文章圖片
快科技9月17日消息 , 今日凌晨 , 阿里開源旗下首個深度研究Agent模型——通義DeepResearch , 并登頂開源第一 。
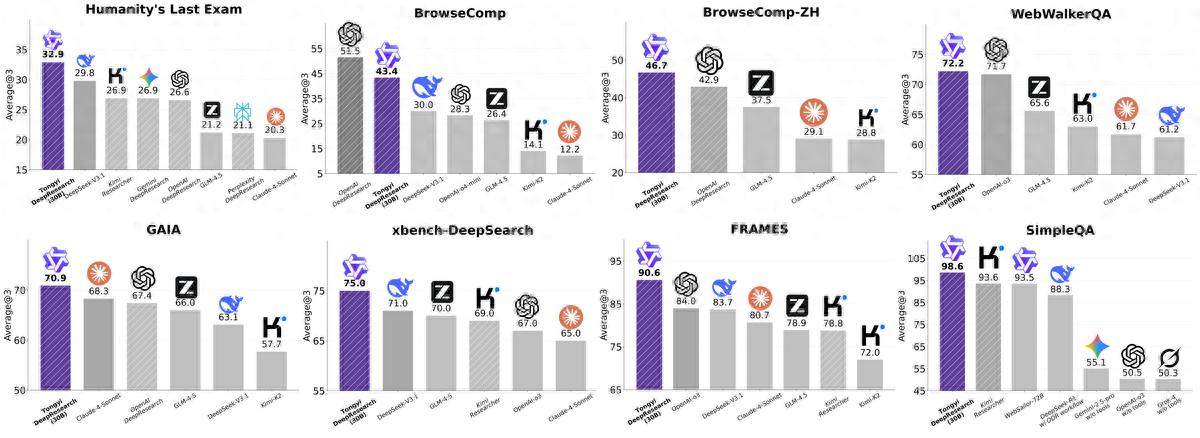
該模型在HLE、BrowseComp-zh、GAIA等多個權威評測集上取得SOTA成績(State-of-the-art) , 超越OpenAI Deep Research、DeepSeek-V3.1等Agent模型 。
目前 , 通義DeepResearch的模型、框架和方案均已全面開源 , 用戶可在Github、Hugging Face和魔搭社區社區下載模型和代碼 。
作為當前研究熱點 , “深度研究”的現有方法通常是“單窗口、線性累加”的信息處理模式 , 所有中間思路和檢索到的信息堆積在單一上下文中 。
【阿里開源通義DeepResearch:登頂開源Agent模型榜首】當處理長周期任務時 , Agent會面臨“認知空間窒息”和“不可逆的噪聲污染”的挑戰 , 導致推理能力下降 , 最終難以完成真正長程、復雜的研究任務 。
為此 , 通義團隊構建了一套以合成數據驅動、貫穿預訓練與后訓練的完整訓練鏈路 。
該鏈路以Qwen3-30B-A3B模型為基座進行優化 , 團隊創新性地設計了覆蓋真實環境與虛擬環境的RL算法驗證與真實訓練模塊 , 并結合高效異步強化學習算法及自動化數據策展(Data Curation)流程 , 顯著提升了模型的迭代速度和泛化能力 。
在推理階段 , 團隊設計了ReAct和基于自研的IterResearch的Heavy兩種模式 。
前者用于精準考察模型的基礎內在能力 , 后者則通過test-time scaling策略 , 充分挖掘并展現了模型所能達到的性能上限 。
即使在長任務中 , 也能實現高質量的推理 。
目前 , 在Humanity's Last Exam(HLE)、BrowseComp、BrowseComp-ZH、GAIA、xbench-deepsearch、WebWalkerQA以及Frames等權威Agent評測集上 , 通義DeepResearch模型以3B激活參數 , 性能超越基于OpenAI o3、DeepSeek V3.1和Claude-4-Sonnet等旗艦模型的ReAct Agent 。
今年以來 , 阿里已連續開源WebWalker、WebDancer和WebSailor等多款檢索和推理智能體 , 并全部斬獲開源SOTA成績 。
推薦閱讀















- 阿里全新AI芯片曝光:重要參數與H20相當!
- 易用易學機器人學習系統: 華為諾亞面向機器人學習開源Python框架
- 阿里媽媽發布萬相臺AI無界:新流量新節奏之下的雙11,AI是經營唯一解
- 國產AI算力崛起!消息稱阿里百度使用自研芯片訓練AI模型
- 基于通義萬相 美圖多款APP上線動漫特效、AI變身等視頻生成功能
- 遭留學生 “圍攻”后, 阿里夸克首次官方正面回應
- 永不商業化!阿里神秘項目揭曉:高德發布“高德掃街榜”
- ??B站開源IndexTTS-2.0:突破自回歸TTS時長與情感控制瓶頸
- 阿里、京東、字節等爭搶“新腦子”:人才背后的AI競賽
- 高德地圖做榜單:阿里到店業務再進一程,本地生活“背水一戰”