文章圖片
【1200行代碼逆襲!DeepSeek工程師開源輕量級vLLM,吞吐量逼近原版】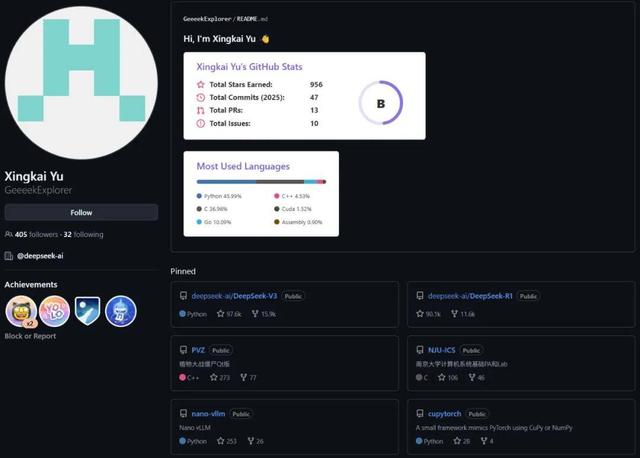
文章圖片
機器之心報道
機器之心編輯部
開源社區的人應該對 vLLM 不陌生 , 它是一個由加州大學伯克利分校團隊開發的高性能、開源 LLM 推理和服務引擎 , 核心目標是提升 LLM 的推理速度(吞吐量)和資源利用率(尤其是內存) , 同時兼容 Hugging Face 等流行模型庫 。
簡單來說 , vLLM 能讓 GPT、Mistral、LLaMA 等主流模型系列跑得更快、消耗更少資源 , 取得這些效果的關鍵是其創新的注意力機制實現方案 ——PagedAttention 。
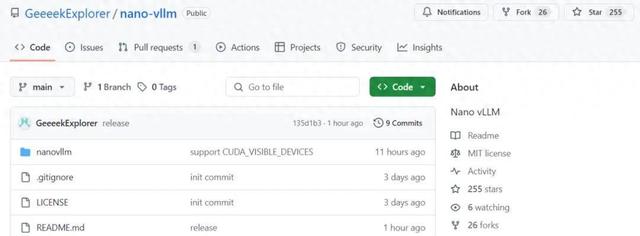
近日 , DeepSeek AI 研究者、深度學習系統工程師俞星凱從零開始構建了一個輕量級 vLLM 實現 ——Nano-vLLM , 將代碼簡化到了 1200 行 。
目前 , 該項目在 GitHub 上收獲了 200 多的 Star 。
GitHub 地址:https://github.com/GeeeekExplorer/nano-vllm/tree/main
具體來講 , Nano-vLLM 具有以下三個核心功能:
一是 , Fase 離線推理 。 推理速度與 vLLM 相當 。
二是 , 易讀代碼庫 。 實現非常簡潔 , Python 代碼減少到了 1200 行以下 。
三是 , 優化套件 。 提供 Prefix 緩存、Torch 編譯、CUDA 計算圖等功能 。
俞星凱在基準測試中采用了以下測試配置:
- 硬件:RTX 4070
- 模型:Qwen3-0.6B
- 總請求:256 個序列
- 輸入長度:100–1024 tokens 之間隨機采樣
- 輸出長度:100–1024 tokens 之間隨機采樣
作者簡介
Nano-vLLM 開發者俞星凱目前就職于 DeepSeek , 參與過 DeepSeek-V3 和 DeepSeek-R1 的開發工作 。
有意思的是 , 根據其 GitHub 主頁 , 他還曾開發過一個植物大戰僵尸 Qt 版 , 該項目也已經收獲了 270 多星 。 此外 , 由于畢業于南京大學 , 他還曾參與了不少南京大學的計算機項目 , 包括南京大學計算機圖形學繪圖系統、南京大學分布式系統 Raft 算法最簡實現、南京大學操作系統 OSLab 等 。
而根據其 LinkedIn 頁面可知 , 他曾先后在騰訊、幻方(DeepSeek 母公司)和字節跳動實習過 。 2023 年后入職 DeepSeek 成為深度學習系統工程師 。
你是 vLLM 用戶嗎?會考慮嘗試 Nano-vLLM 嗎?
推薦閱讀














- CVPR 2025 | 多模態統一學習新范式來了,數據、模型、代碼全部開源
- Cursor 1.0來襲!自動捉bug,秒改屎山代碼,AI編程分水嶺已至
- 美光以國家安全為名,請求美最高院阻止長江存儲獲得其源代碼
- 13/14代酷睿CPU還在縫縫補補:Intel再次更新微代碼 沒有行提升
- iOS18.5新代碼暗示了即將發布的新品!
- 開發者血淚控訴:千星項目被微軟“白嫖”!大量代碼相似
- AMD主板逆襲Intel:第一季占國內市場五成,Intel補救仍無用
- ?掌上娛樂新巔峰:小尺寸平板的逆襲,它值得你擁有嗎?
- 微軟50年放大招!比爾蓋茨放出157頁“鎮山之寶”BASIC源代碼!
- 從幕后到前臺:騰訊地圖自2011年以來的逆襲之路