
文章圖片
文章圖片

文章圖片

文章圖片

文章圖片
劉勇 , 中國人民大學 , 長聘副教授 , 博士生導師 , 國家級高層次青年人才 。 長期從事機器學習基礎理論研究 , 共發表論文 100 余篇 , 其中以第一作者/通訊作者發表頂級期刊和會議論文近 50 篇 , 涵蓋機器學習領域頂級期刊 JMLR、IEEE TPAMI、Artificial Intelligence 和頂級會議 ICML、NeurIPS 等 。
【大模型的「aha moment」不是裝腔作勢,內部信息量暴增數倍!】你肯定見過大模型在解題時「裝模作樣」地輸出:「Hmm…」、「Wait let me think」、「Therefore…」這些看似「人類化」的思考詞 。
但一個靈魂拷問始終存在:這些詞真的代表模型在「思考」 , 還是僅僅為了「表演」更像人類而添加的語言裝飾?是模型的「頓悟時刻」 , 還是純粹的「煙霧彈」?
現在 , 實錘來了!來自中國人民大學高瓴人工智能學院、上海人工智能實驗室、倫敦大學學院(UCL)和大連理工大學的聯合研究團隊 , 在最新論文中首次利用信息論這把「手術刀」 , 精準解剖了大模型內部的推理動態 , 給出了令人信服的答案:
當這些「思考詞」出現的瞬間 , 模型大腦(隱空間)中關于正確答案的信息量 , 會突然飆升數倍!
這絕非偶然裝飾 , 而是真正的「信息高峰」與「決策拐點」!更酷的是 , 基于這一發現 , 研究者提出了無需額外訓練就能顯著提升模型推理性能的簡單方法 , 代碼已開源!
- 論文題目:Demystifying Reasoning Dynamics with Mutual Information: Thinking Tokens are Information Peaks in LLM Reasoning
- 論文鏈接:https://arxiv.org/abs/2506.02867
- 代碼鏈接:https://github.com/ChnQ/MI-Peaks
核心發現一:揭秘大模型推理軌跡中的「信息高峰」現象
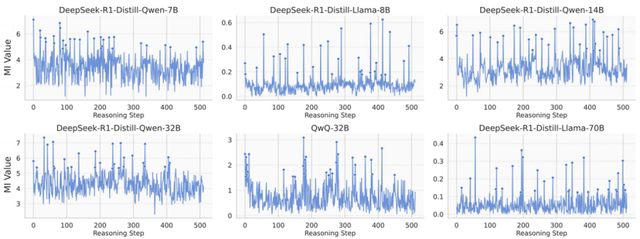
研究者們追蹤了像 DeepSeek-R1 系列蒸餾模型、QwQ 這類擅長推理的大模型在解題時的「腦電波」(隱空間表征) 。 他們測量每一步的「腦電波」與最終正確答案的互信息(Mutual Information MI) , 并觀察這些互信息如何演繹變化 。
驚人現象出現了:模型推理并非勻速「爬坡」 , 而是存在劇烈的「信息脈沖」!在特定步驟 , 互信息值會突然、顯著地飆升 , 形成顯著的「互信息峰值」(MI Peaks)現象 。 這些峰值點稀疏但關鍵 , 如同黑暗推理路徑上突然點亮的強光路標!
這意味著什么?直覺上 , 這些互信息峰值點處的表征 , 模型大腦中那一刻的狀態 , 蘊含了更多指向正確答案的最關鍵信息!
進一步地 , 研究者通過理論分析證明(定理 1 & 2) , 推理過程中積累的互信息越高 , 模型最終回答錯誤概率的上界和下界就越緊 , 換言之 , 回答正確的概率就越高!
既然互信息峰值的現象較為普遍地出現在推理模型(LRMs)中 , 那么非推理模型(non-reasoning LLMs)上也會表現出類似的現象嗎?
為了探索這一問題 , 研究者選取了 DeepSeek-R1-Distill 系列模型和其對應的非推理模型進行實驗 。 如上圖橙色線所示 , 在非推理模型的推理過程中 , 互信息往往表現出更小的波動 , 體現出明顯更弱的互信息峰值現象 , 且互信息的數值整體上更小 。
這表明在經過推理能力強化訓練后 , 推理模型一方面似乎整體在表征中編碼了更多關于正確答案的信息 , 另一方面催生了互信息峰值現象的出現!
核心發現二:「思考詞匯」=「信息高峰」的語言化身
那么 , 這些互信息峰值點處的表征 , 到底蘊含著怎樣的語義信息?
神奇的是 , 當研究者把這些「信息高峰」時刻的「腦電波」翻譯回人能看懂的語言(解碼到詞匯空間)時 , 發現它們最常對應的 , 恰恰是那些標志性的「思考詞」:
- 反思/停頓型:「Hmm」、「Wait」…
- 邏輯/過渡型:「Therefore」、「So」…
- 行動型:「Let」、「First」…
例如 , 研究者隨機摘取了一些模型輸出: 「Wait let me think differently. Let’s denote...」 「Hmm so I must have made a mistake somewhere. Let me double-check my calculations. First ...」
研究團隊將這些在互信息峰值點頻繁出現、承載關鍵信息并在語言上推動模型思考的詞匯命名為「思考詞匯」(thinking tokens) 。 它們不是可有可無的裝飾 , 而是信息高峰在語言層面的「顯靈」 , 可能在模型推理路徑上扮演著關鍵路標或決策點的角色!
為了證明這些 tokens 的關鍵性 , 研究者進行了干預實驗 , 即在模型推理時抑制這些思考詞匯的生成 。
實錘驗證:實驗結果顯示 , 抑制思考詞匯的生成會顯著影響模型在數學推理數據集(如 GSM8K、MATH、AIME24)上的性能;相比之下 , 隨機屏蔽相同數量的其他普通詞匯 , 對性能影響甚微 。 這表明這些存在于互信息峰值點處的思考詞匯 , 確實對模型有效推理具有至關重要的作用!
啟發應用:無需訓練 , 巧用「信息高峰」提升推理性能
理解了「信息高峰」和「思考詞匯」的奧秘 , 研究者提出了兩種無需額外訓練即可提升現有 LRMs 推理性能的實用方法 。
應用一:表征循環(Representation Recycling - RR)
- 啟發:既然 MI 峰值點的表征蘊含豐富信息 , 何不讓模型「多咀嚼消化」一下?
- 方法:在模型推理過程中 , 當檢測到生成了思考詞匯時 , 不急于讓其立刻輸出 , 而是將其對應的表征重新輸入到模型中進行額外一輪計算 , 讓模型充分挖掘利用表征中的豐富信息 。
- 效果:在多個數學推理基準(GSM8K、MATH500、AIME24)上 , RR 方法一致地提升了 LRMs 的推理性能 。 例如 , 在極具挑戰性的 AIME24 上 , DeepSeek-R1-Distill-LLaMA-8B 的準確率相對提升了 20%!這表明讓模型更充分地利用這些高信息量的「頓悟」表征 , 能有效解鎖其推理潛力 。
應用二:基于思考詞匯的測試時擴展(Thinking Token based Test-time Scaling - TTTS)
- 啟發:在推理時如果允許模型生成更多 token(增加計算預算) , 如何引導模型進行更有效的「深度思考」 , 而不是漫無目的地延伸?
- 方法:受啟發于前人工作 , 作者在模型完成初始推理輸出后 , 如果還有 token 預算 , 則強制模型以「思考詞匯」開頭(如「Therefore」、「So」、「Wait」、「Hmm」等)繼續生成后續內容 , 引導模型在額外計算資源下進行更深入的推理 。
- 效果:當 token 預算增加時 , TTTS 能持續穩定地提升模型的推理性能 。 如圖所示 , 在 GSM8K 和 MATH500 數據集上 , 在相同的 Token 預算下 , TTTS 持續優于原始模型 。 在 AIME24 數據集上 , 盡管原始模型的性能在早期提升得較快 , 但當 token 預算達到 4096 后 , 模型性能就到達了瓶頸期;而 TTTS 引導下的模型 , 其性能隨著 Token 預算的增加而持續提升 , 并在預算達到 6144 后超越了原始模型 。
小結
這項研究首次揭示了 LRMs 推理過程中的動態機制:通過互信息動態追蹤 , 首次清晰觀測到 LRMs 推理過程中的互信息峰值(MI Peaks)現象 , 為理解模型「黑箱」推理提供了創新視角和實證基礎 。
進一步地 , 研究者發現這些互信息峰值處的 token 對應的是表達思考、反思等的「思考詞匯」(Thinking Tokens) , 并通過干預實驗驗證了這些 token 對模型推理性能具有至關重要的影響 。
最后 , 受啟發于對上述現象的理解和分析 , 研究者提出了兩種簡單有效且無需訓練的方法來提升 LRMs 的推理性能 , 即表征循環(Representation Recycling - RR)和基于思考詞匯的測試時擴展(Thinking Token based Test-time Scaling - TTTS) 。
研究者希望這篇工作可以為深入理解 LRMs 的推理機制提供新的視角 , 并進一步提出可行的方案來進一步推升模型的推理能力 。
推薦閱讀













- 美的樓宇科技:以創新技術引領工業熱泵發展,助力節能降碳
- 雷軍怒贊的千億生意,被這個理工男“截胡”了
- 推理AI致命弱點,大模型變「杠精」,被帶偏后死不悔改
- 旗艦與性價比,最強組合拳!小米徹底覺醒,熱銷是注定的
- 5150mAh+1TB,去年最好看的直屏手機殺回來了
- 華為商城今天上架的新機,這價格把我整不會了
- 當你焦慮于AI的時候,回頭看看中臺
- 小米這次1999的「新品」,把所有網友都整不會了
- 小屏手機熱度散了?小米、vivo、一加三款小屏盤點,哪個是你的菜
- 599元!小米剛剛上架的新品,真的太香了