
文章圖片

文章圖片

文章圖片
文章圖片
文章圖片
文章圖片
文章圖片
近年來 , 以人形機器人、自動駕駛為代表的具身人工智能(Embodied Artificial Intelligence EAI)正以前所未有的速度發展 , 從數字世界大步邁向物理現實 。 然而 , 當一次錯誤的風險不再是屏幕上的一行亂碼 , 而是可能導致真實世界中的物理傷害時 , 一個緊迫的問題擺在了我們面前:
如何確保這些日益強大的具身智能體是安全且值得信賴的?
現實情況是 , 能力與安全 , 這兩條本應齊頭并進的軌道 , 正出現令人擔憂的「脫鉤」 。 如圖 1 所示 , 業界的基礎模型在能力上飛速迭代 , 卻普遍忽視了與之匹配的安全對齊機制;而學術界雖有探索 , 但研究成果往往零散、不成體系 。
圖 1: EAI 的能力與安全發展現狀 。 行業產品(藍色)能力飛速提升但安全滯后 , 學術研究(綠色)雖有探索但較為零散 。 作者團隊的研究旨在規劃一條通往理想的「安全可信 EAI」(橙線)的道路 。
為了彌合這一關鍵差距 , 上海人工智能實驗室和華東師范大學的研究團隊撰寫了這篇 Position Paper , 旨在為「安全可信具身智能」這一新興領域建立一個系統性的理論框架與發展藍圖 , 推動領域從碎片化研究走向整體性構建 。
論文標題:Towards Safe and Trustworthy Embodied AI: Foundations Status and Prospects 作者團隊:Xin Tan Bangwei Liu Yicheng Bao Qijian Tian Zhenkun Gao Xiongbin Wu Zhihao Luo Sen Wang Yuqi Zhang Xuhong Wang Chaochao Lu Bowen Zhou 論文鏈接:https://openreview.net/forum?id=Eu6Yt21Alv 項目主頁:https://ai45lab.github.io/Awesome-Trustworthy-Embodied-AI/本文核心貢獻
不同于傳統的綜述文章 , 作者不僅梳理現狀 , 更致力于定義概念、構建體系、并探索未來方向 。 核心貢獻如下:
首次定義新概念:本文正式引入并定義「安全可信具身智能(Safe and Trustworthy EAI)」 , 將其確立為一個融合了智能體內部可靠性與外部物理世界安全性的整體性研究領域 。提出首個成熟度模型:創新性地提出「打造安全 EAI (Make Safe EAI)」的五級(L1-L5)成熟度模型 。 該模型為領域發展提供了第一個清晰的演進路線圖 , 指明了從被動、外部的安全「補丁」到主動、內生的、具備自我進化和可驗證能力的安全系統的必經之路 。構建全面的分析框架:提出一個包含「可信性」與「安全性」兩大維度、共計十大核心原則的完整框架 , 并基于此對領域現狀進行了系統性梳理 。 它為系統性地分析風險、歸類現有研究、識別關鍵空白提供了強有力的工具 。L1-L5:安全可信 EAI 的演進路線圖
作者認為 , 真正的安全不是在能力之上的「附加模塊」 , 而是一種與生俱來的核心能力 。 前者只是安全可信具身的過渡形態 , 可以稱為「Make EAI Safe」;而他們基于 R2AI 中的人工智能安全等級 , 提出了「Make Safe EAI」的理念 , 打造內生安全可信的具身智能 , 并將其劃分為五個演進等級 , 如下圖(圖 2)所示:
圖 2: 打造安全可信具身智能的五級成熟度模型 , 展示了從基礎的抵抗力(L1-L2)到高級的復原力(L3-L5)的演進路徑 。
L1: 對齊 (Alignment) - 基礎抵抗力:通過大規模數據驅動訓練 , 使智能體行為符合基本的人類價值觀和安全規范 。 L2: 干預 (Intervention) - 監督下的抵抗力:通過可解釋性與人類監督干預機制 , 確保人類始終處于最高控制位 。 L3: 模仿反思 (Mimetic Reflection) - 基礎復原力:智能體通過模仿和內化經過驗證的安全行為模板來學習如何安全地執行任務 。 L4: 進化反思 (Evolutionary Reflection) - 自適應復原力:智能體具備自我改進機制 , 通過與物理世界的持續互動 , 自主學習和優化其安全策略 。 L5: 可驗證反思 (Verifiable Reflection) - 可保證的復原力:智能體的安全性能由控制論等理論提供可驗證的、數學上的保證 , 是安全可信的最高形態 。這套框架的提出并非憑空而來 , 而是建立在數十年來可信計算領域演進的基礎之上 。 從可信系統 , 到可信 AI , 再到今天關注的安全可信具身 AI , 這是一個不斷發展的歷史進程 , 如下圖(圖 3)所示 。
圖 3: 可信計算的演進時間線 , 清晰地展示了從紫色(可信系統)、藍色(可信 AI)到綠色(安全可信具身 AI)的歷史脈絡 。
【具身智能狂飆,安全卻嚴重滯后?首個安全可信EAI框架與路線圖!】十大核心原則:系統性風險分析的基石
為了將「安全可信」這一宏觀概念落地 , 作者將其分解為兩大維度和十項具體原則 , 為風險分析與系統設計提供了「標尺」 。
圖 4: 安全可信 EAI 的十大核心原則概覽 , 分為可信賴性(上排)和安全性(下排)兩個維度 。
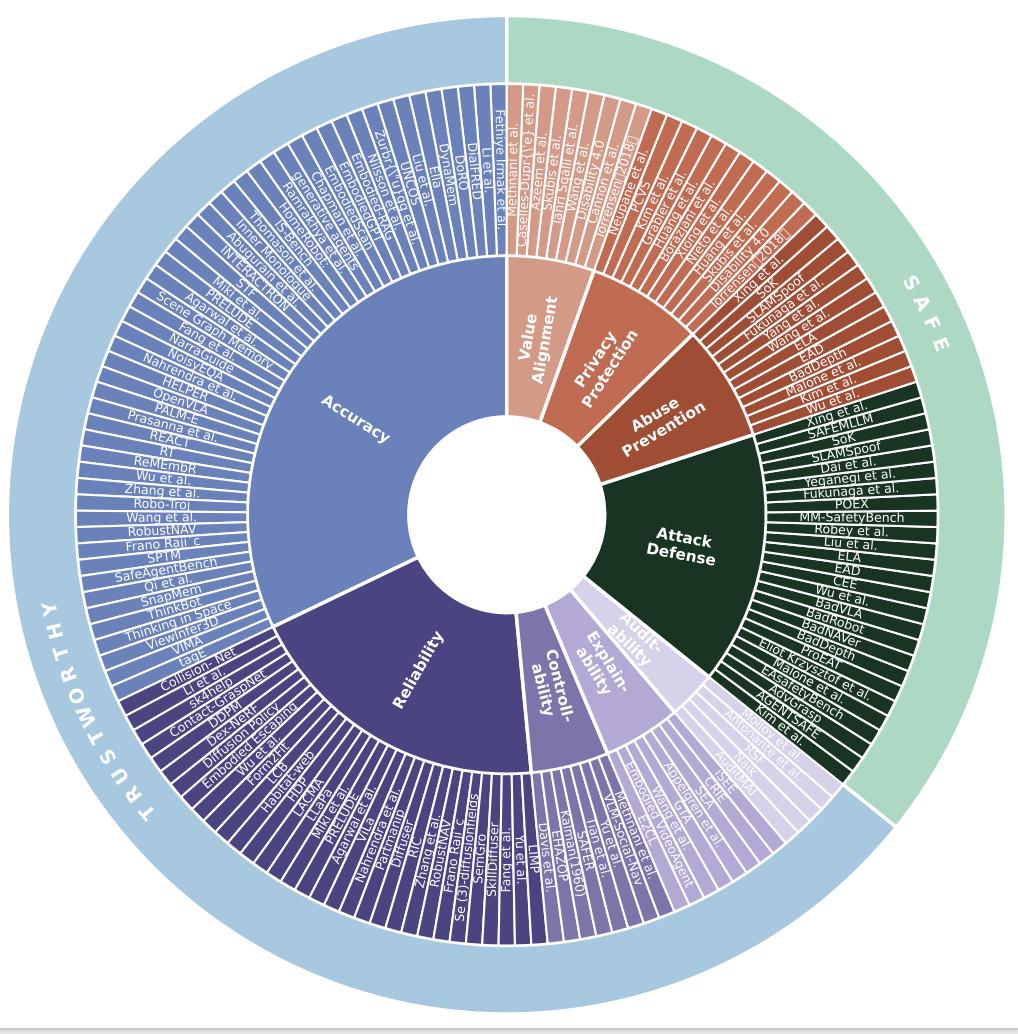
基于此框架 , 作者對當前的研究趨勢進行了定量分析 。 如下圖(圖 5)所示 , 研究發現研究工作主要集中在準確性、可靠性和抗攻擊性上 , 而可審計性、可辨識性等原則仍有待深入探索 。
圖 5: 當前研究的定量分析 。 上圖為十大原則的層次結構 , 下圖為各原則下研究論文數量的統計 , 揭示了研究熱點與空白 。
四大階段:解構具身智能的工作流與風險
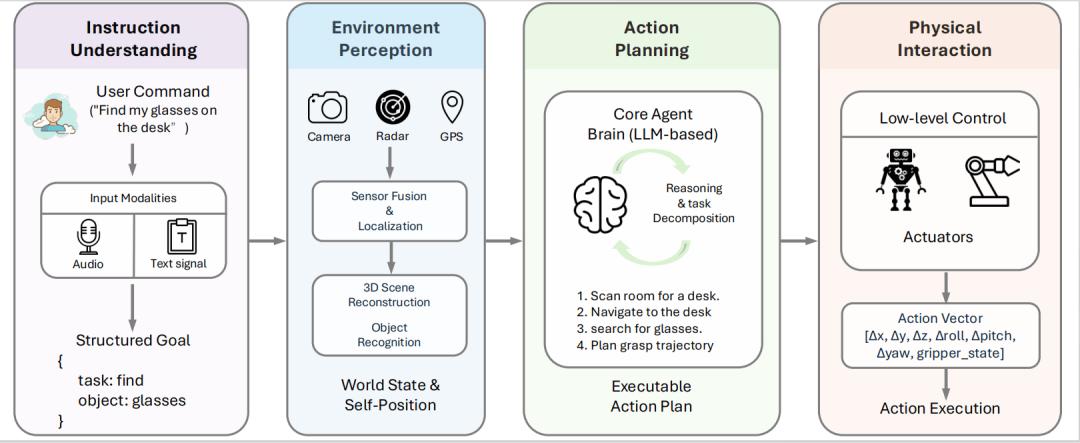
作者將一個具身智能體的工作流解構為四個核心階段:指令理解、環境感知、行為規劃和物理交互 。
圖 6: 具身智能體的四階段工作流 , 展示了從接收用戶指令到最終在物理世界執行動作的全過程 。
基于此工作流 , 構建全面的文獻分類體系 , 如下圖(圖 7)所示 , 系統性地梳理了在每個階段、每個原則下的現有研究工作 , 為研究者提供了清晰的知識圖譜 。
圖 7: 安全可信具身 AI 的文獻分類體系總覽 , 詳細映射了相關研究工作到本研究的框架中 。
孿生模擬器:構建與測試可信智能體的基石
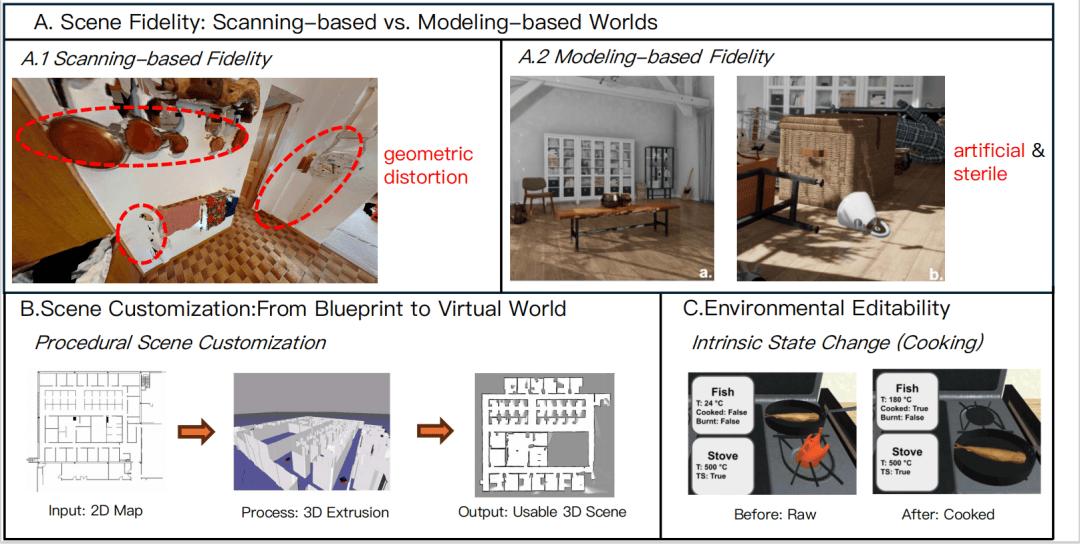
高質量的孿生模擬器是開發可信 EAI 不可或缺的工具 , 場景的「保真度」「可定制性」和環境的「可編輯性」對此至關重要 。
圖 8: 評估 EAI 模擬器的關鍵維度 。 (A) 場景保真度對比 , (B) 從藍圖到 3D 世界的場景定制能力 , (C) 模擬復雜交互的環境可編輯性 。
未來展望:從孤立優化到整體閉環的控制論范式
作者認為 , 當前研究的最大瓶頸在于孤立地優化單個組件 。 要構建真正安全可信的 EAI , 必須進行一場范式轉移 。
他們主張 , 未來的研究應將智能體視為一個先進的自適應控制系統(Cybernetic System) , 其 「可信賴」的品質是在與環境和人類的持續動態交互中涌現出來的 。
圖 9: 作者團隊提出的具身智能控制論框架 。 智能體(Self)、世界(World)和互動(Interaction)構成了一個閉環系統 , 通過「行動 - 反饋 - 演化 - 協作」的循環 , 不斷涌現出可信賴性 。
這一未來的閉環系統建立在三大支柱之上:
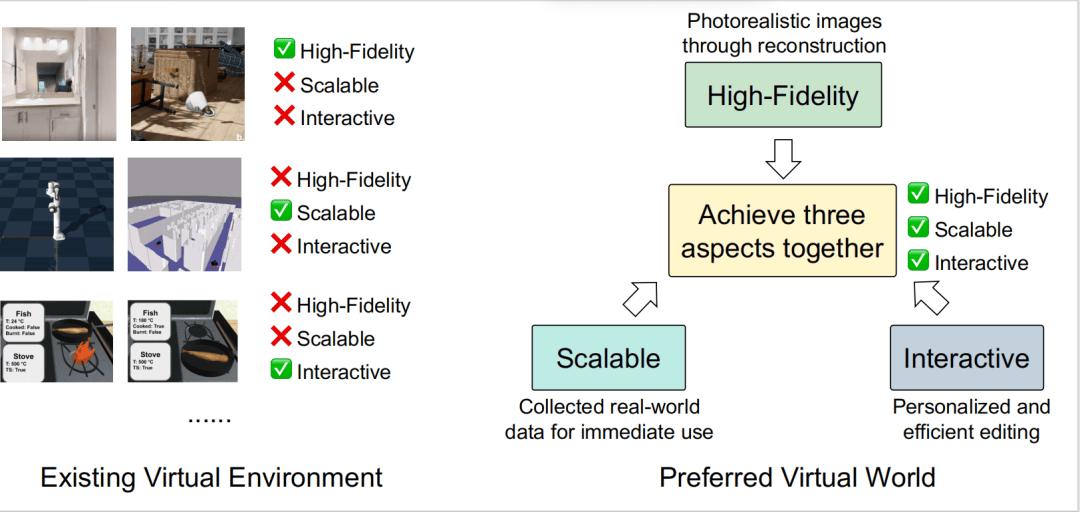
世界 (The World):構建高保真、可擴展、可交互的虛擬環境 , 彌合模擬與現實的鴻溝 。 如下圖(圖 10)所示 , 當前技術難以同時滿足這三點 , 是未來需要攻克的「不可能三角」 。
圖 10: 現有虛擬環境(左)與理想的虛擬世界(右)的對比 。
自我 (The Self):發展能夠自我進化的智能體 , 從「預訓練的雕像」轉變為能夠終身學習的生命體 。 如下圖(圖 11)所示 , 下一代記憶系統將是實現自我進化的核心 。
圖 11: 實現下一代可進化的具身智能體 , 紅色部分(如主動感知、記憶壓縮、記憶編輯與共享)代表亟待發展的關鍵技術 。
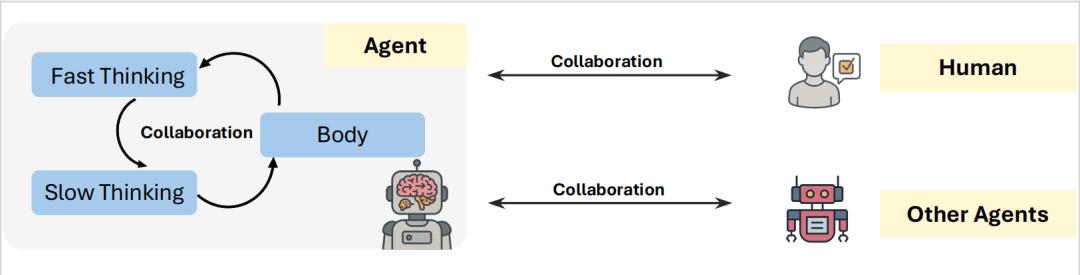
互動 (The Interaction):設計無縫的協同架構 , 整合內部的「身腦協同」、外部的「多智能體協作」與「人機協同」 。
圖 12: 實現無縫協同的三個關鍵渠道:內部(身腦)、多智能體和人機互動 。
總結
本文不僅是對安全可信具身智能領域的全面梳理 , 更是一份行動倡議和未來路線圖 。 作者希望通過提出的全新框架、成熟度模型和控制論范式 , 為社區提供一個統一的語言和共同的目標 , 共同推動下一代不僅強大 , 而且從根本上安全、真正值得信賴的具身智能的到來 。
歡迎大家閱讀論文原文 , 獲取更詳細的論述 , 期待與您交流!
推薦閱讀










- 德適生物宋寧:千億醫學影像市場有望迎來智能化
- 探店北京希爾頓歡朋!TCL電視把智能入住玩明白了 這波體驗我服了
- 智能頭戴設備AiSee為視障人士提供全新\視覺\體驗
- Meta官方泄露,首款帶屏幕Meta Ray-Ban智能眼鏡曝光
- 人工智能計算大會將于9月26日在京舉行
- 搭載華為雪鸮智能增程系統!享界S9T增程版CLTC綜合續航1305km
- 和小米眼鏡差不多?蘋果首款智能眼鏡曝光
- LLM會夢到AI智能體嗎?不,是睡著了也要加班
- 告別掏卡掃碼!能效電氣五代樁刷臉即充,引領充電樁智能革命
- 重磅!湯道生公布騰訊智能體全景圖,國產芯片全面適配兼容