
文章圖片

文章圖片
文章圖片
前不久 , 華為創始人任正非接受《人民日報》采訪時為中國芯片指路——芯片問題其實沒必要擔心 , 用疊加和集群等方法 , 計算結果上與最先進水平是相當的 。
他坦言 , 我們單芯片還是落后美國一代 , 我們用數學補物理、非摩爾補摩爾 , 用群計算補單芯片 , 在結果上也能達到實用狀況 。
任正非認為 , 中國在中低端芯片上是可以有機會的 , 中國數十、上百家芯片公司都很努力 。 特別是化合物半導體機會更大 。 硅基芯片 , 我們用數學補物理、非摩爾補摩爾 , 利用集群計算的原理 , 可以達到滿足我們現在的需求 。
那華為是怎么做的呢?
日前 , 華為云官微通過一段視頻展示了CloudMatrix 384超節點算力集群的威力——
384顆昇騰NPU(昇騰910C)+192顆鯤鵬CPU全對等互聯 , 形成一臺“超級AI服務器”;
業界最大單卡推理吞吐量——2300Tokens/s;
業界最大集群算力——16萬卡 , 萬卡線性度高達95%;
云上確定性運維-40天長穩訓練、10分鐘快速恢復 。
華為云表示 , 新一代昇騰AI云服務 , 是最適合大模型應用的算力服務 。
此前 , 華為還發布了一一篇60頁的重磅論文 , 提出了他們的下一代AI數據中心架構設計構想——Huawei CloudMatrix , 以及該構想的第一代產品化的實現CloudMatrix384 。
簡單來說 , 華為CloudMatrix并非簡單的“堆卡” , 而是通過高帶寬全對等互聯(Peer-to-Peer)來設計 , 這也是CloudMatrix 384硬件架構的一大創新 。
傳統的AI集群中 , CPU相當于公司領導的角色 , NPU等其它硬件更像是下屬 , 數據傳輸的過程中就需要CPU審批和簽字 , 效率就會大打折扣 。
【性能超NV!華為芯片集群殺招公布:384顆NPU+192顆CPU互聯無敵】但在CloudMatrix384中 , CPU和NPU等硬件更像是一個扁平化管理的團隊 , 它們之間的地位比較平等 , 直接通過UB網絡通信直接對話 , 效率自然就上來了 。
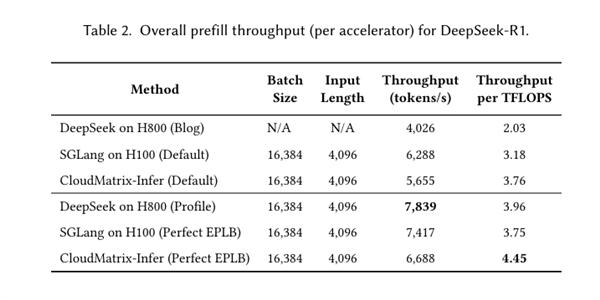
另外 , 論文還介紹了基于CloudMatrix384進行DeepSeek推理的最佳實踐方案——CloudMatrix-Infer 。
從官方給出的案例來看 , CloudMatrix384預填充吞吐量達6688 token/s/NPU , 解碼階段1943 token/s/NPU;計算效率方面 , 預填充達4.45 token/s/TFLOPS , 解碼階段1.29 token/s/TFLOPS , 均超過NVIDIA H100/H800上實現的性能 。
推薦閱讀














- 華為“最香”512GB手機,價格降2235元,中端價格撿漏旗艦體驗
- 華為3款新品太驚喜,eSIM+衛星通信,Mate mini平板或成最大驚喜
- 1000億收購獲批,華為面臨更大競爭!
- 華為又開源了個大的:超大規模MoE推理秘籍
- 36氪首發 | 從快手獨立的AI芯片公司融資數億元,視頻壓縮性能超英偉達
- 榮耀Magic V Flip 2再曝光:折痕優化+超大電池
- 疑似OPPO Find X9標準版參數細節曝光:性能屏幕續航影像全面升級
- 華為流程體系拆解系列:L1-L6分層拆解邏輯
- 華為入選《時代周刊》全球100影響力企業:自主研發支撐品牌韌性
- 首屆魔搭開發者大會舉辦,已服務全球超1600萬開發者