
文章圖片

文章圖片
文章圖片

文章圖片

文章圖片

盡管大型語言模型(LLM)擁有廣泛的世界知識和強大的推理能力 , 被廣泛視為優秀的少樣本學習者 , 但在處理需要大量示例的上下文學習(ICL)時仍存在明顯局限 。
已有工作表明 , 即使提供多達上百甚至上千條示例 , LLM 仍難以從中有效學習規律 , 其表現往往很快進入平臺期 , 甚至對示例的順序、標簽偏差等較為敏感 。 在利用上下文學習解決新任務時 , LLM 往往更依賴于自身的強先驗以及示例的表面特征 , 而難以真正挖掘出示例中潛在的因果機制或統計依賴 。
這項名為 MachineLearningLM 的新研究突破了這一瓶頸 。 該研究提出了一種輕量且可移植的「繼續預訓練」框架 , 無需下游微調即可直接通過上下文學習上千條示例 , 在金融、健康、生物信息、物理等等多個領域的二分類 / 多分類任務中的準確率顯著超越基準模型(Qwen-2.5-7B-Instruct)以及最新發布的 GPT-5-mini 。
相比于已有的用于表格數據的機器學習方法 , MachineLearningLM 幾乎完全保留了 LLM 通用能力 , 這意味著它可以無縫集成到更復雜的對話工作流中 。
論文鏈接: https://arxiv.org/abs/2509.06806 模型和數據集: https://huggingface.co/MachineLearningLM 代碼: https://github.com/HaoAreYuDong/MachineLearningLM
核心創新一:百萬級合成任務「授人以漁」
研究團隊旨在賦予 LLM 一種「舉一反三」的元能力 —— 不依賴對真實任務數據的機械記憶 , 而是通過海量且多樣化的合成任務 , 從根本上訓練模型在大量上下文示例中挖掘規律并進行預測的能力 。
傳統的指令微調方法通常基于有限規模(約為千數量級)的真實任務數據 , 這在很大程度上限制了模型向新任務的泛化能力 。 與之相比 , MachineLearningLM 構建了一個超過 300 萬合成任務的大規模預訓練語料庫 。
任務生成器基于結構因果模型(Structural Causal Model SCM)來采樣生成二分類及多分類任務 。 SCM 通過有向無環圖(DAG)和結構方程(采用神經網絡與樹模型實現)明確定義變量間的因果關系 , 能夠精確控制特征的邊際分布、類型(如數值型或類別型)以及標簽生成機制 。
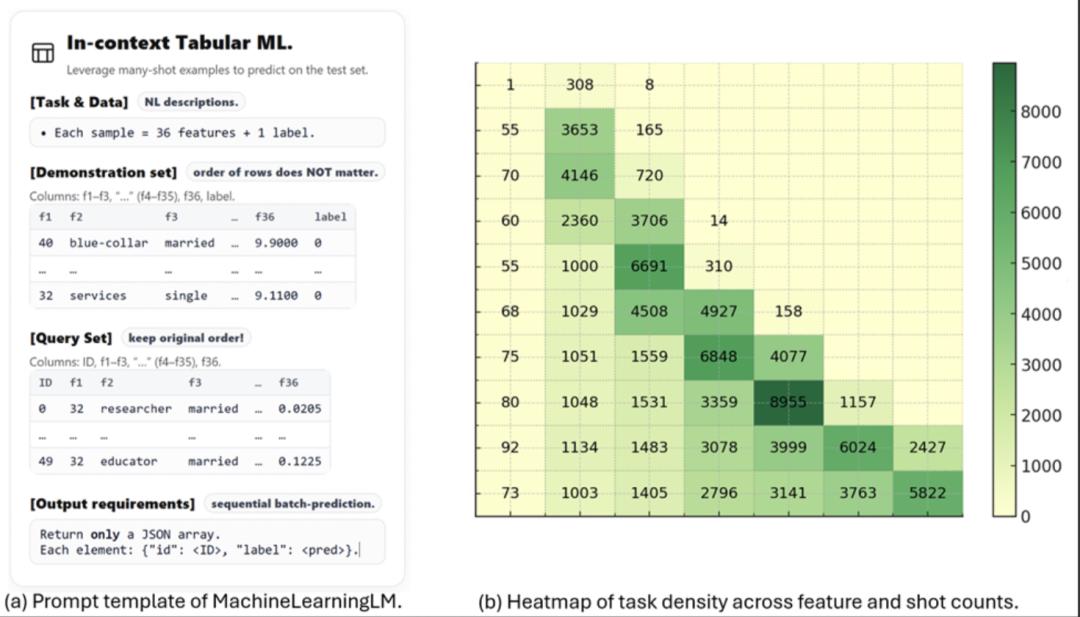
該方法確保預訓練數據與下游真實評估集沒有任何重疊 , 從而保證評估過程對模型泛化能力的檢驗具備充分公平性 。 同時 , 通過控制示例數量從數個到 1024 個不等 , 該機制能夠專門訓練模型處理「多示例」場景的推理能力 。
核心創新二:隨機森林模型「循循善誘」
在海量合成任務上直接訓練大型語言模型(LLM)容易因任務質量不一致 —— 例如存在信號微弱或類別極度不平衡等情況 —— 而導致訓練崩潰或陷入局部最優 。 為解決這一問題 , 本研究引入隨機森林(Random Forest)模型 , 利用其強大且穩健的建模能力 , 設計了如下兩級過濾機制:
樣本級共識過濾(熱身訓練階段):在熱身訓練中 , 為每個合成任務訓練一個隨機森林模型 , 并引導 LLM 學習模仿其預測行為 。 具體而言 , 僅保留隨機森林預測結果與真實標簽一致的那些樣本用于 LLM 的訓練 。 該方法通過提供清晰且高置信度的監督信號 , 使 LLM 初步建立起準確的上下文建模能力 , 尤其是數值建模能力 , 為后續過渡到自主上下文學習奠定基礎 。 任務級過濾(全程訓練階段):在整個訓練過程中 , 除為每個任務構建隨機森林模型外 , 還引入保守隨機基線(如隨機猜測或坍塌到多數類的預測方法) , 以剔除那些隨機森林表現未顯著優于基線的無效任務 。 評估指標包括機會校正一致性、失衡魯棒準確率、宏平均準確率以及避免預測坍塌等指標 。
為何選擇隨機森林?除了強大且穩健的建模能力 , 隨機森林具有高度透明的決策過程 , 可分解為清晰的規則路徑與特征重要性評估 , 這種可解釋性與 LLM 的思維鏈(Chain-of-Thought CoT)推理模式天然契合 , 有助于后續推進思維鏈預測及解釋性預測任務 。
同時 , 隨機森林能夠提供預測置信度 , 為進一步減少 LLM 幻覺問題引入置信度機制提供了可能 。
核心創新三:高效上下文示例編碼「多維擴容」
在大模型時代 , 如何高效地在上下文學習中處理海量表格數據 , 是一項重要挑戰 。 傳統的「自然語言描述」方式(例如:「收入是 29370 , 職業是博士 , 年增長率是 - 12.34% → 標簽:1」) , 占用 token 多、計算開銷大 , 嚴重限制了實際應用中可支持的示例數量;數值型特征經分詞器處理時 , 一個小數可能被拆成多個 token , 既浪費長度又可能導致數值比較錯誤 , 如模型容易誤認為「1.11」(1|.|11)比「1.9」(1|.|9)大 。
為此 , 作者提出了三項核心優化策略 , 顯著提升了上下文學習的數據容納能力與推理效率:
告別「小作文」 , 樣本用表格來組織: SpreadsheetLLM 等研究已廣泛證明 , LLM 能很好地理解結構化表格 , 因此作者放棄相關工作將結構化數據展開成冗長自然語句的做法 , 轉而采用緊湊的表格編碼格式 。
把數字「打包」成整數 , 告別 token 碎片化:先遵循機器學習工程的常見操作 , 將所有數值基于訓練集數據分布逐列進行 z-score 標準化;然后將 z-norm 下 ±4.17(絕大多數情況)的浮點數區間整體線性映射到 [0 999
的整數區間 。 這樣 , 每個數值在 GPT 和 LLaMA 3 的詞表中僅需 1 個 token 表示(Qwen 分詞器也僅需 1 到 3 個 token) , 既節省空間 , 還避免了小數點和正負號單獨切詞帶來的數值理解錯誤 。 該流程只是改進了傳統機器學習中的數值標準化 , 而沒有改變 LLM 原生分詞器 , 因此模型的數值推理能力可以全部繼承 。
推理也要「團購」:序列級批量預測——傳統上下文學習一次只處理一個查詢 , 在多樣本學習時效率極低 。 作者將多個查詢(如 50 條)拼成一條序列 , 統一前向推理 , 一次性輸出所有預測結果 。 這不僅大幅提升推理速度 , 還能在訓練階段提高自回歸穩定性 。
驚艷效果:多項能力突破
MachineLearningLM 的繼續預訓練方案無需改變模型架構或分詞器 , 只使用了 Qwen2.5-7B 基座模型和低秩適配(LoRA rank=8)這種輕量級配置 , MachineLearningLM 展現出了前所未有的上下文樣本利用能力:
「千示例」上下文學習:模型性能隨著提供的示例數量增加而持續穩定提升 , 從 8 條示例到 1024 條示例 , 準確率單調增長 。 這樣的上下文樣本效率是已有 LLM 都難以做到的 。
遠超 GPT-5-mini 等強大基準模型:在金融、生物信息、物理信號和醫療健康等領域的表格分類任務上 , 其純上下文學習的準確率平均超越 GPT-5-mini 等強大基準模型約 13 到 16 個百分點 。
在無需任何任務特定訓練的情況下 , 其準確率已能達到與需要任務級參數更新的隨機森林模型相差無幾的水平(平均相對差距在 2% 以內) , 并顯著優于 K 近鄰(kNN)算法 。
通用能力無損:最關鍵的是 , 注入 ML 能力后 , 模型原有的對話、知識和推理能力幾乎完好無損 。 在 MMLU 基準測試中 , 其零樣本準確率達 73.2% , 50 樣本設置下達 75.4% , 與基準通用 LLM(Qwen-2.5-7B-Instruct)持平 , 甚至在特定領域(如統計和物理)有一定提升 , 這意味著它可以無縫集成到更復雜的對話工作流中 。
實證研究表明 , MachineLearningLM 能夠同時處理數值特征與自然語言描述 , 無需像傳統方法那樣對文本進行分桶或轉換為嵌入向量 , 實現了真正的異構(多模態)輸入推理 。 然而 , 該模型仍存在一定局限 , 例如在面對非獨立同分布的時間序列數據以及類別數量極其龐大的數據集時 , 性能尚有待提升 , 這也為后續研究指明了改進方向 。
應用領域
基于大幅提升的多樣本上下文學習和數值建模能力 , MachineLearningLM 有望在金融、醫療健康與科學計算等廣泛場景中擴展大型語言模型的實際應用邊界 。
未來展望
MachineLearningLM 為未來研究開辟了多個充滿潛力的方向 。 以下是論文里列出的幾個重點方向:
超越文本與數字:合成多模態分類任務 , 使 MachineLearningLM 能夠直接在海量合成數據上練習處理異構信號的多模態上下文預測 , 這依然可以建立在表格預測的框架之上 , 例如利用 HTML 表格來嵌入圖像 。通過系統優化突破上下文長度限制:例如采用張量 / 流水線并行、高效內存注意力與 KV 緩存等系統優化技術 。不確定性預測 (Uncertainty):預測的同時輸出置信度(比如利用隨機森林的置信度做熱身訓練) , 以減少模型 OpenAI 近期提出的由于缺乏承認不確定性(Honesty about uncertainty)引發的幻覺(Hallucination) 。提升可解釋性 (Interpretability):敘事蒸餾與推理增強學習 , 既可以利用底層的 SCM(變量、關系與機制)作為預測任務的輔助目標 , 也可以從集成模型中蒸餾規則 , 形成緊湊、人類可讀的推理鏈條 。集成檢索增強方法(RAG):為 MachineLearningLM 集成一個檢索模塊 , 使其能在預訓練和推理時動態注入最相關的示例 。賦能智能體(Agent):與 Agent 記憶機制(Memory)深度融合 , 提升其在復雜環境中利用多樣本的上下文學習 , 賦予智能體強大的從大量經驗記憶中挖掘和學習的能力 。
作者介紹
本文作者:董浩宇(中國科學院大學)、張鵬昆(華南理工大學)、陸明哲(中國科學院大學)、沈言禎(斯坦福大學)、柯國霖(個人貢獻者)
董浩宇:中國科學院大學在讀博士(預計 2025 年底畢業) 。 研究方向涵蓋表格與半結構化數據理解與推理、LLM 后訓練與強化學習、數據集與評測基準等 。 曾提出 SpreadsheetLLM 并獲得 Hugging Face Paper of the Day、聯合發起并持續共同組織 NeurIPS 2022–2024 表格表征學習(TRL)系列研討會 , 推動表格智能社區發展 。
【MachineLearningLM給大模型上下文學習裝上「機器學習引擎」】
推薦閱讀













- 降低大模型幻覺、讓企業AI輸出更靠譜,亞馬遜云科技掏出10年家底
- App再想“偷窺”相冊?沒門!鴻蒙應用市場把選擇權還給你了
- 大模型碰到真難題了,測了500道,o3 Pro僅通過15%
- KV Cache預算降至1.5%!他們用進化算法把大模型內存占用砍下來了
- 上海AI“北斗七星”矩陣再添成果,斑馬智行元神AI大模型完成備案
- 機器人交互、金融大模型輪番上陣 服貿會上銀行展出滿滿科技感
- 快給你的相機更換個性化“皮膚” 松下Lumix S9煥新計劃正式上線
- 誰在暗中馴化大模型?
- 為了環保!蘋果再一次減配:從此AirPods耳機USB充電線都不給你
- 大模型智能體不止能寫代碼,還能被訓練成白帽黑客