-Token」范式改變!剛剛,強化學習預訓練來了
- 剛剛!蘋果 iOS 26 正式發布,界面大改
- iOS 26 界面大改,這些機型被淘汰
- 三星大膽改革后,DRAM產量大幅提升
- 谷歌推出新功能,密碼不安全Chrome自動幫忙改
- 出售廣州LCD面板工廠股份之后 樂金顯示財務狀況明顯改善
- 三年9個并購,AMD強勢進階