
文章圖片

文章圖片

文章圖片
文章圖片

文章圖片

文章圖片

文章圖片

文章圖片
設想一下剛學開車的情況:在訓練場上 , 我們可能會反復練習特定動作:到了某個位置就踩剎車 , 拐到某個點就打方向盤 。 久而久之 , 這些動作會形成 “條件記憶” , 一旦環境發生變化 , 就容易手忙腳亂 。 最近 , 千尋智能的研究人員注意到 , 基于模仿學習的視覺運動策略中也存在類似現象 , 并在論文《Do You Need Proprioceptive States in Visuomotor Policies?》中對此進行了深入探討 。
論文鏈接:https://arxiv.org/abs/2509.18644 項目主頁:https://statefreepolicy.github.io
文中研究人員提出了一種名為 State-free Policy 的策略 , 與 State-based Policy 相比 , 即便在訓練數據中桌面高度、機器人位置和目標物體等都被嚴格固定的情況下 , 機器人仍能展現出強大的空間泛化能力 。 例如:
在夾筆任務中 , 獲得桌面高度的泛化能力(標準桌高為 80 cm):
在疊衣服任務中 , 即使機械臂位置大幅偏離標準位置 , 機器人仍然能出色完成任務:
【純視覺VLA方案從有限數據中學到強大的空間泛化能力】在全身機器人從冰箱拿飲料的過程中 , 即使冰箱位置發生移動 , 機器人也能夠適應:
事實上 , 在機器人操作領域 , 基于模仿學習的視覺運動策略已經被廣泛應用 。 不過 , 為了實現精確而可靠的控制 , 這類模型通常不僅依賴對任務環境的視覺觀察 , 還會引入所謂的 “狀態” 信息 —— 包括末端執行器的位置、關節角度等自身感知數據 。 這些狀態信息能夠為策略提供緊湊且精確的機器人姿態描述 , 但同時也帶來一個問題:模型容易通過記憶訓練軌跡而產生過擬合 , 從而嚴重限制空間泛化能力 。 尤其在當前環境下 , 獲取大量包含位置泛化的真機數據成本極高 , 這已經成為制約視覺運動策略發展的關鍵瓶頸 。
State-free Policy 的工作條件
為了應對空間泛化能力差的問題 , 研究人員提出在視覺運動策略的輸入中完全移除狀態信息 , 僅依賴視覺觀察 , 這一策略被稱為 “State-free Policy” 。 該方法基于兩個關鍵條件:一是動作在相對末端執行器空間中表示;二是確保視覺輸入能夠覆蓋任務所需的完整觀察范圍 , 即完整的任務觀察:
1. 相對末端動作空間:在這種動作表示空間下 , 模型根據輸入預測當前末端執行器應該進行的相對移動 , 例如向 x 方向移動 1 厘米 , 而不是直接預測末端執行器相對于機器人本體的具體位置 。 這樣的表示方式可以讓策略更專注于動作的相對變化 , 而不是依賴精確的全局位置信息 , 從而降低對狀態輸入的依賴 , 提高在不同環境下的泛化能力 。
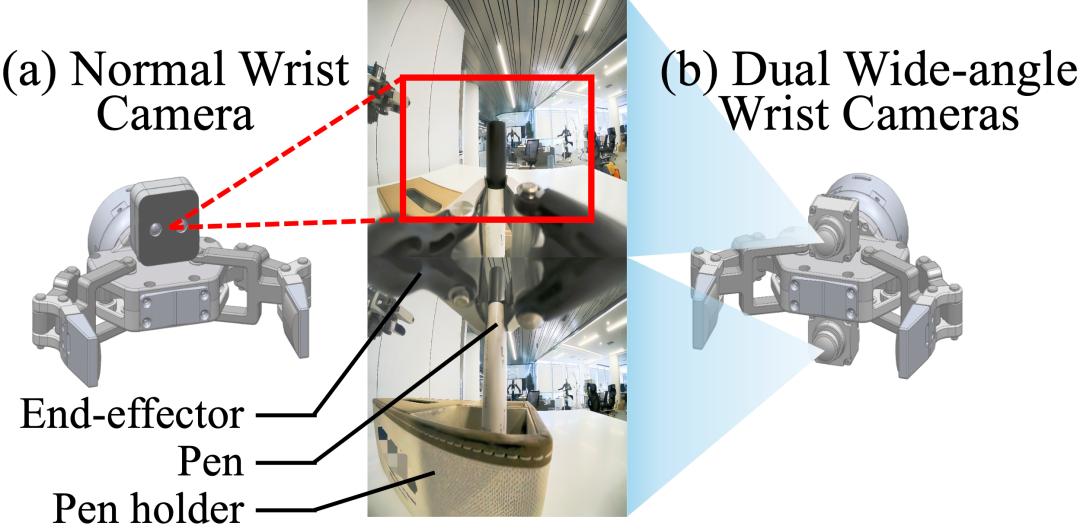
2. 完整的任務觀察:在常見的輸入狀態的做法中 , 狀態輸入可以給策略提供大致的任務信息 , 例如到達某一個狀態后模型就知道還需要大致運動多少就能夠到達目標位置 , 而不需要關注圖像輸入中復雜的環境 。 為了提高策略的泛化性 , State-free Policy 移除了狀態輸入 , 因此任務中所有的物體信息必須全部由視覺輸入提供 , 這促使我們為機器人的末端執行器配備更廣闊的視野 。 本文中的相機系統由位于機器人頭頂的主攝和腕部相機構成 。 如上圖所示 , 在常規設定下 , 末端執行器上方會安裝一個常規相機 。 而在雙目廣角設定下 , 研究者在末端執行器上方和下方都安裝了一個廣角相機 , 來提供更廣泛的視野和末端執行下方的視野 。 不過需要注意的是 , 這種設定是為了即使在最復雜的環境下也能獲得完整的任務觀察 , 有時在簡單的環境中常規的設定也可以滿足完整的任務觀察需求 。
真機實驗結果
為了驗證 State-free Policy 的空間泛化能力 , 研究人員進行了廣泛的實驗 , 尤其是在真機任務中 。 這些實驗涵蓋了不同的任務 , 包括簡單的拾取放置任務、困難的疊衣服任務以及使用全身機器人在冰箱中拿取飲料的任務 。 這些任務的數據是有著嚴格的收集標準 , 即數據中物體的擺放均收到嚴格控制 , 例如在夾筆放入筆筒的任務中 , 桌面高度嚴格不變 , 且筆筒的位置也嚴格不變 。 這樣的設定是保證空間泛化能力來自于模型本身 , 而不是泛化的數據 。 此外 , 研究人員發現除了更好的空間泛化能力之外 , State-free Policy 還具備包括更高的數據應用效率以及更快的跨本體泛化的優點 。 在此基礎上 , 研究人員還有一個有趣的發現 , 那就是移除頂端的主攝可以進一步提高空間泛化能力:
如上圖所示 , 在簡單的拾取放置任務中 , 相比于有狀態輸入的策略 , State-free Policy 擁有顯著更強的空間泛化能力 , 包括高度和水平泛化能力 。 例如 , 在夾筆放入筆筒的任務中 , 高度泛化的測試成功率從 0 提升到了 0.98 , 水平泛化的測試成功率從 0 提升到了 0.58;而相比于常規的相機設定 , 具有完整任務觀察的設定使高度泛化的測試成功率從 0.87 提升到了 0.98 , 水平泛化的測試成功率從 0.27 提升到了 0.58 。
與此同時 , 在一些更困難的任務中 , 例如疊衣服 , 以及利用全身機器人從冰箱里取飲料(由于硬件限制 , 只進行了常規相機下的水平泛化能力測試) , State-free Policy 的水平泛化能力明顯超過了帶有狀態輸入的模型 。 以上實驗證明了 State-free Policy 具有顯著更強的空間泛化能力 , 能在數據多樣性受限的情況下獲得強大的空間泛化能力 。
State-free Policy 的額外優勢
除了更強的空間泛化能力之外 , State-free Policy 還展現出更高的數據利用效率 。 相比之下 , 基于狀態的策略往往需要大量多樣化的示范數據來避免過擬合特定軌跡 , 從而增加了數據收集成本 。 而 State-free Policy 不易陷入這一問題 , 即使在數據有限的情況下也能保持良好表現 。 研究人員在夾筆任務中進一步驗證了這一點:在不同規模的數據下(300、200、100、50 條演示數據) , 隨著數據量減少 , 基于狀態的策略迅速過擬合并導致性能下降 , 而 State-free Policy 則始終保持更高的成功率 。
另外 , State-free Policy 在跨本體微調中也展現出優勢 。 相比依賴狀態輸入的策略需要重新對齊狀態空間 , State-free Policy 只需在相似相機配置下適應輕微的圖像偏移 , 因此能更高效地完成跨平臺遷移 。 在疊衣服任務中 , 研究人員先在雙臂 Arx5 上訓練 , 再將其適配到人形雙臂機器人 , 并用 100 條演示數據進行微調 。 上表的結果表明 , State-free Policy 收斂更快 , 成功率更高 , 驗證了其更強的跨平臺適應能力 。
在移除限制空間泛化的狀態輸入后 , 研究人員進一步思考是否還存在其他潛在瓶頸 , 并指出頂置相機可能同樣帶來問題 。 由于物體位置變化會導致頂視角下的圖像分布發生偏移 , 在極端情況下(如桌面升至 100 cm)甚至會嚴重影響性能;而腕部相機則可隨末端執行器移動 , 始終獲得與訓練時一致的相對視角 。 鑒于雙廣角腕部相機已能覆蓋完整任務觀察 , 頂置相機不僅多余 , 甚至可能帶來負面影響 。 為驗證這一點 , 研究人員在夾筆放入筆筒任務中設計了三種更具挑戰性的情景:桌面升至 100 cm、筆筒加高一倍 , 以及筆筒在水平方向移動 20 cm 。
上表的結果顯示 , 帶有頂置相機的 State-free Policy 在這三種情景下表現均不理想 , 而僅使用雙廣角腕部相機的策略則始終保持較高成功率 。 這一發現提示我們 , 有必要重新審視傳感器設計 , 未來或許應考慮去除頂置相機 。
總結
在本研究中 , 研究人員提出了 State-free Policy , 并基于兩個條件加以實現:相對末端執行器動作空間 , 以及通過足夠全面的視覺信息獲取完整的任務觀察 。 在不依賴狀態輸入的情況下 , 該策略不僅能夠保持完美的域內性能 , 還在空間泛化方面取得了顯著提升 。 同時 , State-free Policy 有效降低了對昂貴真實數據的需求 , 支持更高效的跨平臺適應 , 并為未來的傳感器設計提供了新的思路 , 為構建更具泛化能力的機器人學習系統提供了新的啟示 。
推薦閱讀














- LightVLA可微分token剪枝,首次實現VLA模型性能和效率的雙重突破
- 蘋果傳統強項再發力,視覺領域三種模態終于統一
- 智能頭戴設備AiSee為視障人士提供全新\視覺\體驗
- 諾獎得主、谷歌AI掌門人潑冷水:所謂“博士級智能”純屬無稽之談
- 具身VLA后訓練:TeleAI提出潛空間引導的VLA跨本體泛化方法
- 基于3DGS場景理解和視覺語言預訓練,讓3D高斯「聽懂人話」的一躍
- 8800+內存純白次元主板進化!ROG X870吹雪S超詳測評
- SuperCLUE多模態視覺評測榜出爐:文心4.5 Turbo并列國內第一!
- 對話優理奇CEO楊豐瑜:00后創業不押注VLA,把機器人先送進酒店干活
- 曝REDMI K90系列上2K LTPS純直屏、全員潛望鏡