
文章圖片

文章圖片

文章圖片
文章圖片
文章圖片
文章圖片

文章圖片
機器之心發布
機器之心編輯部
計算速度與系統穩定性的雙重挑戰 , 正推動 AI 基礎設施向新一代集合通信技術邁進 。
在人工智能迅猛發展的今天 , 超大規模智算集群已成為推動技術突破的核心基礎設施 。
海外科技巨頭紛紛布局 , OpenAI 與甲骨文和軟銀正在推進「星際之門」項目 , 計劃配備數百萬個 GPU , 預計耗資超千億美元;微軟、谷歌、xAI 陸續完成十萬卡集群交付使用 。
在國內 , 運營商也加速向 AI 基礎底座供應商轉型 , 累計投資已超百億元 , 建成 4 個萬卡級智能計算中心 , 智算規模增長超 2 倍 。
超大規模智算集群需要應對諸多挑戰:硬件配套投入大、運營維護費用高 。 更重要的是 , 單純堆砌硬件并不能解決所有問題 , 如何設計軟件系統 , 將成千上萬個計算單元高度組織起來才是核心挑戰 。 在萬卡甚至百萬卡規模的集群中 , 設備故障幾乎成為常態而非例外 , 任何一個組件的失效都可能導致整個訓練任務中斷 , 算力利用率和系統穩定性成為比純粹算力更為關鍵的指標 。
AI 基礎設施由計算 + 通信構成 , 集合通信庫作為智算集群的 “神經系統” , 其重要性日益凸顯 。 集合通信庫是 GPU 計算芯片與高性能網絡的交匯所在 , 是 GPU 軟件棧基座組件 。 如英偉達的集合通信庫(NVIDIA Collective Communication Library , NCCL) , 可提供高性能、拓撲感知型集合運算 , 包括 P2P(Point-to-Point) Send/Recv、AllReduce、AllGather 和 ReduceScatter 等 。 這些通信原語針對 NVIDIA GPU 和各種互連產品進行了優化 , 包括 PCIe、NVLink、RoCE 以太網和 InfiniBand 。
在這種背景下 , 創智、基流、智譜、聯通、北航、清華、東南聯合打造了高效率、高可靠、高可視的 GPU 集合通信庫 VCCL(Venus Collective Communication Library) , VCCL 已部署于多個生產環境集群中 。
開源代碼與文檔倉庫:https://github.com/sii-research/VCCLVCCL 的系統架構如下圖所示 , 作為通信中間件 , 支撐訓練框架 , 兼容異構硬件設備 。 VCCL 基于 NCCL 開發 , 在通信組啟動邏輯(拓撲搜索、網絡圖構建和信道建立)之上 , 引入三個關鍵組件:
VCCL 的目標不僅是提升通信效率 , 更是要讓 GPU 算力得到最大化釋放 , 通過 DPDK-like P2P 智能調度 , VCCL 將通信任務合理卸載至 CPU , 并在 PP(Pipeline Parallel) 工作流中實現深度交疊和全局負載均衡 , 大幅縮短 GPU 空閑時間 。 實測顯示基于開源框架 Megatron-LM 的 SOTA 性能 , 使用 VCCL 后的 Dense 模型訓練端到端算力利用率可進一步提升 2%-6% 。 超大規模智算集群中 , 網絡故障幾乎是不可避免的風險源 , VCCL 設計了一套基于 Primary-backup QP 鏈接的容錯機制 , 在不增加系統負擔的前提下 , 大幅提升整體穩定性 。 通過這一機制 , VCCL 能夠將集群故障率降低超過 50% , 真正做到 “網絡出故障了也能原地拉回” , 讓大模型訓練不再輕易被打斷 。 VCCL 設計了 Flow Telemetry , 一種微妙級的 GPU 間點對點流量觀測機制 , 能夠清晰捕捉訓練過程中通信速率的細微變化 , 為研發團隊提供更細粒度的網絡可觀測能力 , 可有效解決傳統基于計數的統計方式粒度粗、準確度差的問題 , 支持定位訓練過程中的慢節點或慢鏈路 。
設計 1:DPDK-like P2P 智能調度
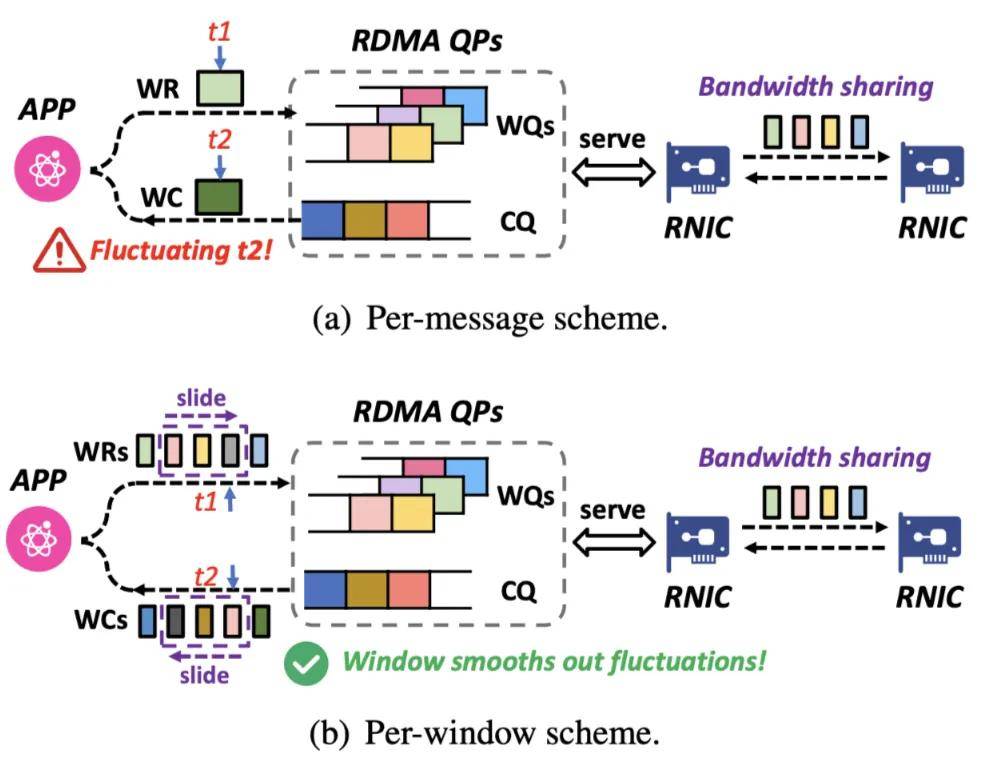
問題挑戰:P2P 通信的高 SM 占用和復雜操作 。 GPU SM(Streaming Multiprocessor)流式多處理器是英偉達 GPU 的核心計算單元 , 包含 CUDA 核心、寄存器、緩存等組件 。 編程人員編寫核函數 , 由 CUDA 運行時來進行任務調度 。 我們發現 , NCCL P2P 通信沒有涉及規約操作 , 但仍然占用了不低的 SM 資源 , 同時 NCCL P2P 操作引入多步與通信無關的操作 , 拖慢了整體性能 。 下表是使用兩臺 GPU 服務器運行 NCCL-Tests 統計的 P2P SM 資源占用情況 。 下圖是 P2P 操作中開銷統計 , 其中約 25% 的時間用于顯存拷貝 。
計算機體系結構的演進具有周期性和相似性 , 一個技術方向演進總是從功能到性能 , 架構設計也傾向于從通用到專用 。 CUDA 是一個黑盒 , 計算通信的調度效率低 , API 接口有限 , 優化難度大 , 與 Linux 內核相似 。
15 年前 , 隨著云計算發展 , 網絡數據流量以前所未有的速度增長 , 對網絡處理性能的要求也達到了極致 。 傳統的基于內核的網絡數據包處理方式已無法滿足現代高速網絡設備的需求 。 DPDK(Data Plane Development Kit) 應運而生 , 目前已運行于每一臺云數據中心的 CPU 服務器中 。 DPDK 將網絡數據平面處理從內核態遷移至用戶態 , 采用輪詢而非中斷方式進行數據收發調度 , 并通過大頁內存無鎖零拷貝的方式加速數據傳輸 。
VCCL 提出 DPDK-like P2P 設計 , 與 DPDK 優化 Linux 內核協議棧的網絡處理一致 , VCCL 對 CUDA 側的通信處理進行優化:
SM-Free P2P , 在訓練過程中 GPU 服務器的 CPU 利用率往往很低 , VCCL 繞過 CUDA 內部對 P2P 的調度和處理機制 , 將 P2P 操作卸載至 CPU 運行 , 無需啟動任何 CUDA 核函數 , 實現 SM-Free 。 SM-Free 的實現并不直接 , P2P 在 CPU 側運行缺少同步機制 , 無法保證 GPU 計算流的依賴關系 。 VCCL 采用 CUDA cudaLaunchHostFunc 編程接口 , 通過 CPU 側輪詢機制進行操作同步 , 并在工程上解決了多種隱藏卡死(Hang)問題 。 Zero-Copy P2P , 傳統 CUDA 通信中 , 會分配塊緩存(chunk buffer) , 將應用緩存(application buffer)拷貝至塊緩存 , VCCL 使用 User Buffer Registration 機制 , 通過 ncclMemAlloc 接口 , 直接將應用數據映射至網卡 。 Zero-Copy 設計也有效防止了因為多方 I/O 訪問帶來的卡死問題 。 Deep PP Overlap , VCCL SM-Free P2P 設計可以進一步消除傳統 GEMM 計算和 P2P 通信的 SM 競爭 。 這部分競爭 , 受限于 CUDA 調度機制 , 在傳統 PP 計算通信交疊中無法消除 。 VCCL SM-Free P2P 可以給計算分配更多 SM 資源 , 同時 VCCL 在 PP 切分中使能全局負載均衡 , 最終將通信深度交疊于計算之內 。
設計 2:Primary-backup QP 原地恢復容錯
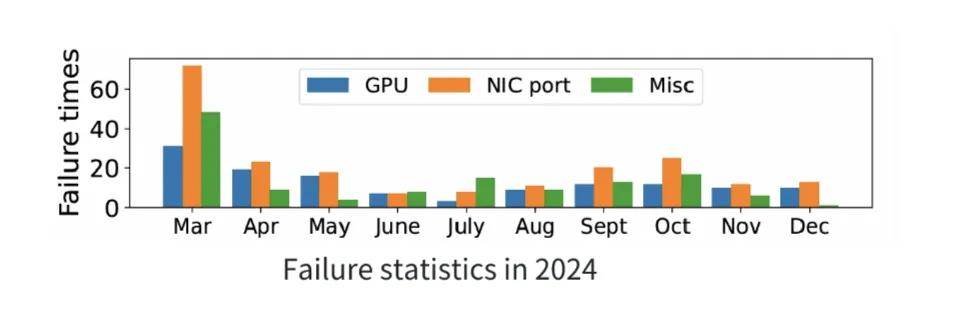
問題挑戰:網絡抖動是發生最多的故障類別 。 在大規模分布式訓練中 , 網絡抖動相關的鏈路故障(如 , 網口 Down、交換機異常等)占比超過 GPU 故障和其他故障 。 我們統計了一個數千卡規模的 GPU 集群在 2024 年 3 月至 12 月的故障情況 。 一旦發生網絡故障 , 對應的通信隊列對(QP , Queue Pair)在超時后無法繼續發送 , 會觸發 AEQ 事件并立刻進入 ERR 狀態 , 結果是整體集合通信操作被卡死(hang) , 大模型訓練直接失敗 , 待到超時時間結束 , 任務才會被 watchdog 強制退出 。
面對網絡鏈路故障 , 現有的業界方案往往難以滿足訓練過程中的即時恢復需求:
NCCL , 依賴 timeout 參數 , 往往意味著訓練中斷與長時間等待 。 checkpoint , 雖然可以縮短故障恢復時間 , 但依然需要重啟或回滾 , 無法保證訓練的連續性 。 網口聚合 , 適合應對突發的網口 Down , 無法適用于單端口集群場景 , 不支持交換機故障容忍 。VCCL 提出更通用且成本更低的 Primary-backup QP 設計 , 進行原地恢復 。 在通信組啟動過程中 , VCCL 為每一個主通信隊列對 , 建立一個備份通信隊列對 。 當網絡出現故障時 , VCCL 能在底層實時檢測 , 自動將流量無差別導向備份網口完成通信 。 整個過程無需應用層感知 , 無需額外干預 。 當原鏈路恢復后 , VCCL 會檢測并將流量切換回主通信隊列對 , 集合通信性能完全恢復 。
VCCL Primary-backup QP 設計的核心在于狀態同步和遷移 。 如下圖所示 , VCCL 使用三個指針代表收發兩端的傳輸和接受狀態 。 在發送端 , posted 代表應用準備好的數據 , transmitted 代表網絡代理準備在網卡發送的數據 , acked 代表已發送并確認收到的數據 。 在接收端 , posted 含義一致 , received 與 transmitted 對應代表準備接收的數據 , done 與 acked 對應代表確認收到的數據 。 網絡鏈路故障時 , VCCL 采用接收端驅動的機制 , 從最后一個確認的數據塊開始重傳 。 VCCL 采用定時檢測的機制 , 在完成網絡鏈路恢復時 , 切換回主通信隊列對 。
設計 3:Flow Telemetry 細粒度可視化
問題挑戰:集群故障定位與性能分析缺少有效工具 。 由于集合通信操作同時涉及 GPU 計算與網絡傳輸 , 集群任務故障發生時的大部分報錯都與 NCCL error 相關 , 包括訓練任務卡死、降速等問題 。 傳統手段需要大量人工介入 , 而且故障難以復現 , 對于大任務停集群排障是一件代價極高的事情 。 造成當前問題的核心在于 , 缺少對集合通信的細粒度且在線監測工具 , 現有的網絡監控工具都處在秒級粒度 , 而集合通信操作通常在毫秒級甚至微秒級完成 。
VCCL 提出 Flow Telemetry 設計 , 利用 RDMA 編程的細腰抽象 , 所有集合通信操作都可以拆解為微秒級 RDMA verbs 代表的網卡側數據發送傳輸語義 。 基于集合通信消息的監測采集機制 , 會因為多個消息共享鏈路帶寬而造成統計不準確問題 。 VCCL 進一步采用滑動窗口機制 , 在同一通信隊列對中 , 統計所有相關消息的平均瞬時帶寬 , 得到集合通信層的微秒級統計數據 。
VCCL Flow Telemetry 支持 GPU 間微秒級別流量探測 , 能夠清晰捕捉訓練過程中通信速率的細微變化 , 以此作為基準可進一步確定計算和通信操作的運行時間點 , 定位集群任務卡死原因 , 分析慢節點 。 同時 , Flow Telemetry 能夠實時統計端口上未完成的 RDMA WR(Work Request)數量 , 并據此推測工作隊列長度變化 , 從而精準判斷網絡是否出現擁塞 。
實驗評測
VCCL 基于 NCCL v2.21.5 實現 , 采用千卡英偉達 Hopper GPU RoCEv2 集群進行評測 , 以最佳實踐超參數運行 Megatron-LM 自帶的 GPT-2 6B、32B、70B、177B、314B 大小模型 。
DPDK-like P2P 對效率的提升
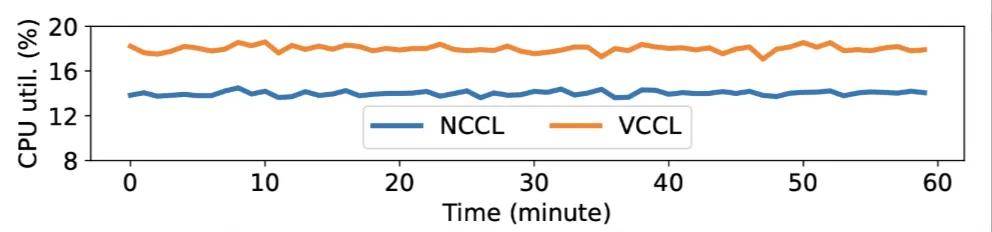
比較 VCCL 和 NCCL 的 P2P 性能 。 在不同消息大小下 , 通過 NCCL-Test 測試 VCCL 和 NCCL 的 send/recv 操作 , VCCL 在 1GB 消息大小下算法帶寬比 NCCL 提升 20.12% , VCCL 在小消息下時延比 NCCL 降低至少 28.5% 。 VCCL 在實現 P2P 操作 SM 零占用的前提下 , 對于 CPU 的使用 , 只比 NCCL 增加了 4% 。
分別使用 VCCL 和 NCCL 運行 Megatron-LM , 測試訓練準確性和算力利用率 。 VCCL 與 NCCL 的 Loos 收斂曲線一致 , VCCL DPDK-like P2P 的設計保證了計算和通信的正確調用順序 。 在不同模型大小和集群規模下 , 端到端算力利用率 VCCL 比 NCCL 有 2%-6% 提升 , 體現出 SM-Free、Zero-Copy 以及 PP 深度交疊帶來的新的性能增益 。
Primary-backup QP 對可用性的提升
采用手動方式在第 4 秒和第 19 秒之間 Down 掉網卡端口 , 在第 4 秒和第 19 秒之間 , VCCL 和 NCCL 同時在執行重試機制 , 第 14 秒后重試機制結束 , NCCL 的集合通信帶寬無法恢復 , 而 VCCL 通過切換備用通信隊列對 , 仍然可以保持 , 76.6% 的 AllReduce 帶寬和 58.1% 的 ReduceScatter 帶寬 , 19 秒后 VCCL 切換回主通信隊列對 , 性能恢復正常 。 在采用備用通信隊列對時 , Down 掉一個網卡端口 , VCCL 只引入 0.38% 的算力利用率下降 , 與正常運行時的算力利用率基本一致 。
Flow Telemetry 對可視化的提升
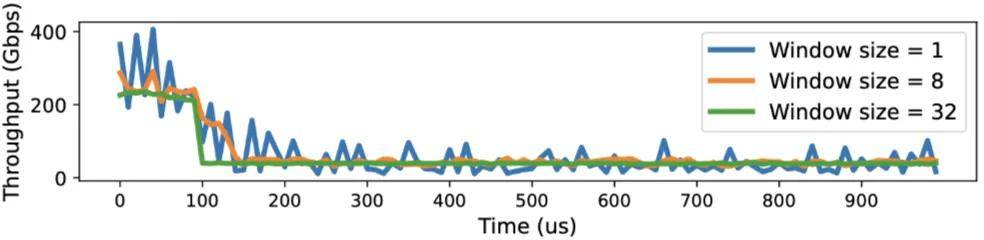
驗證 VCCL Flow Telemetry 的毫秒級監測功能 , 分別在窗口大小為 1、8、32 的情況下 , 以 10 微妙粒度呈現 P2P 吞吐量 。 當窗口大小設為 1 時 , 等價于消息粒度的監測 , 波動較大;當窗口大小為 32 時 , VCCL 可以平滑展示吞吐量 , 但缺少瞬時波動的呈現 。 實驗顯示 , 窗口大小設置為 8 時 , 可以平衡監測的準確度和平滑性 。
VCCL 部署與展望
VCCL 在實際部署過程中 , 還解決了服務器機型異構的問題 。 不同廠商的服務器 , 因 PCIe 拓撲結構差異導致跨設備連接不通及多網卡端口間流量不均衡 , 致使 RDMA 性能未達預期 。 為系統性地解決此問題 , VCCL 針對不同硬件配置設計了相應的優化方案 。
VCCL 在線運行過程中 , 用戶會遇到一些集群問題 , 包括集合通信報錯或者訓練性能下降 。 但會存在定位出的根因與通信無關的情況 , 相關案例包括:云平臺參數配置錯誤導致 CPU 核心分配不足;GPU 服務器風扇轉速配置錯誤;GPU 單卡執行任務故障等 。 這些問題字面上看似簡單 , 但集群黑盒分析起來挑戰很大 , 多維度在線故障定位與性能分析工具需要持續迭代優化 。
VCCL 的容錯機制可以更好地包容網絡硬件設備的故障 , 也為創新或國產化網絡組件上線部署提供冗余度空間 , 有效助力于算力生態發展 。
【集合通信庫VCCL釋放GPU極致算力,創智、基流、智譜等重磅開源】VCCL 讓團隊看到了更高性能、更高穩定性的集合通信庫發展機遇 , 未來 VCCL 會支持適配更多并行工作流、MoE 等模型結構、新型硬件架構 。
推薦閱讀














- 庫克尷尬了,這次中國人不愛iPhone17 Pro了?
- 庫克稱只有蘋果能做到的VC均熱,是個什么技術?
- 最強手表!華為WATCH Ultimate 2發布:首發水下聲吶通信
- 華為旗艦突然“變香了”!鴻蒙OS+衛星通信,512GB大降1500元
- 中國通信業“雙引擎”:5G-A規模化商用,AI落地按下加速鍵
- 庫克懵了,iPhone17預售:高端max受追捧,Air卻最差?
- 融資數億、核心技術全自研,這家衛星通信廠商打破海外壟斷|潛伏獨角獸
- 蘋果CEO庫克:將投資25億美元擴大康寧玻璃工廠
- 零一萬物聯合發布法務智能體平臺,推出行業首個“知識庫+工作流+AI”全棧方案
- 榮耀清倉“大跳水”,從3499元降至1860元,僅剩最后一波庫存了