
文章圖片

文章圖片
文章圖片

文章圖片
本文第一作者謝之非 , 共同第一作者馬子陽皆是來自于南洋理工大學的博士生 。 通訊作者為新加坡國立大學特聘教授顏水成和南洋理工大學數據與科學系校長講席教授苗春燕 。 共同作者為騰訊AI首席專家葉德珩和新加坡國立大學博士后研究員廖越 。
兩千多年前 , 孔子說過「三思而后行」 。 這句古老箴言 , 其實點出了人類面對復雜問題的核心智慧:一步步推理 , 層層拆解 , 最終做出可靠的決策 。
現在 , 已有諸多模型在復雜推理方面展現出顯著進展 , 如 DeepSeek-R1 和 OpenAI o1 , 部分多模態系統甚至能夠處理跨領域的復雜任務 , 展現出解決復雜現實問題的潛力 。 然而 , 在端到端對話模型中 , 推理能力尚未解鎖 。
原因并不復雜 。 深度思考意味著模型往往需要在輸出前生成完整推理鏈 , 而這直接帶來延遲 。 對于語音對話系統而言 , 速度與質量同樣關鍵 。 一旦停頓過長 , 哪怕答案再精妙 , 也會破壞交互的自然感 。
設想一個場景:你問語音助手「這份研究報告的結論可靠嗎?」 。 如果模型沉默十秒才給出語音的回復 , 則完全失去對話的體驗;若它立刻回答 , 但推理缺乏深度 , 又容易顯得表面化 。 問題在于:要么得到一個「強大但反應遲鈍」的助手 , 要么得到一個「迅速但思維簡單」的助手 。 魚與熊掌 , 似乎不可兼得 。
基于這一挑戰 , 我們提出了 Mini-Omni-Reasoner——一種專為對話場景打造的實時推理新范式 。 它通過「Thinking-in-Speaking」實現邊思考邊表達 , 既能實時反饋、輸出自然流暢的語音內容 , 又能保持高質量且可解釋的推理過程 。
論文標題:MINI-OMNI-REASONER: TOKEN-LEVEL THINKING-IN-SPEAKING IN LARGE SPEECH MODELS 論文鏈接:https://arxiv.org/pdf/2508.15827 項目主頁:https://github.com/xzf-thu/Mini-Omni-Reasoner
Mini-Omni-Reasoner: 邊思考 , 邊表達
讓我們暫時把視角放回人類自己 。 當一個人面對復雜問題時 , 往往不是「想完再說」 , 而是「邊說邊想」 。 當被問到「如何理解人工智能的未來」時 , 大多數人不會先默默推理數分鐘再完整輸出結論 , 而是會邊思考邊組織語言:「這個問題挺復雜的……我覺得可以從技術和社會兩個層面來看……」
Mini-Omni-Reasoner 正是受到這一啟發 , 探索「邊思考 , 邊表達」的新范式 。 它允許模型在生成回答的同時進行內部推理 , 實現 token 級別的思維流與輸出流交替生成 。 這樣既能保留邏輯深度與可解釋性 , 又能提供自然、低延遲的交互體驗 。
「一心二用」——如何在大模型中實現?
「Thinking-in-Speaking」推理范式:傳統推理模型遵循「thinking-before-speaking」路線:先完整生成推理鏈 , 再一次性給出答案 。 邏輯雖完整 , 但交互性差 , 用戶必須等待較長時間 。 尤其在語音交互場景下 , 這種長時間的停頓極大削弱了使用體驗 。
Mini-Omni-Reasoner 提出的則是「thinking-in-speaking」范式 。 模型在生成過程中同時維護兩條流:回答流(response stream)和推理流(reasoning stream) 。 二者像兩支交錯前進的隊伍 , 一邊輸出用戶可聽到的回答 , 一邊在后臺繼續進行邏輯演算 。
通俗理解為:模型循環輸出 p 個回答 token + q 個推理 token , 直到完成任務 。 用戶感受到的是自然、幾乎無停頓的對話 , 而模型在內部始終維持嚴謹的推理鏈 。 整個推理過程如下 。
這種機制突破了「要么快 , 要么準」的二元困境 , 讓「會想、會說」真正成為可能 。
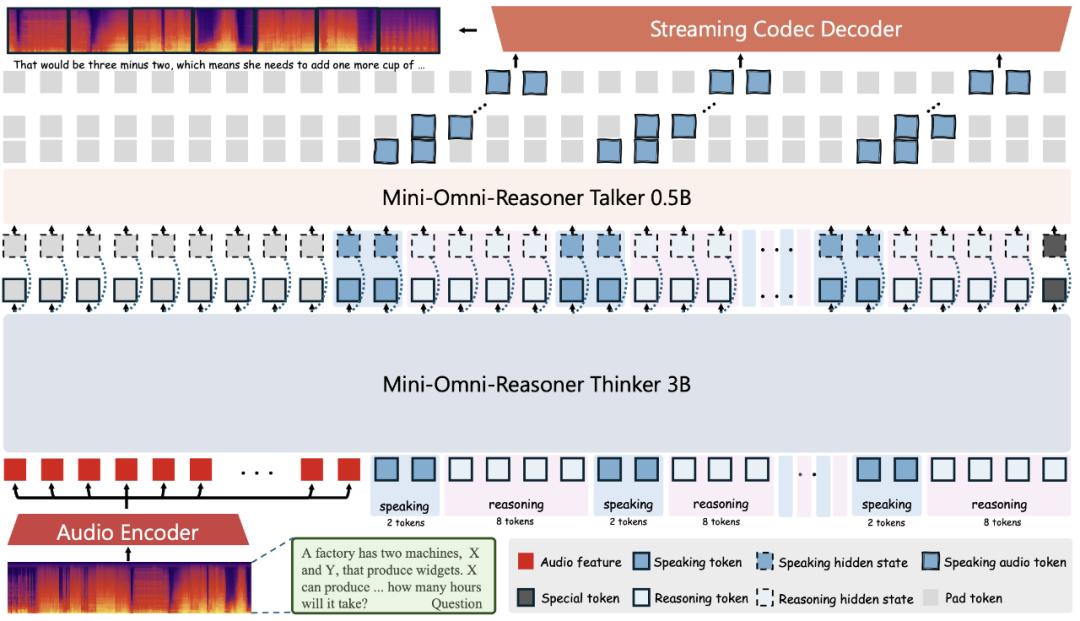
模型架構:Mini-Omni-Reasoner 采用了 Thinker-Talker 架構 , 像一對分工明確的搭檔:
Thinker:大腦擔當 , 負責語音理解和邏輯推理 , 交替產出回答 token 和推理 token 。 內部結構是「音頻編碼器 + 大模型」 。
Talker:嘴巴擔當 , 只負責把回答 token 變成語音 , 而對推理 token 保持沉默 , 確保輸出始終簡潔、自然 。
這種解耦方式的好處很直觀:Thinker 全力搞邏輯 , Talker 專心搞對話 , 誰也不分心 。
2:8 Token 交替設計:我們最終選擇了 2:8 的回答–推理 token 比例 , 背后有幾層考量:
推理比例更高 → 思維更完整 , 但可能反應太慢 , 實時性差 。
回答比例更高 → 說得快 , 但容易「說過頭」 , 邏輯沒跟上 , 甚至產生幻覺 。
Chunk 過長 → 不管是全推理還是全回答 , 都會帶來延遲或質量問題 。
結合實驗結果 , 我們發現推理鏈長度大約是回答的 2~3 倍 , 因此 2:8 是一個平衡點:既保證推理深度 , 又能保持實時語音合成的流暢性 。 比如 , 當模型每秒生成 50 token , 就能給用戶帶來 10 個回答 token——對實時對話來說已經非常充裕 。
「點石成金」——四階段數據合成管線
僅有架構還不夠 , 要真正掌握「邊思考邊表達」 , 還需要精心設計的數據與訓練流程 。 為此 , 我們構建了 Spoken-Math-Problems-3M 數據集 , 并設計了嚴謹的數據管線 。
在數據構建中 , 我們面臨一個核心挑戰——解決**「邏輯錯位」(Anticipation Drift)**問題 。 即如何防止模型在回答時「搶跑」 , 說出推理流中尚未得出的結論 。 我們為此設計了兩大核心策略:
異步推理機制:我們在數據層面「教會」模型一種新的說話藝術 。 在回答流中 , 先說一些「鋪墊語境」的話 , 為后續的推理爭取時間;而在推理流中 , 則要求模型「開門見山」 , 直奔主題 , 不講廢話 。
反序列化驗證:我們像一位嚴格的考官 , 將所有交錯的 token 重新組合成自然語言文本 , 然后利用強大的 GPT 模型進行語義和時間一致性檢查 , 剔除所有邏輯不連貫或存在「超越」現象的不合格樣本 。
通過上圖中的四階段數據管線 , 我們為 Mini-Omni-Reasoner 提供了超過百萬份高質量的訓練數據 。
「百煉成鋼」——五階段訓練方法
訓練 Mini-Omni-Reasoner 需要一個精心設計的五階段管線 , 因為模型不僅引入了定制化架構 , 還采用了全新的輸出形式 。 為了確保穩定收斂并有效將文本推理能力遷移到語音 , 我們將訓練過程分解為五個逐步遞進的階段 , 總體思路為先在文本模態中保持或增強推理能力 , 再將其與語音模態對齊 。
對齊訓練:我們從 Qwen2.5-Omni-3B 初始化模型 , 解決架構不兼容問題 , 并先只微調音頻適配器 , 使用語音問答和對話數據橋接語音編碼器與 LLM 主干的接口 , 然后解凍除音頻編碼器外的所有模塊 , 適應新加入的特殊 token , 確保模型在定制化 token 格式下無縫工作 。
混合數學預訓練:在模型對齊后 , 我們增強其數學推理能力 , 使用標準的「先推理再說話」數據集(包括文本和語音形式)進行預訓練 , 確保在引入 token 級交錯生成之前具備扎實的推理能力和數據對齊 。
文本 thinking-in-speaking 訓練:在文本模態中訓練模型交替生成推理 token 和回應 token , 僅更新語言模型參數 , 專注于掌握交錯推理-回應結構 , 不涉及語音變化 。
語音 thinking-in-speaking 訓練:將輸入替換為語音 , 僅微調音頻編碼器 , 保持 LLM 固定 , 使模型能夠在語音條件下保持推理增強的生成方式 , 實現推理范式在模態間的遷移 。
Talker 訓練:最終階段訓練說話模塊 , 實現流暢自然的語音生成 , 整個 Thinker 組件凍結 , 僅訓練 Talker 以將交錯輸出轉換為語音 , 同時保留前面階段建立的邏輯基礎和推理能力 。
「真金火煉」——實驗數據與案例分析
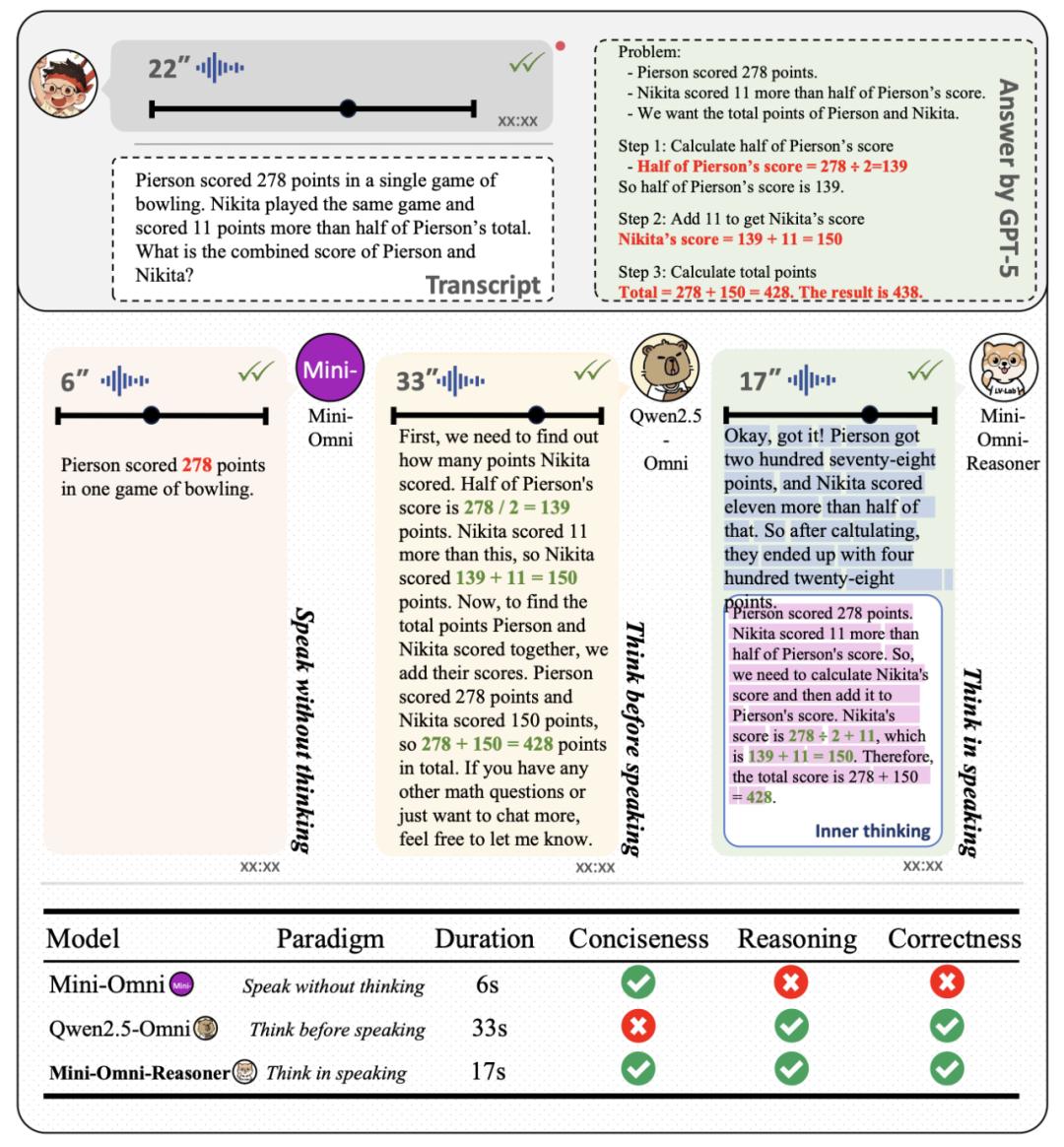
為了驗證 Mini-Omni-Reasoner 的有效性 , 我們在 Spoken-MQA 數據集上測試了模型與多種不同類型方法的對比 , 模型相比于基座模型 Qwen2.5-Omni-3B 有明顯的性能提升 。
為了進一步展現 Mini-Omni-Reasoner 與傳統的對話模型和基礎模型 Qwen2.5-Omni 模型的區別 , 我們分析了針對同樣問題不同模型的回答結果:實驗證明「Thinking-in-Speaking」方法可以有效地在保持回復內容自然簡潔的情況下保持高質量的推理過程 。
結語
當下 , 大模型的推理能力已逐漸成為解決復雜問題的核心驅動力 。 但遺憾的是 , 這一能力在對話系統中仍未被真正釋放 。 為此 , 我們提出了 Mini-Omni-Reasoner——一次早期的嘗試 。 誠然 , 它距離成熟應用還有很長的路要走 , 但「thinking-in-speaking」的實時推理機制 , 我們相信正是對話模型邁向復雜問題解決的必經之路 。
展望未來 , 我們認為至少有幾個值得深入探索的方向:
如何科學地評測模型在通用問題上的推理增益 , 如「人生的意義是什么」; 如何讓對話模型自主決定何時需要「思考」; 如何突破固定比例生成 , 探索更靈活多樣的思維范式 。
【Mini-Omni-Reasoner:實時推理,定義下一代端到端對話模型】總的來說 , Mini-Omni-Reasoner 并非終點 , 而是一個起點 。 我們更希望它能成為拋磚引玉 , 引發學界和產業界對「對話中的推理能力」的持續關注與探索 。
推薦閱讀













- 攻克大模型訓推差異難題,螞蟻開源新一代推理模型Ring-flash-2.0
- 登頂多模態推理榜MMMU,UCSD新方法超越GPT-5、Gemini
- 讓機器人「不只是走路」,Nav-R1引領帶推理的導航新時代
- AI在實時視頻里秒“剪”出你想要的部分,輸入文字、圖、視頻片段,它都能秒懂
- 清華、上海AI Lab等團隊發布推理模型RL綜述,通往超級智能之路
- AirPods Pro 3發布!支持測心率,還能實時翻譯!
- 英偉達深夜突放大招,全新GPU為長上下文推理而生
- 馬斯克xAI自研推理芯片曝光,代號X1、臺積電3納米工藝、明年就量產
- 視頻理解新標桿,快手多模態推理模型開源
- AI生成蘋果Metal內核,PyTorch推理速度提升87%